HDInsight Hive job workload
Typically, HIVE queries are developed using HIVE console or through interactive experiences like Ambari View or Hue. Post queries development at-least two steps to production
- Runtime Query generation: Query might need to be augmented with some runtime context. This can be achieved either by Hive variable substitution (parameterizing) or query generation in the application layer.
- Automate query execution: Hive queries can be triggered in many ways
- SSH terminal automation: SSH terminal automation for Hive script execution.
- Oozie scheduling: Hadoop clusters comes with Oozie component which can trigger Workflows/Actions based on either schedule or monitoring HDFS paths.
- Azure Data Factory: Azure data factory hive activity can trigger query execution.
- POCO: Program using HdInsight Jobs SDK
Mostly HIVE queries are part of a bigger ETL/data ingestion pipeline and full context influences the choice of selection. Between Oozie and ADF the cluster lifetime can be a big decision factor (If queries ran on on-demand clusters then ADF might be preferred).
SSH shell/Oozie hive action directly interact with YARN for HIVE execution where as POCO/ADF (Azure Data Factory) uses WebHCat REST interface to submit the jobs.
WebHCat interaction
In this blog post lets walk through how WebHCat interaction works. Below control flow diagram illustrates WebHCat interaction at a cluster level (assuming the current active head node is headnode0)
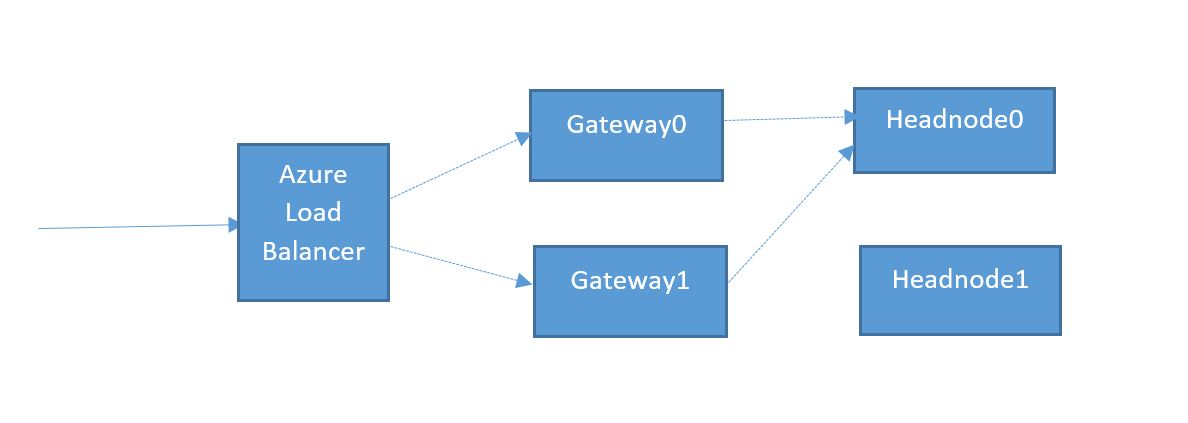
As we discussed in earlier posts Gateway nodes proxies all cluster calls. Gateway nodes are behind Azure load balance which can distribute the incoming calls to any of the Gateway nodes. Each gateway node routes the incoming request to current active headnode (which is maintained through Zookeeper). Headnodehost is a hostname alias which HDInsight maintains which resolved to the current active head node.
WebHCat Hive queries execution model
WebHCat is a REST interface for remote execution of workloads like Hive, Pig, Sqoop, MapReduce. WebHCat models the workload as jobs and execution them asynchronously. WebHCat only returns the execution details (status, progress etc...).
Typical hive job execution interaction with WebHCat will be like
- Submit hive job for execution. Returns id which can be used to get job status.
- Pool for job completion using job status API.
- Check the job result by reading job output
Let’s submit a simple hive query to WebHCat and check its status. Below CURL command submitting HIVE query
$ curl -u admin:{HTTP PASSWORD} -d execute="select market, count(*) from hivesampletable group by market" -d statusdir="firsttempletonjobstatusdir" https://{CLUSTER DNS NAME}.azurehdinsight.net/templeton/v1/hive?user.name=admin
{"id":"job_1461091727457_0007"}
$ curl -u admin: {HTTP PASSWORD} https://{CLUSTER DNS NAME}.azurehdinsight.net/templeton/v1/jobs/job_1461091727457_0007?user.name=admin
{
"status": {
"mapProgress": 1.0,
"reduceProgress": 1.0,
"cleanupProgress": 0.0,
"setupProgress": 0.0,
"startTime": 1461093683758,
"jobName": "TempletonControllerJob",
"finishTime": 1461093776297,
"jobID": {
"id": 4,
"jtIdentifier": "1461091727457"
},
"jobId": "job_1461091727457_0007",
"username": "admin",
"state": "SUCCEEDED",
...
