Using Legacy Data Sources in Tabular 1400
The modern Get Data experience in Tabular 1400 brings interesting new data discovery and transformation capabilities to Analysis Services. However, not every BI professional is equally excited. Especially those who prefer to build their models exclusively on top of SQL Server databases or data warehouses and appreciate the steadiness of tried and proven T-SQL queries over fast SQL OLE DB provider connections might not see a need for mashups. If you belong to this group of BI professionals, there is good news: Tabular 1400 fully supports provider data sources and native query partitions. The modern Get Data experience is optional.
Upgrading from 1200 to 1400
Perhaps the easiest way to create a Tabular 1400 model with provider data sources and native query partitions is to upgrade an existing 1200 model to the 1400 compatibility level. If you used Windiff or a similar tool to compare the Model.bim file in your Tabular project before and after the upgrade, you will find that not much was changed. In fact, the only change concerns the compatibilityLevel parameter, which the upgrade logic sets to a value of 1400, as the following screenshot reveals.

At the 1400 compatibility level, regardless of the data sources and table partitions, you can use any advanced modeling feature, such as detail rows expressions and object-level security. There are no dependencies on structured data sources or M partitions using the Mashup engine. Legacy provider data sources and native query partitions work just as well. They bypass the Mashup engine. It's just two different code paths to get the data.
Provider data sources versus structured data sources
Provider data sources get their name from the fact that they define the parameters for a data provider in the form of a connection string that the Analysis Services engine then uses to connect to the data source. They are sometimes referred to as legacy data sources because they are typically used in 1200 and earlier compatibility levels to define the data source details.
