Łącznik dedykowanej puli SQL dla platformy Apache Spark w usłudze Azure Synapse
Wprowadzenie
Łącznik dedykowanej puli SQL usługi Azure Synapse dla platformy Apache Spark w usłudze Azure Synapse Analytics umożliwia efektywne przesyłanie dużych zestawów danych między środowiskiem uruchomieniowym platformy Apache Spark a dedykowaną pulą SQL. Łącznik jest dostarczany jako biblioteka domyślna z obszarem roboczym usługi Azure Synapse. Łącznik jest implementowany przy użyciu Scala języka. Łącznik obsługuje języki Scala i Python. Aby użyć łącznika z innymi opcjami języka notesu, użyj polecenia magic platformy Spark — %%spark.
Na wysokim poziomie łącznik zapewnia następujące możliwości:
- Odczyt z dedykowanej puli SQL usługi Azure Synapse:
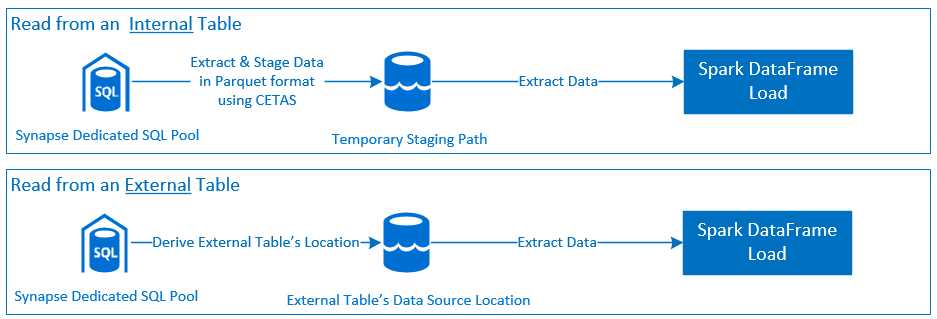
- Odczytywanie dużych zestawów danych z tabel dedykowanej puli SQL usługi Synapse (wewnętrznych i zewnętrznych) i widoków.
- Kompleksowa obsługa wypychania predykatu, gdzie filtry w ramce danych są mapowane na odpowiednie wypychanie predykatu SQL.
- Obsługa oczyszczania kolumn.
- Obsługa wypychania zapytań.
- Zapisz w dedykowanej puli SQL usługi Azure Synapse:
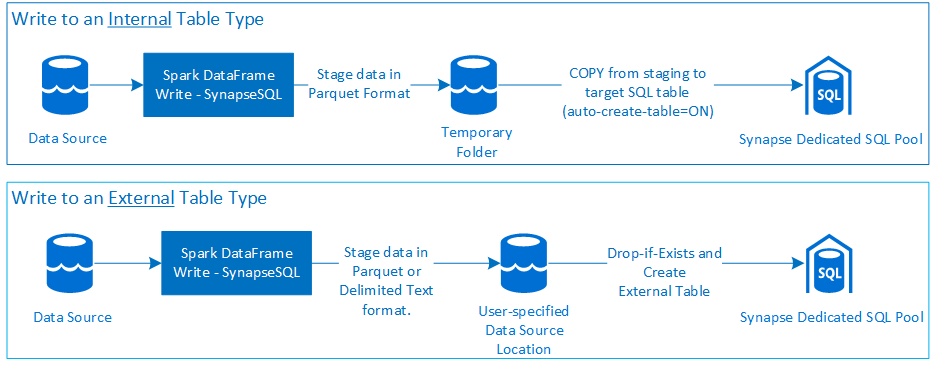
- Pozyskiwanie dużych ilości danych do typów tabel wewnętrznych i zewnętrznych.
- Obsługuje następujące preferencje trybu zapisywania ramki danych:
AppendErrorIfExistsIgnoreOverwrite
- Typ zapisu w tabeli zewnętrznej obsługuje format pliku tekstowego parquet i rozdzielany (na przykład — CSV).
- Aby zapisywać dane w tabelach wewnętrznych, łącznik używa teraz instrukcji COPY zamiast metody CETAS/CTAS.
- Ulepszenia optymalizacji kompleksowej wydajności przepływności zapisu.
- Wprowadza opcjonalny uchwyt wywołania zwrotnego (argument funkcji Scala), którego klienci mogą używać do odbierania metryk po zapisie.
