End-to-End Data Processing using Azure Data Factory (Overview)
By Rakesh Davanum, Senior Consultant
Overview
This blog post is intended to give an overview of orchestrating end-to-end solutions using Azure Data Factory. Azure Data Factory is a cloud-based data integration service that orchestrates and automates the movement and transformation of data. An introduction and overview of Azure Data Factory can be found here. Details on individual activities and sample code in the Azure Data Factory pipeline will follow in subsequent posts.
One of the most common use cases in analytics is to get data from a source, process and transform it to a more usable format, query the transformed data and gain insights from it (represented in the form of dashboards) and make intelligent decisions to improve the business. The solutions for these generally involve interaction between data sources, processing/computational engines, data repositories and visualization tools. They also need to have some kind of workflow management system to orchestrate the overall flow. This post gives an overview of a solution for doing this which can be applied for solving similar problems.
For one of my recent engagements I had the opportunity to work with Azure Data Factory for orchestrating the end-to-end flow starting from reading the raw input data to generating the data to feed the dashboards. This implementation had interaction between various Azure services like Data Factory, Blob Storage, HDInsight & SQL Data Warehouse. The scope of the project started from reading the raw data in Blob Storage till creating the PowerBI dashboards to gain insights from the data.
The raw data was captured by the customer from multiple data sources and provided to us on Blob Storage as zip file for each data source. This zip file included data/logs for all datasets from that data source in XML format which we call the raw data. The raw data was quite complex and was not straight forward to analyze as is. It had to be transformed from the complex XML format to a much simpler format to make analysis and joining datasets easier.
Architecture
Given below is the architecture diagram for this implementation.
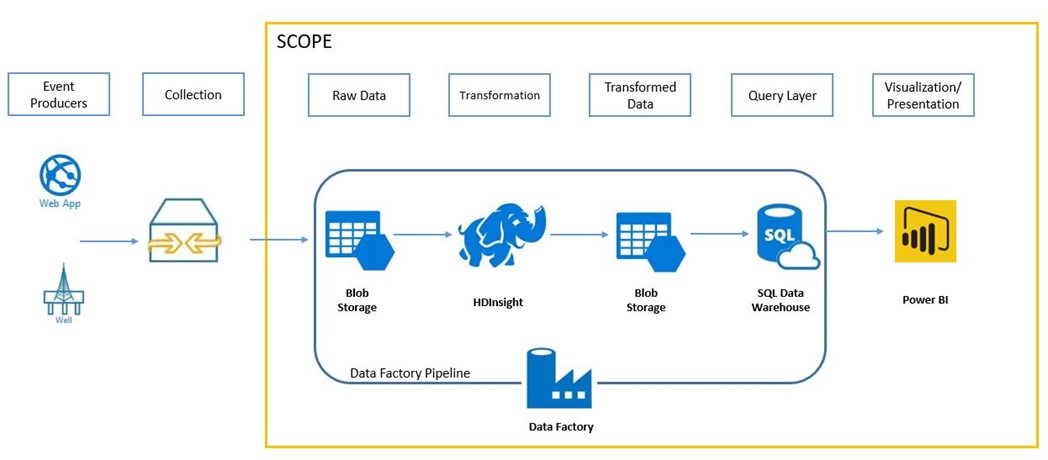
The steps in this implementation at a high level are:
- Read input zip files
- Extract zip files
- Transform XML files to CSV format
- Load transformed data to SQL Data Warehouse tables
- Execute stored procedures to generate aggregate data
- Build dashboards on top of aggregated data
Azure Blob Storage
It is important to organize the data on Blob Storage properly during each phase of the process. This ensures that processed data is kept separate from unprocessed or in-process data. We also had all the processed data from all the runs in one location in Blob Storage. This gave us the ability to create a Hive layer on top of all the processed data and run Hive queries using HDInsight cluster. Given below is the structure on how the data was organized on Blob Storage showing the containers/folders used.