Structured data sources, on the other hand, get their name from the fact that they define the connection details in structured JSON property bags. They are sometimes referred to as modern or Power Query/M-based data sources because they correspond to Power Query/M-based data access functions, as explained in more detail in Supporting Advanced Data Access Scenarios in Tabular 1400 Models.
At a first glance, provider data sources have an advantage over structured data sources because they provide full control over the connection string. You can specify any advanced parameter that the provider supports. In contrast, structured data sources only support the address parameters and options that their corresponding data access functions support. This is usually sufficient, however. Note that provider data sources also have disadvantages, as explained in the next section.
A small sample application can help to illustrate the metadata differences between provider data sources and structured data sources. Both can be added to a Tabular 1400 model using Tabular Object Model (TOM) or the Tabular Model Scripting Language (TMSL).
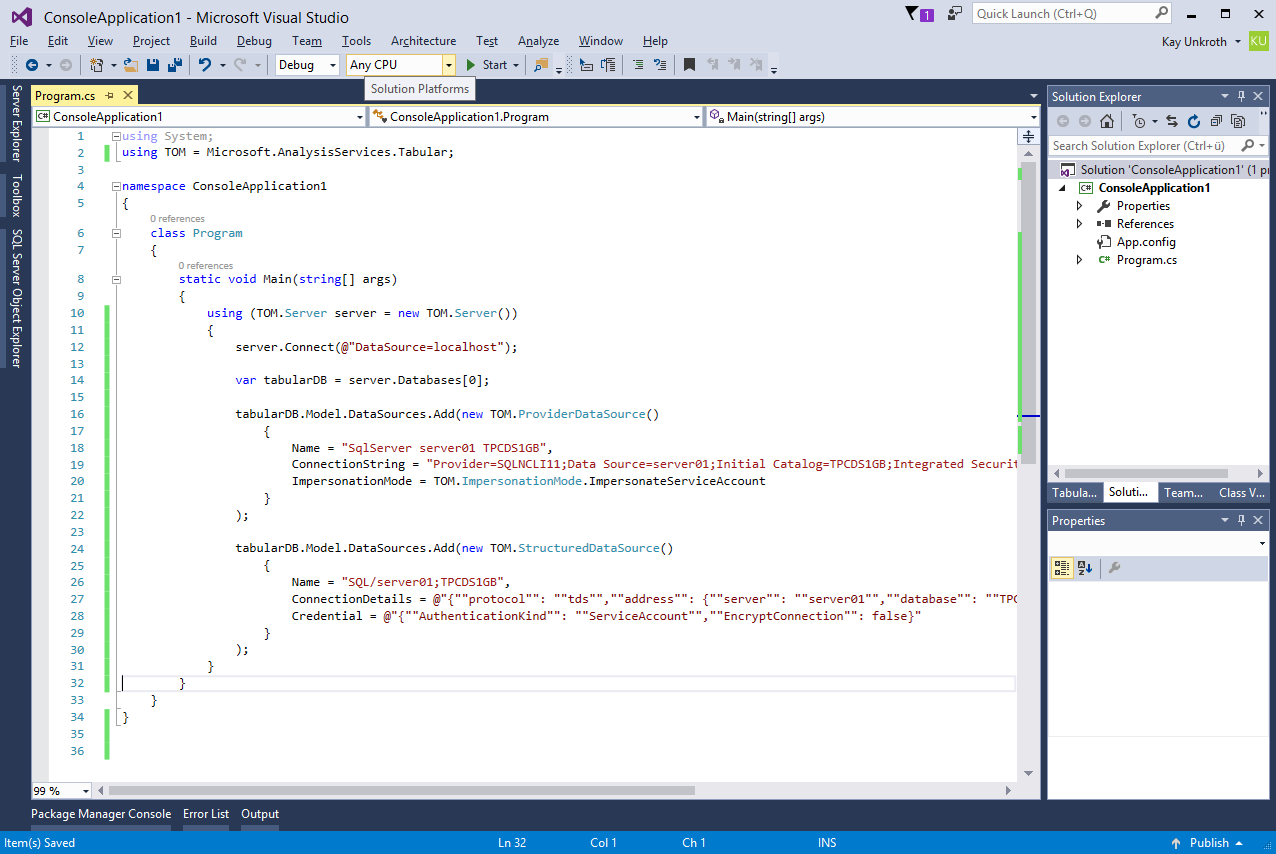
Note that Analysis Services always invokes the Mashup engine when using structured data sources to get the data. It might or might not for provider data sources. The choice depends on the table partitions on top of the data source, as the next section explains.
Query partitions versus M partitions
Just as there are multiple types of data source definitions in Tabular 1400, there are also multiple partition source types to import data into a table. Specifically, you can define a partition by using a QueryPartitionSource or an MPartitionSource, as in the following TOM code sample.