- Oto kilka przykładów — liczba rekordów, czas trwania wykonania określonej akcji i przyczyna niepowodzenia.
Podejście orkiestracji
Przeczytaj
Write
Wymagania wstępne
Wymagania wstępne, takie jak konfigurowanie wymaganych zasobów platformy Azure i kroki ich konfigurowania, zostały omówione w tej sekcji.
Zasoby platformy Azure
Przejrzyj i skonfiguruj następujące zależne zasoby platformy Azure:
- Azure Data Lake Storage — używana jako podstawowe konto magazynu dla obszaru roboczego usługi Azure Synapse.
- Obszar roboczy usługi Azure Synapse — tworzenie notesów, kompilowanie i wdrażanie przepływów pracy ruchu przychodzącego opartego na ramce danych przychodzących i wychodzących.
- Dedykowana pula SQL (dawniej SQL DW) — udostępnia funkcje Magazyn danych przedsiębiorstwa.
- Bezserwerowa pula spark usługi Azure Synapse — środowisko uruchomieniowe platformy Spark, w którym zadania są wykonywane jako aplikacje platformy Spark.
Przygotowywanie bazy danych
Połącz się z dedykowaną bazą danych puli SQL usługi Synapse i uruchom następujące instrukcje konfiguracji:
Utwórz użytkownika bazy danych mapowanego na tożsamość użytkownika entra firmy Microsoft używaną do logowania się do obszaru roboczego usługi Azure Synapse.
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;Utwórz schemat, w którym zostaną zdefiniowane tabele, tak aby łącznik mógł pomyślnie zapisywać i odczytywać z odpowiednich tabel.
CREATE SCHEMA [<schema_name>];
Uwierzytelnianie
Uwierzytelnianie oparte na identyfikatorze Entra firmy Microsoft
Uwierzytelnianie oparte na identyfikatorze Entra firmy Microsoft to zintegrowane podejście do uwierzytelniania. Użytkownik musi pomyślnie zalogować się do obszaru roboczego usługi Azure Synapse Analytics.
Uwierzytelnianie podstawowe
Podstawowe podejście do uwierzytelniania wymaga skonfigurowania username i password opcji przez użytkownika. Zapoznaj się z sekcją — Opcje konfiguracji, aby dowiedzieć się więcej o odpowiednich parametrach konfiguracji do odczytu z tabel i zapisywania ich w tabelach w dedykowanej puli SQL usługi Azure Synapse.
Autoryzacja
Azure Data Lake Storage Gen2
Istnieją dwa sposoby udzielania uprawnień dostępu do usługi Azure Data Lake Storage Gen2 — konto magazynu:
- Rola kontrola dostępu oparta na rolach — rola Współautor danych obiektu blob usługi Storage
- Przypisanie uprawnień
Storage Blob Data Contributor Roleużytkownika do odczytu, zapisu i usuwania z kontenerów obiektów blob usługi Azure Storage. - Kontrola dostępu oparta na rolach oferuje podejście do kontroli coarse na poziomie kontenera.
- Przypisanie uprawnień
-
Listy kontroli dostępu (ACL)
- Podejście ACL umożliwia precyzyjne sterowanie określonymi ścieżkami i/lub plikami w danym folderze.
- Sprawdzanie listy ACL nie jest wymuszane, jeśli użytkownik ma już przyznane uprawnienia przy użyciu podejścia RBAC.
- Istnieją dwa szerokie typy uprawnień listy ACL:
- Uprawnienia dostępu (stosowane na określonym poziomie lub obiekcie).
- Uprawnienia domyślne (automatycznie stosowane dla wszystkich obiektów podrzędnych w momencie ich tworzenia).
- Typ uprawnień:
-
Executeumożliwia przechodzenie do hierarchii folderów lub nawigowanie po niej. -
Readumożliwia odczytywanie. -
Writeumożliwia zapisywanie.
-
- Należy skonfigurować listy ACL, tak aby łącznik mógł pomyślnie zapisywać i odczytywać z lokalizacji magazynu.
Uwaga
Jeśli chcesz uruchamiać notesy przy użyciu potoków obszaru roboczego usługi Synapse, musisz również przyznać powyższe uprawnienia dostępu do domyślnej tożsamości zarządzanej obszaru roboczego usługi Synapse. Domyślna nazwa tożsamości zarządzanej obszaru roboczego jest taka sama jak nazwa obszaru roboczego.
