Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
This article contains recommendations for designing hash-distributed and round-robin distributed tables in dedicated SQL pools.
W tym artykule założono, że znasz pojęcia dotyczące dystrybucji danych i przenoszenia danych w dedykowanej puli SQL. Aby uzyskać więcej informacji, zobacz Architektura usługi Azure Synapse Analytics.
Co to jest tabela rozproszona?
Tabela rozproszona jest wyświetlana jako pojedyncza tabela, ale wiersze są rzeczywiście przechowywane w 60 dystrybucjach. The rows are distributed with a hash or round-robin algorithm.
Dystrybucja haszowa poprawia wydajność zapytań w dużych tabelach faktów, co jest głównym tematem tego artykułu. Round-robin distribution is useful for improving loading speed. Te wybory projektowe mają znaczący wpływ na poprawę wydajności zapytań i ładowania.
Inną opcją magazynu tabel jest replikowanie małej tabeli we wszystkich węzłach obliczeniowych. Aby uzyskać więcej informacji, zobacz Wskazówki dotyczące projektowania replikowanych tabel. Aby szybko wybrać jedną z trzech opcji, zobacz Tabele rozproszone w przeglądzie tabel.
W ramach projektowania tabel dowiedz się, jak najwięcej o danych i sposobie wykonywania zapytań dotyczących danych. Rozważmy na przykład następujące pytania:
- Jak duży jest stół?
- Jak często jest odświeżona tabela?
- Do I have fact and dimension tables in a dedicated SQL pool?
Hash distributed
A hash-distributed table distributes table rows across the Compute nodes by using a deterministic hash function to assign each row to one distribution.
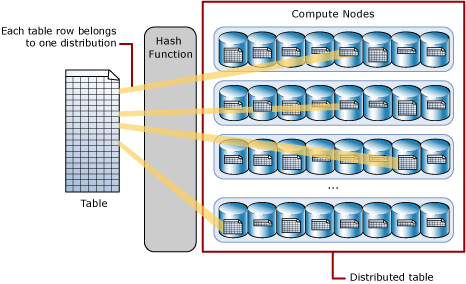
Ponieważ identyczne wartości zawsze są hashowane do tej samej dystrybucji, SQL Analytics ma wbudowaną wiedzę o lokalizacjach wierszy. W dedykowanej puli SQL ta wiedza służy do minimalizowania przenoszenia danych podczas zapytań, co zwiększa wydajność zapytań.
Hash-distributed tables work well for large fact tables in a star schema. They can have very large numbers of rows and still achieve high performance. Istnieją pewne zagadnienia projektowe, które ułatwiają uzyskanie wydajności, do której jest zaprojektowany system rozproszony. Wybór odpowiedniej kolumny lub kolumn dystrybucji jest jednym z zagadnień opisanych w tym artykule.
Consider using a hash-distributed table when:
- Rozmiar tabeli na dysku wynosi ponad 2 GB.
- Tabela zawiera częste operacje wstawiania, aktualizowania i usuwania.
Round-robin distributed
A round-robin distributed table distributes table rows evenly across all distributions. Przypisanie wierszy do dystrybucji jest losowe. W przeciwieństwie do tabel rozproszonych przy użyciu skrótów wiersze o równych wartościach nie mają gwarancji przypisania do tej samej dystrybucji.
W związku z tym system czasami musi wywołać operację przenoszenia danych, aby lepiej zorganizować dane przed rozwiązaniem zapytania. Ten dodatkowy krok może spowolnić zapytania. For example, joining a round-robin table usually requires reshuffling the rows, which is a performance hit.
Consider using the round-robin distribution for your table in the following scenarios:
- When getting started as a simple starting point since it is the default
- If there is no obvious joining key
- If there is no good candidate column for hash distributing the table
- Jeśli tabela nie ma wspólnego klucza sprzężenia z innymi tabelami
- If the join is less significant than other joins in the query
- When the table is a temporary staging table
The tutorial Load New York taxicab data gives an example of loading data into a round-robin staging table.
Wybierz kolumnę dystrybucji
A hash-distributed table has a distribution column or set of columns that is the hash key. For example, the following code creates a hash-distributed table with ProductKey as the distribution column.
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
);
Dystrybucja hash może być stosowana na wielu kolumnach w celu bardziej równomiernej dystrybucji tabeli podstawowej. Dystrybucja wielokolumna umożliwia wybranie maksymalnie ośmiu kolumn do dystrybucji. Zmniejsza to nie tylko niesymetryczność danych w czasie, ale także poprawia wydajność zapytań. Na przykład:
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey], [OrderDateKey], [CustomerKey] , [PromotionKey])
);
Uwaga
Dystrybucję wielokolumnową w usłudze Azure Synapse Analytics można włączyć, zmieniając poziom zgodności bazy danych na 50 za pomocą tego polecenia.
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; Aby uzyskać więcej informacji na temat ustawiania poziomu zgodności bazy danych, zobacz ALTER DATABASE SCOPED CONFIGURATION. Aby uzyskać więcej informacji na temat dystrybucji wielokolumnowych, zobacz CREATE MATERIALIZED VIEW, CREATE TABLE lub CREATE TABLE AS SELECT.