As illustrated, you can mix query partitions with M partitions even on a single table. The only requirement is that all partition sources must return the same set of source columns, mapped to table columns at the Tabular metadata layer. In the example above, both partitions use the same data source and import the same data, so you end up with duplicate rows. This is normally not what you want, but in this concrete example, the duplicated rows help to illustrate that Analyses Services could indeed process both partition sources successfully, as in the following screenshot.
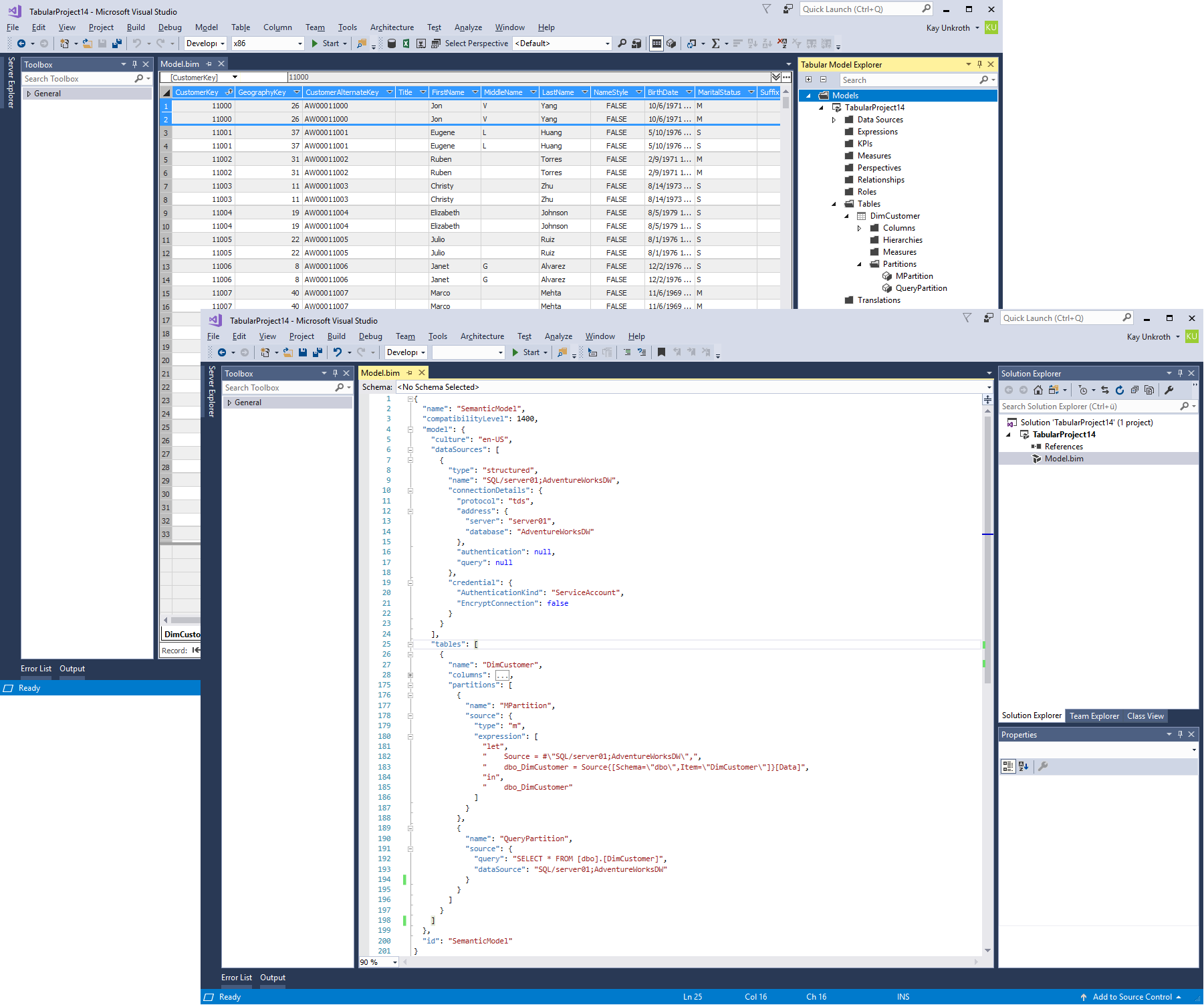
The Model.bim file reveals that the M and query partition sources reference a structured data source, but they could also reference a provider data source as in the screenshot below the following table summarizing the possible combinations. In short, you can mix and match to your heart's content.
| Data Source | Partition Source | Comments | |
| 1 | Provider Data Source | Query Partition Source | The AS engine uses the cartridge-based connectivity stack to access the data source. |
| 2 | Provider Data Source | M Partition Source | The AS engine translates the provider data source into a generic structured data source and then uses the Mashup engine to import the data. |
| 3 | Structured Data Source | Query Partition Source | The AS engine wraps the native query on the partition source into an M expression and then uses the Mashup engine to import the data. |
| 4 | Structured Data Source | M Partition Source | The AS engine uses the Mashup engine to import the data. |
The scenarios 1 and 4 are straightforward. Scenario 3 is practically equivalent to scenario 4. Instead of creating a query partition source with a native query and having the AS engine convert this into an M expression, you could define an M partition source in the first place and use the Value.NativeQuery function to specify the native query, as the following screenshot demonstrates. Of course, this only works for connectors that support native source queries and the Value.NativeQuery function.