Aby używać obszaru roboczego usługi Synapse z zabezpieczonymi kontami magazynu, należy skonfigurować zarządzany prywatny punkt końcowy z poziomu notesu. Zarządzany prywatny punkt końcowy musi zostać zatwierdzony z sekcji konta
Private endpoint connectionsmagazynu usługi ADLS Gen2 w okienkuNetworking.
Dedykowana pula SQL usługi Azure Synapse
Aby umożliwić udaną interakcję z dedykowaną pulą SQL usługi Azure Synapse, konieczne jest wykonanie następującej autoryzacji, chyba że użytkownik jest również skonfigurowany jako w Active Directory Admin dedykowanym punkcie końcowym SQL:
Scenariusz odczytu
Udziel użytkownikowi
db_exporterprzy użyciu procedurysp_addrolememberskładowanej systemu .EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
Scenariusz zapisu
- Łącznik używa polecenia COPY do zapisywania danych z przemieszczania do lokalizacji zarządzanej tabeli wewnętrznej.
Skonfiguruj wymagane uprawnienia opisane tutaj.
Poniżej znajduje się fragment kodu szybkiego dostępu:
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- Łącznik używa polecenia COPY do zapisywania danych z przemieszczania do lokalizacji zarządzanej tabeli wewnętrznej.
Dokumentacja interfejsu API
Łącznik dedykowanej puli SQL usługi Azure Synapse dla platformy Apache Spark — dokumentacja interfejsu API.
Opcje konfiguracji
Aby pomyślnie uruchomić i zorganizować operację odczytu lub zapisu, łącznik oczekuje pewnych parametrów konfiguracji. Definicja obiektu — com.microsoft.spark.sqlanalytics.utils.Constants zawiera listę ustandaryzowanych stałych dla każdego klucza parametru.
Poniżej znajduje się lista opcji konfiguracji opartych na scenariuszu użycia:
-
Odczyt przy użyciu uwierzytelniania opartego na identyfikatorze Entra firmy Microsoft
- Poświadczenia są automatycznie mapowane, a użytkownik nie musi udostępniać określonych opcji konfiguracji.
- Trzyczęściowy argument nazwy tabeli w
synapsesqlmetodzie jest wymagany do odczytu z odpowiedniej tabeli w dedykowanej puli SQL usługi Azure Synapse.
-
Odczyt przy użyciu uwierzytelniania podstawowego
- Dedykowany punkt końcowy SQL usługi Azure Synapse
-
Constants.SERVER— Dedykowany punkt końcowy puli SQL usługi Synapse (nazwa FQDN serwera) -
Constants.USER— Nazwa użytkownika SQL. -
Constants.PASSWORD— Hasło użytkownika SQL.
-
- Punkt końcowy usługi Azure Data Lake Storage (Gen 2) — foldery przejściowe
-
Constants.DATA_SOURCE— Ścieżka magazynu ustawiona na parametr lokalizacji źródła danych jest używana do przemieszczania danych.
-
- Dedykowany punkt końcowy SQL usługi Azure Synapse
-
Pisanie przy użyciu uwierzytelniania opartego na identyfikatorze Entra firmy Microsoft
- Dedykowany punkt końcowy SQL usługi Azure Synapse
- Domyślnie łącznik wywnioskuje punkt końcowy usługi Synapse Dedicated SQL przy użyciu nazwy bazy danych ustawionej
synapsesqlna trzyczęściowym parametrze nazwy tabeli metody. - Alternatywnie użytkownicy mogą użyć
Constants.SERVERopcji , aby określić punkt końcowy sql. Upewnij się, że punkt końcowy hostuje odpowiednią bazę danych z odpowiednim schematem.
- Domyślnie łącznik wywnioskuje punkt końcowy usługi Synapse Dedicated SQL przy użyciu nazwy bazy danych ustawionej
- Punkt końcowy usługi Azure Data Lake Storage (Gen 2) — foldery przejściowe
- W przypadku typu tabeli wewnętrznej:
- Skonfiguruj opcję
Constants.TEMP_FOLDERlub .Constants.DATA_SOURCE - Jeśli użytkownik zdecydował się podać
Constants.DATA_SOURCEopcję, folder przejściowy będzie uzyskiwany przy użyciulocationwartości z źródła danych. - Jeśli podano obie wartości, zostanie użyta
Constants.TEMP_FOLDERwartość opcji. - W przypadku braku opcji folderu przejściowego łącznik będzie pochodzić na podstawie konfiguracji środowiska uruchomieniowego —
spark.sqlanalyticsconnector.stagingdir.prefix.