},
"id": "job_1461091727457_0007",
"percentComplete": "100% complete",
"exitValue": 0,
"user": "admin",
"completed": "done",
"userargs": {
"statusdir": "firsttempletonjobstatusdir",
"execute": "select market, count(*) from hivesampletable group by market",
"user.name": "admin",
...
},
...
}
As we see job submission returned as Job ID (ex: job_1461091727457_0007) which is used later to get the job status. Resource Manager UI (a.k.a. YARN) shows below YANR jobs executed

We can notice here that we have an YARN application with the same suffix as job ID returned by WebHCat. Each job submitted to WebHCat results in a MapReduce job named “TempletonControllerJob” whose mapper launches another YARN job which does the real work.
WebHCat execution model scales well with the cluster resources as the job (or query) execution is delegated to a YARN application. But this also makes this path very heavy. Each job execution needs a YARN application with 2 containers.
“TempletonControllerJob” saves the job status to /user/{user.name}/{statusdir} folder. Enumerating the folder content looks like below
$ hdfs dfs -ls /user/admin/firsttempletonjobstatusdir
Found 3 items
-rw-r--r-- 1 admin supergroup 2 2016-04-19 19:22 /user/admin/firsttempletonjobstatusdir/exit
-rw-r--r-- 1 admin supergroup 1542 2016-04-19 19:22 /user/admin/firsttempletonjobstatusdir/stderr
-rw-r--r-- 1 admin supergroup 294 2016-04-19 19:22 /user/admin/firsttempletonjobstatusdir/stdout
$
exit: Contains the exit code of the HIVE query. For successful queries ZERO is expected. Non-zero exit code is expected otherwise.
stdout: Contains the query output. In-case of select query this will contain the result set in text.
stderr: Contains the Hive logs (similar to what we will see when ran on HIVE CLI)
Sample stderr shows below (highlighted the YARN application ID of actual HIVE query i.e. application_1461091727457_0008)
$ hdfs dfs -cat /user/admin/firsttempletonjobstatusdir/stderr
WARNING: Use "yarn jar" to launch YARN applications.
Logging initialized using configuration in jar:file:/mnt/resource/hadoop/yarn/local/usercache/admin/filecache/10/hive-common.jar!/hive-log4j.properties
Query ID = yarn_20160419192210_84af4c6e-4458-43f8-9b15-31efce234dc4
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1461091727457_0008)
Map 1: -/- Reducer 2: 0/2
Map 1: 0/1 Reducer 2: 0/2
Map 1: 0/1 Reducer 2: 0/2
Map 1: 0/1 Reducer 2: 0/2
Map 1: 0/1 Reducer 2: 0/2
Map 1: 0/1 Reducer 2: 0/2
Map 1: 0/1 Reducer 2: 0/2
Map 1: 0(+1)/1 Reducer 2: 0/2
Map 1: 0(+1)/1 Reducer 2: 0/2
Map 1: 1/1 Reducer 2: 0/2
Map 1: 1/1 Reducer 2: 0(+1)/1
Map 1: 1/1 Reducer 2: 1/1
Status: DAG finished successfully in 22.57 seconds
METHOD DURATION(ms)
parse 2,144
semanticAnalyze 3,248
TezBuildDag 942
TezSubmitToRunningDag 334
TotalPrepTime 10,683
VERTICES TOTAL_TASKS FAILED_ATTEMPTS KILLED_TASKS DURATION_SECONDS CPU_TIME_MILLIS GC_TIME_MILLIS INPUT_RECORDS OUTPUT_RECORDS
Map 1 1 0 0 3.92 5,810 59 59,793 34
Reducer 2 1 0 0 1.96 2,680 40 34 0
OK
Time taken: 33.94 seconds, Fetched: 34 row(s)
$
NOTE: In-case where the HIVE query execution failed you will see the corresponding “TempletonControllerJob” status as SUCCEEDED. The status directory contains the actual details.