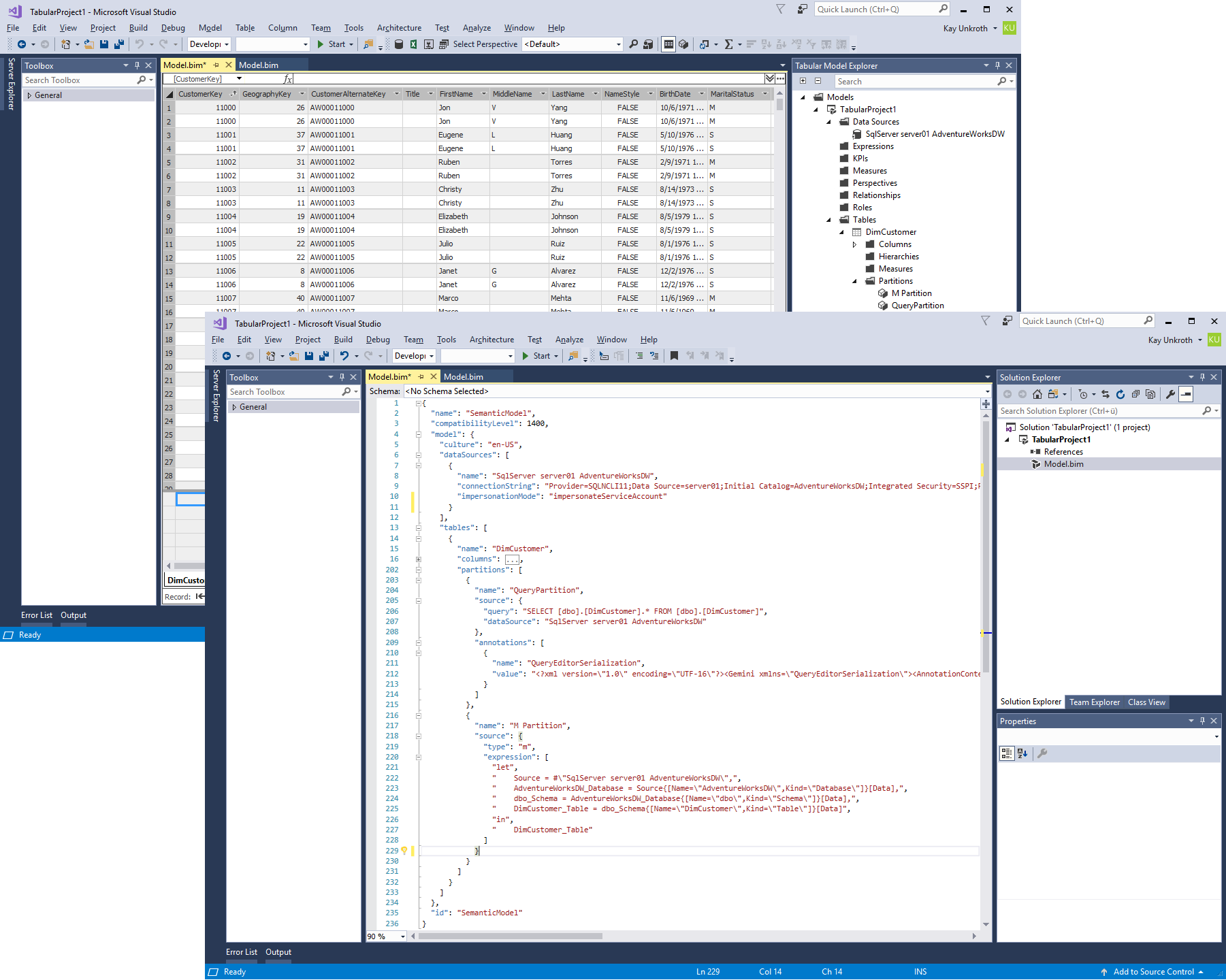
Scenario 2, "M partition on top of a provider data source"? is more complex than the others because it involves converting the provider data source into a generic structured data source. In other words, a provider data source pointing to a SQL Server database is not equivalent to a structured SQL Server data source because the AS engine does not convert this provider data source into a structured SQL Server data source. Instead, it converts it into a generic structured OLE DB, ODBC, or ADO.NET data source depending on the data provider that the provider data source referenced. For SQL Server connections, this is usually an OLE DB data source.
The fact that provider data sources are converted into generic structured data sources has important implications. For starters, M expressions on top of a generic data source differ from M expressions on top of a specific structured data source. For example, as the next screenshot highlights, an M expression over an OLE DB data source requires additional navigation steps to get to the desired table. You cannot simply take an M expression based on a structured SQL Server data source and put it on top of a generic OLE DB provider data source. If you tried, you would most likely get an error that the expression references an unknown variable or function.
Moreover, the Mashup engine cannot apply its query optimizations for SQL Server when using a generic OLE DB data source, so M expressions on top of generic provider data sources cannot be processed as efficiently as M expressions on top of specific structured data sources. For this reason, it is better to add a new structured data source to the model for any new M expression-based table partitions than to use an existing provider data source. Provider data sources and structured data sources can coexist in the same Tabular model.
In Tabular 1400, the main purpose of a provider data source is backward compatibility with Tabular 1200 so that the processing behavior of your models does not change just because you upgraded to 1400 and so that any ETL logic programmatically generating data sources and table partitions continues to work seamlessly. As mentioned, query partitions on top of a provider data source bypass the Mashup engine. However, the processing performance is not necessarily inferior with a structured data source thanks to a number of engine optimizations. This might seem counterintuitive, but it is a good idea to double-check the processing performance in your environment. The Microsoft SQL Server Native Client OLE DB Provider is indeed performing faster than the Mashup engine. In very large Tabular 1400 models connecting to SQL Server databases, it can therefore be advantageous to use a provider data source and query partitions.
