Possible increased unused disk space when running SCOM 2016 on SQL2016
DISCLAIMER:
This post is not an official Microsoft post. It is based on current knowledge on a best effort base and contains some information that might be changed or updated in the future. Purpose of this post is to get feedback from customer who notice the described behavior and to give guidance on how to handle it.
Update 02.08.2017: In the meantime we found the root cause. I updated this post and marked the updated parts in red.
Update 04.08.2017: In the meantime Kevin has re-written his excellenct SQL maintenance post for SCOM that covers the issue of this post very well: https://blogs.technet.microsoft.com/kevinholman/2017/08/03/what-sql-maintenance-should-i-perform-on-my-scom-2016-databases/
Finding
Last week I was at a customer site and noticed, that a new SCOM 2016 environment with ~600 Agents and 24 GB of OpsMgrDB space completely filled up and had no unallocated space left! At first, I thought about some kind of alert/data storm, but that was not the case. Instead we saw a high amount of unused space:
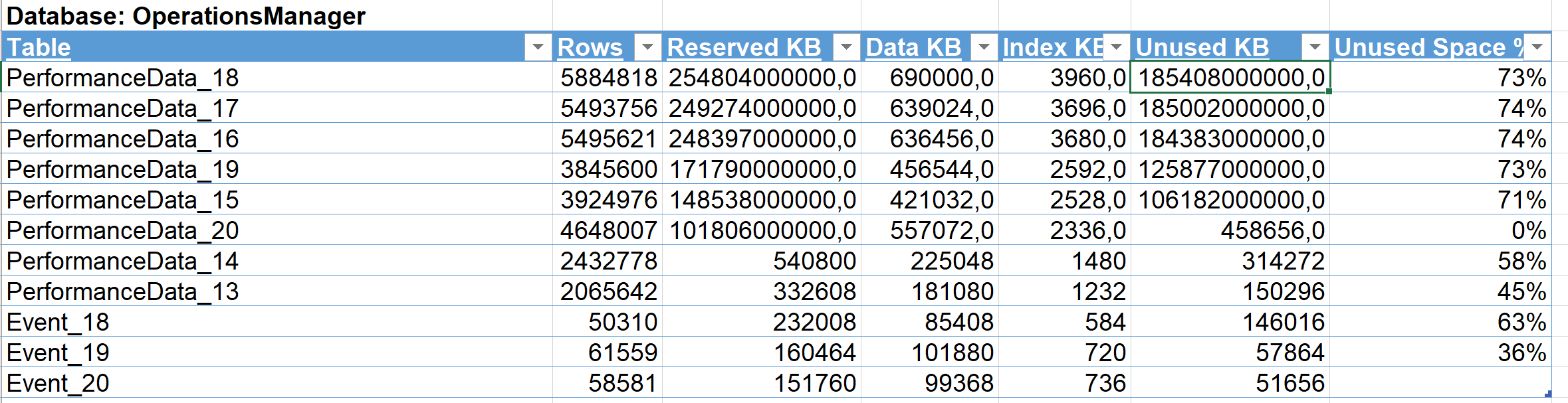
We saw up to 74% of unused space for certain tables.
After a little research, we quickly found other users also noticed this kind of behavior:
https://social.technet.microsoft.com/Forums/en-US/39f11059-9d0b-415d-a5c5-8a964a72af3f/operationasmanager-database-has-high-value-of-unused-space?forum=operationsmanagergeneral
And the SQL disk usage report from Adrian Chirtoc on the forum (that looked almost the same like the one from my customer) looked like this:
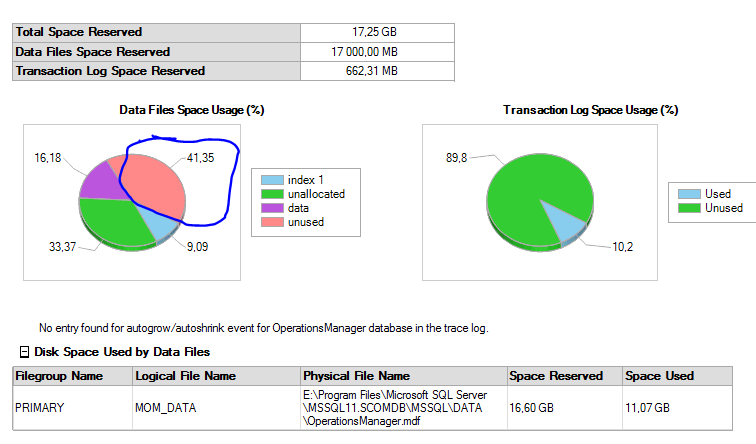
Other fellow PFE’s around the world have also noticed a similar behavior.
Reproduction
With the great help and support of my fellow SQL PFE colleagues we could finally reproduce this behavior in our labs.
