Defining Complex Server "Health" Policies in SQL 2008
Policy Based Management (PBM) is a new feature in SQL Server 2008 that allows you to define a set of policies that capture the intended state for a group of servers. For example, you could define a policy that says that your user databases should all have the auto update statistics database option enabled. (If you’re not yet familiar with PBM, you can read more about it in Books Online or in the PBM blog.)
In SQL 2008, the focus of PBM is primarily on static aspects of server management – policies covering things like schema requirements, or server and database configuration settings. However, there are certain more dynamic aspects of server state that are equally important, but much harder to monitor. Server “health” monitoring (e.g. uptime, responsiveness) is one example. I’m going to show you how you can use the ExecuteSql function to extend the normal capabilities of PBM by defining policies that ensure your servers are servicing queries effectively. You can use live Dynamic Management View (DMV) queries, or even query historical data that you are capturing in a Management Data Warehouse.
IMPORTANT: Before going on, read through this blog post for an overview of the PBM ExecuteSql function.
Suppose you wanted to define a policy like this one:
The average disk response time for all data and log files that have a non-trivial number of I/Os should not exceed 100ms.
You can use a query like this one to find files that violate this policy:
SELECT
CASE
WHEN MAX (avg_ms_per_io) > 100 THEN
'Excessive disk response time ('
+ CONVERT (varchar, MAX (avg_ms_per_io))
+ 'ms) for file ID ' + CONVERT (varchar, MAX (file_id))
+ ', database ' + MAX (database_name)
ELSE ''
END AS policy_violation_message
FROM
(
SELECT TOP 1
io_stall / (num_of_reads + num_of_writes) AS avg_ms_per_io,
io_stall AS io_stall_ms,
(num_of_reads + num_of_writes) AS num_io,
DB_NAME (database_id) AS database_name,
file_id
-- Only check I/O stats for the current database
FROM sys.dm_io_virtual_file_stats (DB_ID(), null)
WHERE
-- Ignore idle databases and files; we do not care about disk
-- wait time if the file has barely seen any I/O.
(num_of_reads + num_of_writes) > 500
-- PBM will use the first column of the first row to evaluate policy
-- compliance, so return the file with the longest avg I/O time.
ORDER BY 1 DESC
) AS slowest_file;
We’re going to wrap this query in PBM’s ExecuteSql() function, which will allow us to reference it within a policy condition. To permit PBM to bubble up more actionable info to the user (other than the simple fact that a database is out of policy), I’ve written the query to provide a string-type policy compliance indicator rather than a simple numeric 0/1 value. If the query detects that a database is in policy, it returns an empty string for the [policy_violation_message] column. But if disk response time is found to be out of policy, the query returns a message identifying the offending file and its average disk response time. This message will be logged with the policy results, which can help during postmortem diagnosis.
1. Create a new policy (in Management Studio under Management\Policies, right-click the Policies folder and select New Policy). Name the policy “Disk Health”.
2. In the Check Condition drop-down listbox, select New condition…
3. Name the condition “Disk Response Time is Healthy”, and set the Facet drop-down listbox to Database.
4. Click the “…” button next to the Field textbox. In the Advanced Edit dialog, enter the text shown below, then click OK (this is the same query as above, except that single quotes have been escaped by doubling them).
ExecuteSql('String', '
DECLARE @max_allowed_ms_per_io int;
SET @max_allowed_ms_per_io = 100;
SELECT
CASE
WHEN MAX (avg_ms_per_io) > @max_allowed_ms_per_io THEN
''Excessive disk response time (''
+ CONVERT (varchar, MAX (avg_ms_per_io))
+ ''ms) for file ID '' + CONVERT (varchar, MAX (file_id))
+ '', database '' + MAX (database_name)
ELSE ''''
END AS policy_violation_message
FROM
(
SELECT TOP 1
io_stall / (num_of_reads + num_of_writes) AS avg_ms_per_io,
io_stall AS io_stall_ms,
(num_of_reads + num_of_writes) AS num_io,
DB_NAME (database_id) AS database_name,
file_id
-- Only check I/O stats for the current database
FROM sys.dm_io_virtual_file_stats (DB_ID(), null)
WHERE
-- Ignore idle databases and files; we do not care about disk
-- wait time if the file has barely seen any I/O.