Data sources and partitions in SSDT Tabular
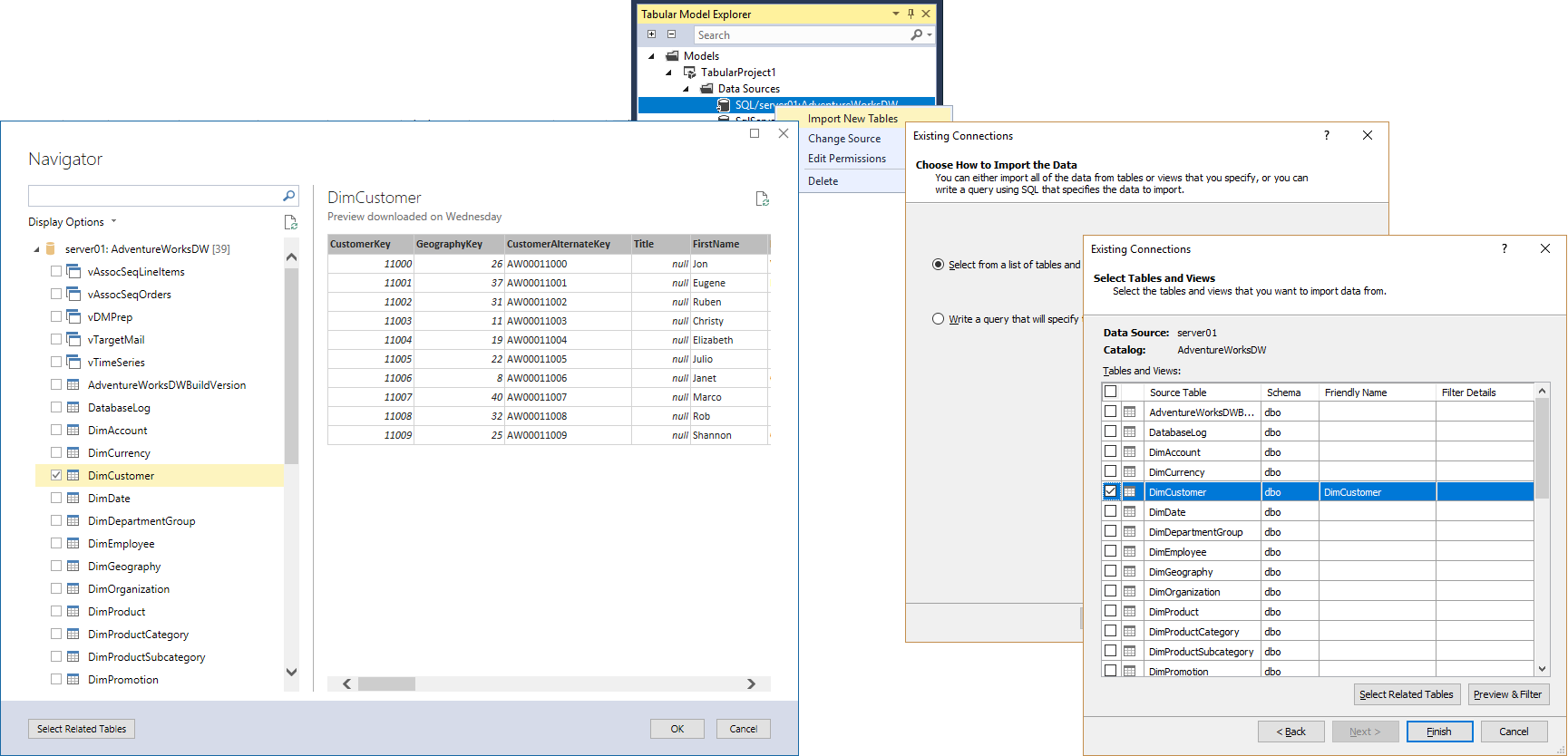
With TMSL and TOM, you can create data sources and table partitions in any combination, but this is not the case in SSDT Tabular. By default, SSDT creates structured data sources, and when you right-click a structured data source in Tabular Model Explorer and select Import New Tables, you launch the modern Get Data UI. Among other things, the default behavior helps to provide a consistent user interface and avoids confusion. You don't need to weigh the pros and cons of provider versus structured and you don't need to select a different partition source type and work with a different UI just because you wanted to write a native query. As explained in the previous section, an M expression using Value.NativeQuery is equivalent to a query partition over a structured data source.