Brief background for non DBA's
SCOM uses BULK INSERT to insert e.g. Performance and Event data into SQL. SQL 2016 has changed its default way on how pages get allocated (to increase SQL performance). Combined with the way how SCOM sends data to the database it can cause SQL2016 to reserve way more unallocated space than in past SQL versions.
In SQL 2016 we turned on bulk load context (aka fast inserts) and minimal logging. These enhancements in combination with small batch sizes can lead to our situation with high reserved space (that describes the findings of the next paragraph). You can find an excellent explanation of this behavior in the blog post from Parikshit Savjani here.
This behavior depends heavily on the amount of records inserted per bulk insert. If only a few records get inserted, you will most probably not see any increased amount of unused space. If you insert more data (e.g. 100-500) records in bulk, you will immediately see a high amount of unused space for this particular table.
Running the same import with the same amount of data into the same table in SQL2012 or SQL2014 does not produce any noticeable amount of unused space.
What does that mean for my SCOM environment?
So from what I currently know:
Is my environment affected by this?
I guess it is safe to say: every SCOM 2016 environment running on SQL 2016 is affected from this changed way of space allocation in some kind of way!
SCOM 2016 running on SQL2012 and SQL2014 with default settings is NOT affected!
How does it affect my environment?
The changed process of page allocation has NO negative performance effect on your environment!
Only high-volume data tables (meaning tables with a lot of bulk inserts) like Performance and Event data and probably StateChange data are affected, due to their nature of usage. More static tables are most likely unaffected. The affected tables can grow significantly (due to high unallocated and unused space) and increase the overall space usage of your OpsMgr database.
The grade of affection, meaning, if you notice a significant amount of unallocated (unused) space on the above-mentioned tables depends highly on the size and usage of your SCOM environment. E.g. in my Lab environment with only 5 Agents I could not see any effect, but in bigger environments of 100+ Agents it is immediately noticeable.
And the grade of affection also depends on your retention times. So e.g. for my customer (using the default 7 day retention) it meant, that each of the 7 PerfData tables in use grew by an additional average of 1,5 GB = ~10 GB more space usage that needs to be available. After the 8th day the oldest tables get truncated by the SCOM grooming process, so the database will not grow to infinity.
Do I need to do something?
Well, it depends. Now that you know this effect, you can closely monitor your database (by looking at the Disk Usage reports of SQL) and size it appropriately. Unfortunately, due to the nature of SCOM and its behavior in different environments (size, MPs etc.) it is hard to give an exact recommendation on how to adapt your sizing.
But, what if you do not have enough space or do not want to extend the disk space used by the OpsMgr DB?
You can run a nightly index rebuild on all (or only the Perf/Event data) SCOM tables. This rebuild will free up (almost) all unused space and is also a general good practice for SCOM Maintenance.
So, with a nightly index rebuild and a default retention of 7 days you will see only a high amount of unused space on the tables used for the current day. For the past days, the data tables will have the same size as they had in SQL2012/2014.
If you want to rebuild the indexes you can either create and schedule a custom SQL script or use Olla Hallengrens great SQL Maintenance solution (https://ola.hallengren.com/).
PLEASE NOTE:
Run the index rebuild at times outside the default SCOM nightly Maintenace, which is at 2:30 AM per default.
As Parikshit explains, there is also the option of using trace flag 692 (which is described here) to disable the fast insert behavior.
But we do not recommend to enable Trace Flag 692. The better option would be to use index rebuild instead. Only if index rebuild is not an option, you should proceed using this Trace Flag.
Feedback request
I am curious to know if you are affected or see different behaviors in your SCOM2016 environment on SQL 2016. Please leave a comment.
Credits
This post would not have been possible without the great help and feedback from several people:
- Customer side: Bruno and Christian, thanks’ for your support!
- German SQL PFE: Cornel Sukalla and Oliver Hahn
- Fellow SCOM PFE: Uwe Stürtz and Kevin Holman
- Parikshit Savjani from our SQL Server Tiger team
Comments
- Anonymous
July 07, 2017
The comment has been removed- Anonymous
July 07, 2017
Thanks' Adrian. If there is an update regarding this topic one of us will update this post to let you guys know.Dirk
- Anonymous
- Anonymous
July 10, 2017
Vielen Dank Dirk :-)!I can reproduce it so far within my DEV environment with 130 agents for SCOM 2016 and SQL 2016 (38%). A MgmtGroup with the same amount of agents (multihoming) with SCOM 2012 R2 and SQL 2012 does not show effects of unused space in this way (~1%).So far I thought SCOM has inbuilt DB maintenance but reindexing will now be implemented in all stages. Viele GrüßeKonstantin- Anonymous
July 10, 2017
Built-in OpsMgr Maintenance (p_Optimize) does not re-build the index of Perf- and Event-Data tables. Therefore my suggestion for Olla's solution.RegardsDirk
- Anonymous
- Anonymous
July 19, 2017
Propposed Solution Works!Greeting From Jan ! - Anonymous
July 24, 2017
Yes, I also see this behaviour and runs a nightly rebuild of index as a workaround. /Lars