Dane przechowywane w kolumnach dystrybucji można aktualizować. Updates to data in distribution columns could result in data shuffle operation.
Choosing distribution columns is an important design decision since the values in the hash columns determine how the rows are distributed. Najlepszy wybór zależy od kilku czynników i zwykle wiąże się z kompromisami. Po wybraniu kolumny dystrybucji lub zestawu kolumn nie można go zmienić. Jeśli nie wybrano najlepszych kolumn po raz pierwszy, możesz użyć polecenia CREATE TABLE AS SELECT (CTAS), aby ponownie utworzyć tabelę z żądanym kluczem skrótu dystrybucji.
Choose a distribution column with data that distributes evenly
For best performance, all of the distributions should have approximately the same number of rows. Jeśli co najmniej jedna z dystrybucji ma liczbę wierszy nieproporcjonalną w stosunku do innych, niektóre z nich kończą swoją część zapytania równoległego wcześniej niż pozostałe. Ponieważ zapytanie nie może zakończyć się, dopóki wszystkie dystrybucje nie zakończą przetwarzania, każde zapytanie jest tylko tak szybkie, jak najwolniejsza dystrybucja.
- Niesymetryczność danych oznacza, że dane nie są równomiernie dystrybuowane w różnych dystrybucjach
- Processing skew means that some distributions take longer than others when running parallel queries. Może się tak zdarzyć, gdy dane są niesymetryczne.
Aby zrównoważyć przetwarzanie równoległe, wybierz kolumnę dystrybucji lub zestaw kolumn, które:
- Ma wiele unikatowych wartości. Co najmniej jedna kolumna dystrybucji może mieć zduplikowane wartości. Wszystkie wiersze o tej samej wartości są przypisywane do tej samej dystrybucji. Ponieważ istnieje 60 dystrybucji, niektóre dystrybucje mogą mieć > 1 unikatowe wartości, podczas gdy inne mogą kończyć się wartościami zerowymi.
- Does not have NULLs, or has only a few NULLs. W skrajnym przykładzie, jeśli wszystkie wartości w kolumnach dystrybucji mają wartość NULL, wszystkie wiersze są przypisywane do tej samej dystrybucji. W związku z tym przetwarzanie zapytań jest skierowane na jedną dystrybucję i nie korzysta z przetwarzania równoległego.
- Is not a date column. All data for the same date lands in the same distribution, or will cluster records by date. Jeśli kilku użytkowników filtruje tę samą datę (na przykład bieżącą datę), tylko 1 z 60 dystrybucji wykonuje wszystkie operacje przetwarzania.
Wybierz kolumnę dystrybucji, która minimalizuje przenoszenie danych
Aby uzyskać prawidłowe wyniki zapytań, zapytania mogą przenosić dane z jednego węzła obliczeniowego do innego. Przenoszenie danych często występuje, gdy zapytania mają sprzężenia i agregacje w tabelach rozproszonych. Wybór kolumny dystrybucji lub zestawu kolumn, który pomaga zminimalizować przenoszenie danych, jest jedną z najważniejszych strategii optymalizacji wydajności Twojej dedykowanej puli SQL.
Aby zminimalizować przenoszenie danych, wybierz kolumnę dystrybucji lub zestaw kolumn, które:
- Jest używany w klauzulach
JOIN,GROUP BY,DISTINCT,OVERiHAVING. Gdy dwie duże tabele faktów często się łączą, wydajność zapytań poprawia się, gdy dystrybuujesz obie tabele według jednej z kolumn sprzężenia. When a table is not used in joins, consider distributing the table on a column or column set that is frequently in theGROUP BYclause. - Is not used in
WHEREclauses. When a query'sWHEREclause and the table's distribution columns are on the same column, the query could encounter high data skew, leading to processing load falling on only few distributions. Ma to wpływ na wydajność zapytań, a w idealnym przypadku wiele dystrybucji współużytkuje obciążenie przetwarzania. - Is not a date column.
WHEREklauzule często filtrują według daty. W takim przypadku wszystkie operacje przetwarzania mogą być uruchamiane tylko w kilku dystrybucjach wpływających na wydajność zapytań. W idealnym przypadku wiele dystrybucji współdzieli obciążenie przetwarzania.
Po zaprojektowaniu tabeli z rozproszonym haszem, kolejnym krokiem jest załadowanie danych do tabeli. Aby uzyskać wskazówki dotyczące ładowania, zobacz Przegląd ładowania.
Jak określić, czy Twoja dystrybucja jest dobrym wyborem
Po załadowaniu danych do tabeli rozproszonej przy użyciu skrótów sprawdź, jak równomiernie wiersze są dystrybuowane w 60 dystrybucjach. The rows per distribution can vary up to 10% without a noticeable impact on performance.
Consider the following ways to evaluate your distribution columns.
