Hyper-V Virtual Switch Performance - Virtual Machine Queue
In my last post, I talked about how various NIC offloads are supported in VMSWITCH to provide high performance network device virtualization. In this post, I would talk about another networking performance technique called virtual machine queues (or VMQ).
Background
In Windows networking stack, to utilize multiple processors in a machine, a feature called RSS (or receive side scaling) is used. This feature was co-developed by Microsoft working with hardware partners. It provides two main features:
- It allows incoming traffic to be put on different queues that get processed on different processors based on TCP/UDP stream information i.e. source and destination IP and ports.
- It allows sent traffic to be put on specific queues and completion for sent traffic to be handled on a specific processor based on the TCP/UDP stream information.
RSS allows different TCP/UDP streams to be handled on different processors without causing out of order packets thus allowing multiple processors to be used for networking.
Before RSS, NIC used to interrupt a single processor to indicate reveived packets or send completions and software distribution was needed to distribute the processing to different processors, resulting in expensive inter-processor signaling etc. With RSS, NIC sends interrupt to a specific processor, as specified in the RSS indirection table, to indicate received packets or send completions, thereby allowing multiple processors to be used concurrently without any additional software signalling.
You can read more about RSS here and here.
Using RSS in VMSWITCH, however, was not practical since RSS in the physical NIC supports a single indirection table and single key to hash the incoming packets. However, in case of virtualization, there are multiple VMs running on a single host and thus you end up with multiple indirection tables, that is not supported in hardware. While it was possible to create new indirection table in VMSWITCH and then use that for all the VMs, the performance testing showed that to cause regressions under certain workloads.
This caused VMSWITCH to always use the default processor that was associated with the physical NIC for both receive and send-complete handling. This limited the networking bandwidth in Hyper-V to the processing capacity of a single processor which was around 5-6Gbps on a high end processor with packet size varying from 1KB-4KB.
A better solution was needed to allow VMSWITCH to leverage multiple processors in a deterministic fashion.
Virtual Machine Queues (VMQ)
After building the first version of VMSWITCH, I moved to the hypervisor team, as I wanted to work on the hypervisor kernel which is a bare metal OS that runs directly on physical hardware. VMSWITCH ownership moved from Hyper-V team to networking team in Windows to better align Hyper-V networking with overall Windows networking stack. To solve the problem of single processor bottleneck in VMSWITCH, Windows networking team designed a feature called virtual machine queues that allowed VMSWITCH to use multiple processors for networking traffic. This feature allowed a NIC to have separate queues that gets associated with one or more destination MAC address, instead of an RSS style indirection table as shown in the picture below.
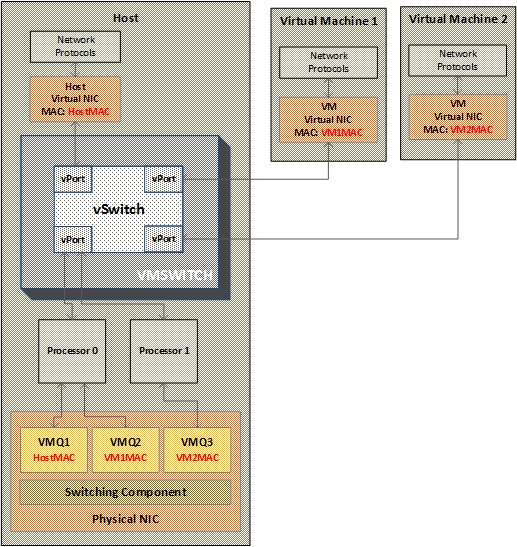
With VMQ, it was possible to allocate separate queues for separate VMs and put the incoming traffic for the specific VM (as identified based on destination MAC address in the packet) into that queue. Each queue could be associated with its own interrupt that goes to a separate processor or multiple queues interrupt could be associated to a single processor, providing flexibility in processor utilization as needed. With VMQ, it was possible to get to line rate performance on 10Gbps NICs and use multiple processors solving the single processor bottleneck issue completely.
The first iteration of VMQ allowed static allocation of number of processors on a per physical NIC basis and various VMQ were associated with these processors on a round-robin basis. For example, as shown in picture above, two processors are used for VMQ and VMQ1 and VMQ2 are associated with processor0 and VMQ3 is associated with processor1. This static allocation could not optimize the overall processor allocation and utilization for dynamic workloads. For example, in a round-robin fashion, you could end up with VM1 and VM9 on a same processor and if both became networking heavy, it wasn't possible to use other processors for their traffic. We solved this problem by building a feature called dynamic VMQ and that would be the topic of my next post.