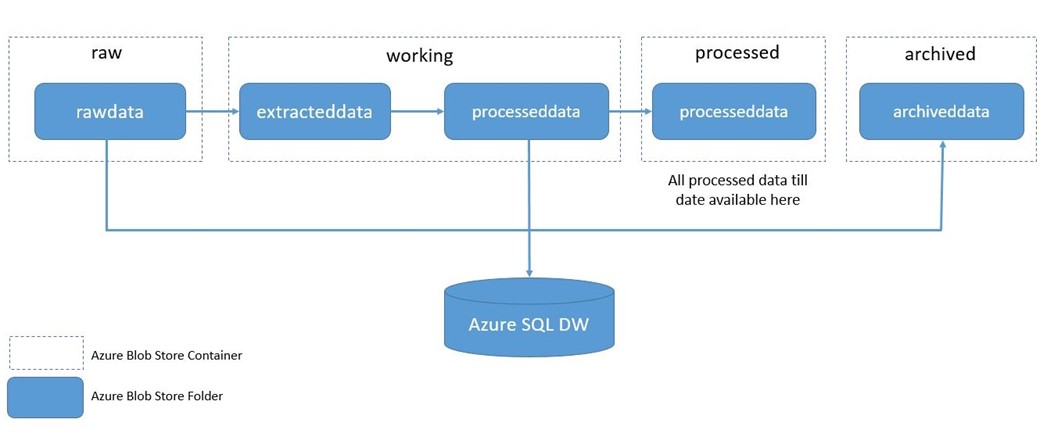
- Container=raw
- Folder=rawdata: Landing place for any new zip files. Any new zip file that has to be processed should be uploaded to this location before triggering the Data Factory pipeline.
- Container=working
- Folder=extracteddata: Location where the contents of the zip files (in the current run of the pipeline) will be extracted to.
- Folder=processeddata: Location where the output of the transformation of XML files to CSV files (in the current run of the pipeline) will be stored.
- Container=processed
- Folder=processeddata: Location where the generated CSV files for all transformed XML files (of all the runs i.e., of all processed zip files) will be stored. Hive external tables can be created to point to this location (sub-folders) so that hive queries can be run on the data.
- Container=archived
- Folder=archiveddata: Location where the input zip file will be moved to after the processing is complete. This location will have all the processed zip files.
The above directory structure/concept can be applied in other transformation scenarios as well. When a single folder is used for providing input files (without organizing the input folder further into date-time folders), Azure Data Factory does not keep track of which input files have been processed and which have not been processed. So it is required to ensure that all processed zip files are removed/moved from the raw/rawdata folder before trying to process new set of files. If the raw/rawdata folder contains zip files that have already been processed and a new run of the pipeline is triggered, this will lead to duplicate records getting loaded to the SQL Data Warehouse tables.
Azure Data Factory
The types of Linked services used in the pipeline are:
- AzureStorage: To use the different Blob Storage datasets required.
- HDInisght: To point to the HDInsight cluster used as the compute resource for the pipeline
- AzureSqlDatabase: To point to the SQL Data Warehouse instance to load all the processed XML files to corresponding tables.
The Azure Data Factory end-to-end pipeline used in the implementation is given below:

The different activities used in the end-to-end pipeline along with their functionality are given below. These are some of the typical activities that you can use in the pipeline. The different types of transformational activities supported in Azure Data Factory can be found here.
- UnzipMRActivity: To extract the raw zip files to working/extracteddata. Developed as MapReduce activity.
- WITSMLParseActivity: To transform the XML files and generate the corresponding CSV files to working/processeddata. Developed as custom activity.
- DataLoadStoredProcedureActivity: To load all the generated CSV files into corresponding tables in Azure SQL Data Warehouse via Polybase. Developed as Stored Procedure activity.
- MoveProcessedFilesActivity: To move all the generated CSV files from working/processeddata to processed/processeddata. Developed as MapReduce activity.
- MoveRawFilesActivity: To move the processed zip file from raw/rawdata to archived/archiveddata. Developed as MapReduce activity.
- DeleteExtractedFilesActivity: To delete all the extracted data in working/extracteddata. Developed as MapReduce activity.
Azure SQL Data Warehouse
Azure SQL Data Warehouse is an enterprise-class distributed database capable of processing petabyte volumes of relational and non-relational data. It is the industry's first cloud data warehouse with grow, shrink, and pause in seconds with proven SQL capabilities. It also supports integration with visualization tools like PowerBI. So we chose to use Azure SQL Data Warehouse for storing all the transformed data. More information on Azure SQL Data Warehouse can be found here. Once the transformation was done, next step was to load all the transformed data present in Blob Storage to SQL Data Warehouse tables. This was achieved using PolyBase. PolyBase allows us to use T-SQL statements to access data stored in Hadoop or Azure Blob Storage and query it in an adhoc fashion. It also lets us query semi-structured data and join the results with relational data sets stored in SQL Data Warehouse. An overview of PolyBase can be found here. We were able to create external tables pointing to data in Blob Storage. Then using a simple stored procedure we were able select all the data in the external table and load them into the corresponding tables in SQL Data Warehouse. Once all the transformed data was loaded into the corresponding tables, we wrote stored procedures to generate the data for aggregation tables which was used to feed the PowerBI dashboards.
HDInsight, Data Factory and SQL Data Warehouse are all part of Cortana Analytics Suite providing Hadoop, data orchestration and elastic data warehouse capabilities.
Comments
- Anonymous
March 28, 2017
Have you released the sample code yet?