Ustal, czy tabela ma niesymetryczność danych
Szybkim sposobem sprawdzenia niesymetryczności danych jest użycie DBCC PDW_SHOWSPACEUSED. Poniższy kod SQL zwraca liczbę wierszy tabeli przechowywanych w każdej z 60 dystrybucji. For balanced performance, the rows in your distributed table should be spread evenly across all the distributions.
-- Find data skew for a distributed table
DBCC PDW_SHOWSPACEUSED('dbo.FactInternetSales');
Aby określić, które tabele mają ponad 10% niesymetryczności danych:
- Utwórz widok
dbo.vTableSizespokazywany w artykule Omówienie tabel. - Uruchom poniższe zapytanie:
select *
from dbo.vTableSizes
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, row_count;
Sprawdzanie planów zapytań dotyczących przenoszenia danych
Dobry zestaw kolumn dystrybucji umożliwia łączenia i agregacje, co pozwala na minimalizowanie przesunięć danych. Ma to wpływ na sposób pisania łączeń. To get minimal data movement for a join on two hash-distributed tables, one of the join columns needs to be in distribution column or columns. Gdy dwie tabele z rozproszonym haszowo układem łączą się na kolumnie dystrybucyjnej tego samego typu danych, łączenie nie wymaga przenoszenia danych. Joins can use additional columns without incurring data movement.
Aby uniknąć przenoszenia danych podczas sprzężenia:
- Tabele biorące udział w sprzężeniu muszą być podzielone haszowo według jednej z kolumn uczestniczących w sprzężeniu.
- The data types of the join columns must match between both tables.
- The columns must be joined with an equals operator.
- Typ sprzężenia nie może być typem
CROSS JOIN.
Aby sprawdzić, czy w zapytaniach występują przenoszenie danych, możesz przyjrzeć się planowi zapytania.
Resolve a distribution column problem
Nie jest konieczne rozwiązanie wszystkich przypadków niesymetryczności danych. Dystrybucja danych to kwestia znalezienia właściwej równowagi między minimalizacją niesymetryczności danych a przenoszeniem danych. Nie zawsze można zminimalizować niesymetryczność danych i przenoszenie danych. Czasami korzyści wynikające z minimalnego przenoszenia danych mogą przewyższać wpływ niesymetryczności danych.
To decide if you should resolve data skew in a table, you should understand as much as possible about the data volumes and queries in your workload. Kroki opisane w artykule Monitorowanie zapytań umożliwiają monitorowanie wpływu niesymetryczności zapytań na wydajność zapytań. W szczególności sprawdź, jak długo trwa wykonywanie dużych zapytań w poszczególnych dystrybucjach.
Ponieważ nie można zmienić kolumn dystrybucji w istniejącej tabeli, typowym sposobem rozwiązania niesymetryczności danych jest ponowne utworzenie tabeli z różnymi kolumnami dystrybucji.
Re-create the table with a new distribution column set
W tym przykładzie użyto polecenia CREATE TABLE AS SELECT , aby ponownie utworzyć tabelę z różnymi kolumnami dystrybucji skrótów.
First use CREATE TABLE AS SELECT (CTAS) the new table with the new key. Następnie ponownie utwórz statystyki i na koniec zamień tabele, zmieniając ich nazwy.
CREATE TABLE [dbo].[FactInternetSales_CustomerKey]
WITH ( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([CustomerKey])
, PARTITION ( [OrderDateKey] RANGE RIGHT FOR VALUES ( 20000101, 20010101, 20020101, 20030101
, 20040101, 20050101, 20060101, 20070101
, 20080101, 20090101, 20100101, 20110101
, 20120101, 20130101, 20140101, 20150101
, 20160101, 20170101, 20180101, 20190101
, 20200101, 20210101, 20220101, 20230101
, 20240101, 20250101, 20260101, 20270101
, 20280101, 20290101
)
)
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
OPTION (LABEL = 'CTAS : FactInternetSales_CustomerKey')
;
--Create statistics on new table
CREATE STATISTICS [ProductKey] ON [FactInternetSales_CustomerKey] ([ProductKey]);
CREATE STATISTICS [OrderDateKey] ON [FactInternetSales_CustomerKey] ([OrderDateKey]);
CREATE STATISTICS [CustomerKey] ON [FactInternetSales_CustomerKey] ([CustomerKey]);
CREATE STATISTICS [PromotionKey] ON [FactInternetSales_CustomerKey] ([PromotionKey]);
CREATE STATISTICS [SalesOrderNumber] ON [FactInternetSales_CustomerKey] ([SalesOrderNumber]);
CREATE STATISTICS [OrderQuantity] ON [FactInternetSales_CustomerKey] ([OrderQuantity]);
CREATE STATISTICS [UnitPrice] ON [FactInternetSales_CustomerKey] ([UnitPrice]);
CREATE STATISTICS [SalesAmount] ON [FactInternetSales_CustomerKey] ([SalesAmount]);
--Rename the tables
RENAME OBJECT [dbo].[FactInternetSales] TO [FactInternetSales_ProductKey];
RENAME OBJECT [dbo].[FactInternetSales_CustomerKey] TO [FactInternetSales];
Powiązana zawartość
Aby utworzyć tabelę rozproszoną, użyj jednej z następujących instrukcji: