Dostrajanie wydajności za pomocą uporządkowanego klastrowanego indeksu magazynu kolumn w usłudze Azure Synapse Analytics
Dotyczy: dedykowane pule SQL usługi Azure Synapse Analytics
Gdy użytkownicy wysyłają zapytania do tabeli magazynu kolumn w dedykowanej puli SQL, optymalizator sprawdza minimalne i maksymalne wartości przechowywane w poszczególnych segmentach. Segmenty, które znajdują się poza granicami predykatu zapytania, nie są odczytywane z dysku do pamięci. Zapytanie może zakończyć się szybciej, jeśli liczba segmentów do odczytu i ich całkowity rozmiar są małe.
Uwaga
Ten artykuł dotyczy dedykowanych pul SQL usługi Azure Synapse Analytics. Aby uzyskać informacje na temat uporządkowanych indeksów magazynu kolumn w programie SQL Server i innych platformach SQL, zobacz Dostrajanie wydajności za pomocą uporządkowanych indeksów magazynu kolumn klastra.
Uporządkowany i nieskondycyjny indeks magazynu kolumn
Domyślnie dla każdej tabeli utworzonej bez opcji indeksu składnik wewnętrzny (konstruktor indeksu) tworzy na nim nieskondany indeks magazynu kolumn (CCI). Dane w każdej kolumnie są kompresowane do oddzielnego segmentu grupy wierszy CCI. Istnieją metadane dla zakresu wartości każdego segmentu, więc segmenty, które znajdują się poza granicami predykatu zapytania, nie są odczytywane z dysku podczas wykonywania zapytania. Funkcja CCI oferuje najwyższy poziom kompresji danych i zmniejsza rozmiar segmentów do odczytu, dzięki czemu zapytania mogą działać szybciej. Jednak ponieważ konstruktor indeksów nie sortuje danych przed ich skompresowaniem do segmentów, mogą wystąpić segmenty z nakładającymi się zakresami wartości, co powoduje, że zapytania odczytują więcej segmentów z dysku i trwa dłużej.
Uporządkowano klastrowane indeksy magazynu kolumn, umożliwiając wydajną eliminację segmentów, co znacznie przyspiesza wydajność, pomijając duże ilości uporządkowanych danych, które nie są zgodne z predykatem zapytania. Podczas tworzenia uporządkowanego CCI dedykowany aparat puli SQL sortuje istniejące dane w pamięci według kluczy zamówienia, zanim konstruktor indeksu skompresuje je do segmentów indeksu. W przypadku posortowanych danych nakładanie się segmentów jest zmniejszane, dzięki czemu zapytania mają wydajniejszą eliminację segmentów i tym samym szybciej, ponieważ liczba segmentów do odczytu z dysku jest mniejsza. Jeśli wszystkie dane można sortować w pamięci jednocześnie, można uniknąć nakładania się segmentów. Ze względu na duże tabele w magazynach danych ten scenariusz nie zdarza się często.
Aby sprawdzić zakresy segmentów dla kolumny, uruchom następujące polecenie z nazwą tabeli i nazwą kolumny:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
Uwaga
W uporządkowanej tabeli CCI nowe dane wynikające z tej samej partii DML lub operacji ładowania danych są sortowane w tej partii, nie ma globalnego sortowania wszystkich danych w tabeli. Użytkownicy mogą ponownie skompilować uporządkowane CCI, aby posortować wszystkie dane w tabeli. W dedykowanej puli SQL indeks magazynu kolumn REBUILD jest operacją offline. W przypadku tabeli partycjonowanej kompilacja jest wykonywana pojedynczo po jednej partycji. Dane w partycji, która jest odbudowywana, są "w trybie offline" i niedostępne do momentu ukończenia ponownego kompilowania dla tej partycji.
Wydajność zapytań
Wydajność zapytania z uporządkowanego CCI zależy od wzorców zapytań, rozmiaru danych, sposobu sortowania danych, fizycznej struktury segmentów oraz jednostek DWU i klasy zasobów wybranych do wykonania zapytania. Użytkownicy powinni przejrzeć wszystkie te czynniki przed wybraniem kolumn porządkowania podczas projektowania uporządkowanej tabeli CCI.
Zapytania ze wszystkimi tymi wzorcami są zwykle uruchamiane szybciej przy użyciu uporządkowanego interfejsu CCI.
- Zapytania mają równość, nierówności lub predykaty zakresu
- Kolumny predykatu i uporządkowane kolumny CCI są takie same.
W tym przykładzie tabela T1 ma indeks klastrowanego magazynu kolumn uporządkowany w sekwencji Col_C, Col_B i Col_A.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
Wydajność zapytania 1 i zapytania 2 może przynieść więcej korzyści z uporządkowanego CCI niż inne zapytania, ponieważ odwołują się do wszystkich uporządkowanych kolumn CCI.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
Wydajność ładowania danych
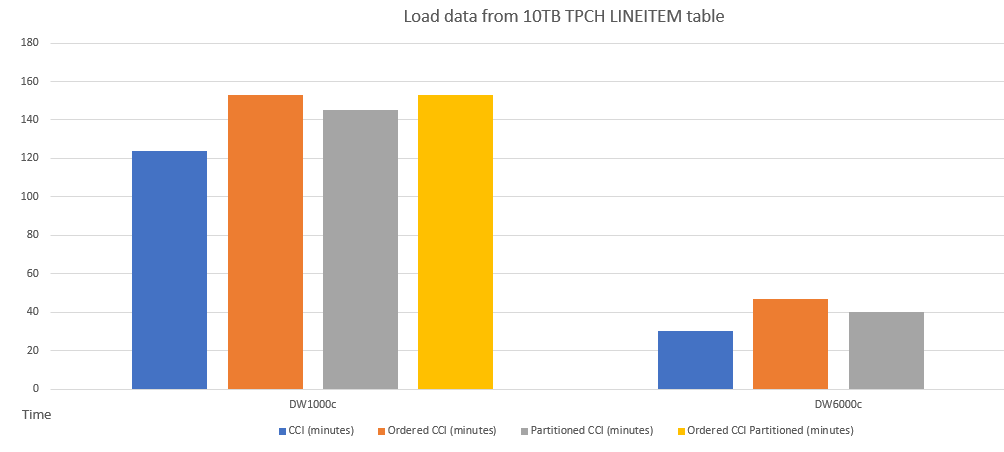
Wydajność ładowania danych do uporządkowanej tabeli CCI jest podobna do tabeli partycjonowanej. Ładowanie danych do uporządkowanej tabeli CCI może trwać dłużej niż nie uporządkowana tabela CCI ze względu na operację sortowania danych, jednak zapytania mogą działać szybciej później przy użyciu uporządkowanego interfejsu CCI.
Oto przykładowe porównanie wydajności ładowania danych do tabel z różnymi schematami.
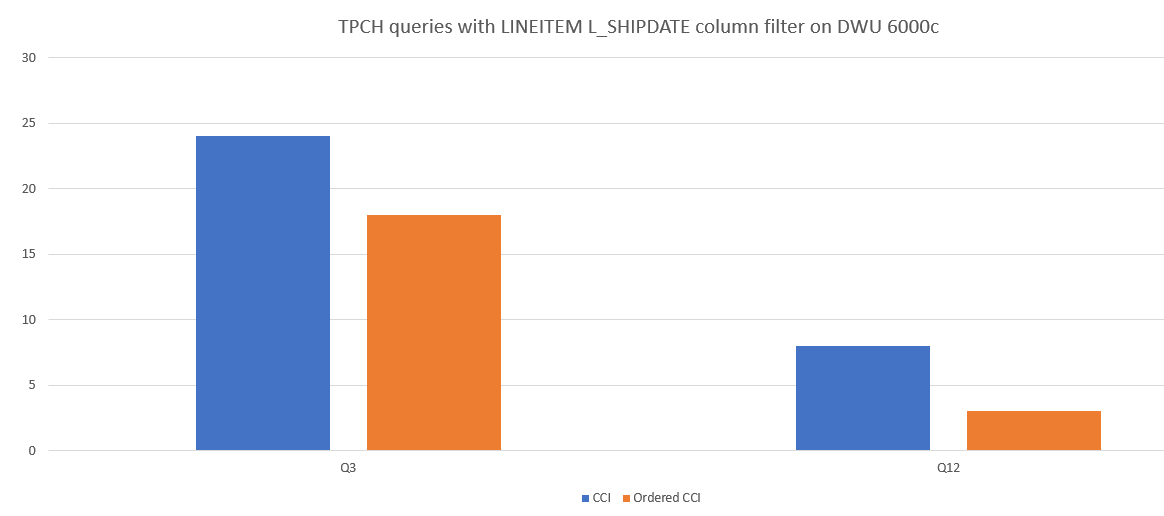
Oto przykładowe porównanie wydajności zapytań między CCI i uporządkowanym CCI.
Zmniejszanie nakładających się segmentów
Liczba nakładających się segmentów zależy od rozmiaru danych do sortowania, dostępnej pamięci i maksymalnego stopnia równoległości (MAXDOP) podczas uporządkowanego tworzenia CCI. Poniższe strategie zmniejszają nakładanie się segmentów podczas tworzenia uporządkowanego CCI.
Użyj
xlargercklasy zasobów w wyższej klasie DWU, aby umożliwić więcej pamięci do sortowania danych przed skompresowanie danych przez konstruktora indeksu do segmentów. Nie można zmienić lokalizacji fizycznej danych w segmencie indeksu. Nie ma sortowania danych w segmencie ani w różnych segmentach.Utwórz uporządkowane CCI za pomocą polecenia
OPTION (MAXDOP = 1). Każdy wątek używany do tworzenia uporządkowanego CCI działa w podzestawie danych i sortuje je lokalnie. Nie ma globalnego sortowania danych posortowanych według różnych wątków. Użycie wątków równoległych może skrócić czas tworzenia uporządkowanego CCI, ale spowoduje wygenerowanie bardziej nakładających się segmentów niż użycie pojedynczego wątku. Użycie jednej operacji wątkowej zapewnia najwyższą jakość kompresji. Na przykład:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Uwaga
Obecnie w dedykowanych pulach SQL w usłudze Azure Synapse Analytics opcja MAXDOP jest obsługiwana tylko podczas tworzenia uporządkowanej tabeli CCI przy użyciu CREATE TABLE AS SELECT polecenia . Tworzenie uporządkowanego interfejsu CCI za pośrednictwem polecenia CREATE INDEX lub CREATE TABLE nie obsługuje opcji MAXDOP. To ograniczenie nie dotyczy programu SQL Server 2022 i nowszych wersji, w których można określić parametr MAXDOP za CREATE INDEX pomocą poleceń lub CREATE TABLE .
- Wstępnie posortuj dane według kluczy sortowania przed załadowaniem ich do tabel.
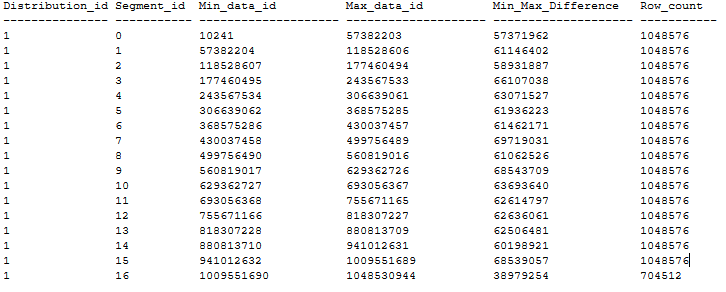
Oto przykład uporządkowanej dystrybucji tabel CCI, która ma zerowy segment nakładający się zgodnie z powyższymi zaleceniami. Uporządkowana tabela CCI jest tworzona w bazie danych DWU1000c za pośrednictwem CTAS z tabeli sterty 20 GB przy użyciu maxDOP 1 i xlargerc. CCI jest uporządkowane w kolumnie BIGINT bez duplikatów.
Tworzenie uporządkowanego CCI w dużych tabelach
Tworzenie uporządkowanego CCI jest operacją offline. W przypadku tabel bez partycji dane nie będą dostępne dla użytkowników do momentu zakończenia uporządkowanego procesu tworzenia CCI. W przypadku tabel partycjonowanych, ponieważ aparat tworzy uporządkowaną partycję CCI według partycji, użytkownicy nadal mogą uzyskiwać dostęp do danych w partycjach, w których uporządkowane tworzenie CCI nie jest w toku. Tej opcji można użyć, aby zminimalizować przestoje podczas uporządkowanego tworzenia CCI w dużych tabelach:
- Utwórz partycje w docelowej dużej tabeli (o nazwie
Table_A). - Utwórz pustą uporządkowaną tabelę CCI (o nazwie
Table_B) z tą samą tabelą i schematem partycji coTable_A. - Przełącz jedną partycję z
Table_AnaTable_B. - Uruchom polecenie
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>, aby ponownie skompilować partycję przełączoną w systemieTable_B. - Powtórz krok 3 i 4 dla każdej partycji w pliku
Table_A. - Gdy wszystkie partycje zostaną przełączone z
Table_AdoTable_Bi zostały ponownie skompilowane, upuśćTable_Ai zmień nazwęTable_BnaTable_A.
Napiwek
W przypadku dedykowanej tabeli puli SQL z uporządkowanym CCI funkcja ALTER INDEX REBUILD ponownie sortuje dane przy użyciu polecenia tempdb. Monitorowanie tempdb podczas operacji ponownej kompilacji. Jeśli potrzebujesz więcej tempdb miejsca, przeprowadź skalowanie w górę puli. Skaluj z powrotem w dół po zakończeniu ponownego kompilowania indeksu.
W przypadku dedykowanej tabeli puli SQL ze uporządkowanym CCI, funkcja ALTER INDEX REORGANIZE nie sortuje ponownie danych. Aby uciekać się do danych, użyj polecenia ALTER INDEX REBUILD.
Aby uzyskać więcej informacji na temat uporządkowanej konserwacji CCI, zobacz Optymalizowanie klastrowanych indeksów magazynu kolumn.
Różnice funkcji w możliwościach programu SQL Server 2022
Program SQL Server 2022 (16.x) wprowadził uporządkowane indeksy magazynu kolumn klastrowanych podobne do funkcji w dedykowanych pulach SQL usługi Azure Synapse.
- Obecnie tylko program SQL Server 2022 (16.x) i nowsze wersje obsługują klastrowane możliwości eliminacji segmentów magazynu kolumn dla typów danych ciągów, danych binarnych i guid oraz typu danych datetimeoffset dla skali większej niż dwie. Wcześniej ta eliminacja segmentu dotyczy typów danych liczbowych, dat i godzin oraz typu danych datetimeoffset ze skalowaniem mniejszym lub równym dwóm.
- Obecnie tylko program SQL Server 2022 (16.x) i nowsze wersje obsługują eliminację grup wierszy klastrowanego magazynu kolumn dla prefiksu
LIKEpredykatów, na przykładcolumn LIKE 'string%'. Eliminacja segmentów nie jest obsługiwana w przypadku użycia prefiksu LIKE, takiego jakcolumn LIKE '%string'.
Aby uzyskać więcej informacji, zobacz Co nowego w indeksach magazynu kolumn.
Przykłady
Odp. Aby sprawdzić uporządkowaną kolumnę i kolejność porządkową:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. Aby zmienić porządkowe kolumny, dodaj lub usuń kolumny z listy zamówień lub zmień z CCI na uporządkowany CCI:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
Następne kroki
- Aby uzyskać więcej porad dotyczących programowania, zobacz Omówienie programowania.
- Indeksy magazynu kolumn: omówienie
- Co nowego w indeksach magazynu kolumn
- Indeksy magazynu kolumn — wskazówki dotyczące projektowania
- Indeksy magazynu kolumn — wydajność zapytań