Only if a model contains provider data sources already, say due to an upgrade from 1200, SSDT displays the legacy UI for editing these metadata objects. By the same token, when you right-click a provider data source in Tabular Model Explorer and select Import New Tables, you launch the legacy UI for defining a query partition source. If you don't add any new data sources, the user interface is still consistent with the 1200 experience. Yet, if you mix provider and structured data sources in a model, the UI switches back and forth depending on what object type you edit. See the following screenshot with the modern experience on the left and the legacy UI on the right – which one you see depends on the data source type you right-clicked.
Fully enabling the legacy UI
BI professionals who prefer to build their Tabular models exclusively on top of SQL Server data warehouses using native T-SQL queries might look unfavorable at SSDT Tabular's strong bias towards the modern Get Data experience. But the good news is that you can fully enable the legacy UI to create provider data sources in Tabular 1400 models, so you don't need to resort to using TMSL or TOM for this purpose.
In the current version of SSDT Tabular, you must configure a DWORD parameter called "Enable Legacy Import" in the Windows registry. Setting this parameter to 1 enables the legacy UI. Setting it to zero or removing the parameter disables it again. To enable the legacy UI, you can copy the following lines into a .reg file and import the file into the registry. Do not forget to restart Visual Studio to apply the changes.
Windows Registry Editor Version 5.0
[HKEY_CURRENT_USER\Software\Microsoft\Microsoft SQL Server\14.0\Microsoft Analysis Services\Settings]
"Enable Legacy Import"=dword:00000001
With the legacy UI fully enabled, you can right-click on Data Sources in Tabular Model Explorer and choose to Import From Data Source (Legacy) or reuse Existing Connections (Legacy), as in the following screenshot. As you would expect, these options create provider data sources in the model and then you can create query partitions on top of these.

Wrapping things up
While AS engine, TMSL, and TOM give you full control over data sources and table partitions, SSDT Tabular attempts to simplify things by favoring M partitions over structured data sources wherever possible. The legacy UI only shows up if you already have provider data sources or query partitions in your model. Should legacy data sources and query partitions be first-class citizens in Tabular 1400? Perhaps SSDT should provide an explicit option in the user interface to enable the legacy UI to eliminate the need for configuring a registry parameter. Let us know if this is something we should do. Also, there is currently no SSDT support for creating M partitions over provider data sources or query partitions over structured data sources because these scenarios seem less important and less desirable. Do you need these features?
Send us your feedback via email to SSASPrev at Microsoft.com. Or use any other available communication channels such as UserVoice or MSDN forums. Or simply post a comment to this article. Influence the evolution of the Analysis Services connectivity stack to the benefit of all our customers!
Comments
- Anonymous
September 14, 2017
I don't think there should be an option for the legacy UI.Sure, there may be some performance gain but if the professional requires that 5% load improvement (or whatever % it is) then they can leverage the registry or TOM.I imagine M will continue to be rolled out to other tools, eg SSMS, the SQL Relational Engine, a standalone server etc. If this is true, then it's best to keep data import consistent over the MS landscape. - Anonymous
October 12, 2017
Would much rather see MSFT product development time allocated to more important features. - Anonymous
October 23, 2017
The comment has been removed - Anonymous
January 31, 2018
This is an important feature... I only wish I could get that registry key to actually work! The legacy connections in all the models I upgraded to 1400 compatibility work just fine. Building a new model right now, and can't connect to SQL server - I'm using account impersonation, and every time it fails to connect... using exact same connections and account as I can use in my old legacy connection models. Did you remove that registry key in a more recent version?- Anonymous
January 31, 2018
ah. never mind... this has been elevated to being implementable through the options menu. And, yes, once I selected this, and had the option to use the legacy import, my data imported no problem... something wrong going on with the account impersonation in the new data source system
- Anonymous
- Anonymous
March 11, 2019
To Enable Legacy UI, you can make changes in SSDT itself rather then updating registry. Go to Tools -> Options -> Analysis Services Tabular -> Data Import. Check Enable Legacy data Sources. This is very important if you are developing Tabular Model to host on AAS,