(num_of_reads + num_of_writes) > 500
-- PBM will use the first column of the first row to evaluate policy
-- compliance, so return the file with the longest avg I/O time.
ORDER BY 1 DESC
) AS slowest_file;
')
5. Set the Operator to equals (=) and the Value to '' (Note: that’s two single quotes, not a double quote).
Your new policy should look like this. If it does, click OK twice to create the policy.
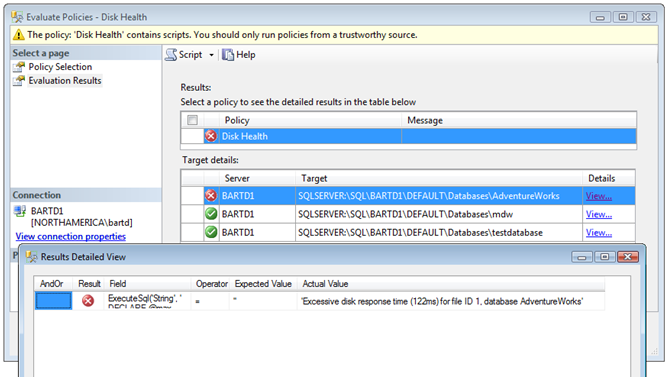
Now right-click on your policy and select Evaluate. Click the Evaluate button in the lower-right portion of the Evaluate Policies dialog, and acknowledge that you realize that the policy includes a custom script (see the blog post I referenced earlier for more information about the security implications of this approach). This will run the policy against each database on your instance, and will flag any that are suffering from poor disk response time. In the screenshot below, you can see that my [mdw] and [testdatabase] databases are in policy, but my [AdventureWorks] database is out of policy: the average I/O response time for file 1 in this database is an embarrassingly slow 122ms.
Because ExecuteSql takes an arbitrary query, you can define a policy that monitors literally any aspect of server health that you can write a query to detect. Below, for example, is a query that will trigger a policy violation if the value of the “SQLServer:Buffer Manager\Page Life Expectancy” perfmon counter drops too low:
ExecuteSql('String', '
SELECT
CASE
WHEN cntr_value < 300 THEN
''Page life expectancy (sec): ''
+ CONVERT (varchar, cntr_value)
ELSE ''''
END AS policy_violation_message
FROM sys.dm_os_performance_counters
WHERE counter_name = ''Page life expectancy'' AND object_name LIKE ''%Buffer Manager%'';
')
SQL Health Monitoring Policies and Management Data Warehouse
If you’ve spent much time trying to use SQL DMVs for server health monitoring in the past, you’ve probably run into situations where you needed to compare the live DMV data to an historical snapshot of the same data. For example, consider the “slow I/O” query at the top of this post. The I/O counters and disk “stall” time reported in sys.dm_os_virtual_file_stats are cumulative totals since the SQL instance was started. If the server had been running a long time, these values would be very large, and any disk performance problem would have to exist for a long time before the overall average I/O response time grew high enough to trigger the threshold. What you typically want in a case like this is to assess recent I/O performance, where “recent” means the average within the last several minutes or hours. Here's a more refined version of the policy we started with, that would make this type of monitoring more useful in the real world:
The average disk response time for all data and log files that have a non-trivial number of I/Os should not exceed 100ms (where "average disk response time" is defined as the average I/O wait time for all reads or writes to a file within the last 30 minutes)
This requires historical snapshots of the same data to compare the most recent data to. Luckily, this happens to be exactly what the Data Collector and Management Data Warehouse (MDW) features in SQL 2008 were intended to provide.
Being able to take advantage of historical data in your health monitoring policies has a number of advantages:
· For cumulative-since-server-startup DMV data, the policy will flag problems with less delay
· Similarly, a monitored object can go back “in policy” relatively quickly once the problem has been addressed
· For metrics that are instantaneous measurements, you get fewer false positive policy violations if you can average a set of recent measurements instead of focusing on a single instantaneous data point that might be an atypical value
The query below pulls recent disk stats from a local MDW database (this DMV’s data is collected by the built-in Server Activity collection set, so you don’t need to create a custom collection set). This assumes that (a) the monitored SQL instance is hosting its own MDW database, and (b) the MDW database’s name is “MDW”. If your MDW database is local but is named something other than "MDW", update the query text to reference the correct MDW database. (If you need a walkthough showing how to set up MDW, see this page.)
ExecuteSql('String', '
DECLARE @max_allowed_ms_per_io int;
DECLARE @time_window_min int;
SET @max_allowed_ms_per_io = 100;
SET @time_window_min = 120;
SELECT
CASE
WHEN MAX (recent_avg_ms_per_io) > @max_allowed_ms_per_io THEN
''Excessive disk response time (''
+ CONVERT (varchar, MAX (recent_avg_ms_per_io))
+ ''ms) for file ID '' + CONVERT (varchar, MAX (file_id))
+ '', database '' + MAX (database_name)
ELSE ''''
END AS policy_violation_message
FROM
(
SELECT TOP 1
(recent_io_stall_read_ms + recent_io_stall_write_ms)
/ (recent_read_count + recent_write_count + 1)
AS recent_avg_ms_per_io,
(recent_io_stall_read_ms + recent_io_stall_write_ms)
AS recent_io_stall_ms,
(recent_read_count + recent_write_count) AS recent_io_count,
database_name,
file_id
FROM
(
SELECT
database_name,
file_id,
MAX (io_stall_read_ms) - MIN (io_stall_read_ms)
AS recent_io_stall_read_ms,
MAX (io_stall_write_ms) - MIN (io_stall_write_ms)
AS recent_io_stall_write_ms,
MAX (num_of_reads) - MIN (num_of_reads) AS recent_read_count,
MAX (num_of_writes) - MIN (num_of_writes) AS recent_write_count
FROM mdw.snapshots.io_virtual_file_stats AS fs
INNER JOIN mdw.core.snapshots AS snap
ON fs.snapshot_id = snap.snapshot_id
WHERE
-- MDW data for the local instance only
snap.instance_name = @@SERVERNAME
-- I/O stats only for the current database
AND fs.database_id = DB_ID()
-- within the last 5 minutes
AND fs.collection_time >
DATEADD (minute, @time_window_min, SYSDATETIMEOFFSET())
GROUP BY database_name, file_id
) AS recent_io_stats
WHERE
-- Ignore idle databases and files; we do not care about disk
-- wait time if the file has barely seen any I/O.
(recent_read_count + recent_write_count) > 500
-- PBM will use the first column of the first row to evaluate policy
-- compliance, so return the file with the longest avg I/O time.
ORDER BY 1 DESC
) AS slowest_file;
')
I think this approach to server health monitoring could be useful, but it does have some limitations that are worth noting:
· This release of SQL doesn’t provide out-of-the-box policies of this sort. You have to write custom out-of-policy detection queries for any complex server health condition you want to monitor.
· Complex policies may have parameters that you might want to tweak on a per-server basis (in this example, the max allowed disk response time is one such parameter). Unfortunately, there is no facility for this in PBM in SQL 2008. If you really need this, you could create your own custom policy configuration table on each server with thresholds particular to that server, and join to this table in your custom condition query.
· When you use ExecuteSql, you can only choose “=” or “!=” for your operators. Because you can’t use inequality operators, you must push your policy violation thresholds down into the query itself.
If you’ve tried this approach to health monitoring and have experiences you can share, good or bad, let me know.
{kind=link}
Comments
Anonymous
September 11, 2008
PingBack from http://hoursfunnywallpaper.cn/?p=5781Anonymous
September 11, 2008
Bart Duncan (a dev on the manageability team and one of the masterminds behind the Management Data WarehouseAnonymous
November 16, 2008
Great example of useful functionality. I'll take a look and report back.Anonymous
January 29, 2009
Po przejściowych problemach ze startem w PBM rozwiązanych “ With a Little Help from My Friends ” - coAnonymous
March 08, 2009
hi.. this is very nice blog about using executesql function... When i m trying to write something like this to create a string conventions for my SP.... exec('string','select ''p_''+substring(db_name(),1,3)+''''') I m getting error like conditions referenced by automated policies can not contain scripts... I want all my SP to start with 'P_ADV' where ADV = Adventureworks... You can definately give me some hints here.. ThanksAnonymous
October 05, 2010
@cottage : for the above requirement u can use "stored procedure" facet , it has a property called @name give a regular expression equivalent to ur allowed naming conventionsAnonymous
March 03, 2011
Thanks Bart...That was very useful piece of work...