- Skonfiguruj opcję
- W przypadku typu tabeli zewnętrznej:
-
Constants.DATA_SOURCEjest wymaganą opcją konfiguracji. - Łącznik używa ścieżki magazynu ustawionej w parametrze lokalizacji źródła danych w połączeniu z argumentem
locationsynapsesqlmetody i uzyskuje ścieżkę bezwzględną do utrwalania danych tabeli zewnętrznej. -
locationJeśli argument metodysynapsesqlnie zostanie określony, łącznik będzie uzyskiwać wartość lokalizacji jako<base_path>/dbName/schemaName/tableName.
-
- W przypadku typu tabeli wewnętrznej:
- Dedykowany punkt końcowy SQL usługi Azure Synapse
-
Pisanie przy użyciu uwierzytelniania podstawowego
- Dedykowany punkt końcowy SQL usługi Azure Synapse
-
Constants.SERVER- — Dedykowany punkt końcowy puli SQL usługi Synapse (nazwa FQDN serwera). -
Constants.USER— Nazwa użytkownika SQL. -
Constants.PASSWORD— Hasło użytkownika SQL. -
Constants.STAGING_STORAGE_ACCOUNT_KEYskojarzone z kontem magazynu hostująceConstants.TEMP_FOLDERS(tylko typy tabel wewnętrznych) lubConstants.DATA_SOURCE.
-
- Punkt końcowy usługi Azure Data Lake Storage (Gen 2) — foldery przejściowe
- Poświadczenia podstawowego uwierzytelniania SQL nie mają zastosowania do uzyskiwania dostępu do punktów końcowych magazynu.
- W związku z tym należy przypisać odpowiednie uprawnienia dostępu do magazynu zgodnie z opisem w sekcji Azure Data Lake Storage Gen2.
- Dedykowany punkt końcowy SQL usługi Azure Synapse
Szablony kodu
W tej sekcji przedstawiono szablony kodu referencyjnego opisujące sposób używania i wywoływania dedykowanej puli SQL usługi Azure Synapse dla platformy Apache Spark.
Uwaga
Korzystanie z łącznika w języku Python—
- Łącznik jest obsługiwany tylko w języku Python dla platformy Spark 3. W przypadku platformy Spark 2.4 (nieobsługiwanej) możemy użyć interfejsu API łącznika Scala do interakcji z zawartością z ramki danych w PySpark przy użyciu elementu DataFrame.createOrReplaceTempView lub DataFrame.createOrReplaceGlobalTempView. Zobacz Sekcję — używanie zmaterializowanych danych między komórkami.
- Obsługa wywołań zwrotnych nie jest dostępna w języku Python.
Odczyt z dedykowanej puli SQL usługi Azure Synapse
Żądanie odczytu — synapsesql sygnatura metody
Odczytywanie z tabeli przy użyciu uwierzytelniania opartego na identyfikatorze Microsoft Entra
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Odczytywanie z zapytania przy użyciu uwierzytelniania opartego na identyfikatorze Entra firmy Microsoft
Uwaga
Ograniczenia podczas odczytywania z zapytania:
- Nie można jednocześnie określić nazwy tabeli i kwerendy.
- Dozwolone są tylko wybrane zapytania. Listy DDL i DML SQL nie są dozwolone.
- Opcje wybierania i filtrowania w ramce danych nie są wypychane do dedykowanej puli SQL po określeniu zapytania.
- Odczyt z zapytania jest dostępny tylko na platformie Spark 3.
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Odczytywanie z tabeli przy użyciu uwierzytelniania podstawowego
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Odczytywanie z zapytania przy użyciu uwierzytelniania podstawowego
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Zapisywanie w dedykowanej puli SQL usługi Azure Synapse
Żądanie zapisu — synapsesql sygnatura metody
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Pisanie przy użyciu uwierzytelniania opartego na identyfikatorze Entra firmy Microsoft
Poniżej znajduje się kompleksowy szablon kodu opisujący sposób używania łącznika do scenariuszy zapisu:
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure Portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
Pisanie przy użyciu uwierzytelniania podstawowego
Poniższy fragment kodu zastępuje definicję zapisu opisaną w sekcji Pisanie przy użyciu uwierzytelniania opartego na identyfikatorze Entra firmy Microsoft, aby przesłać żądanie zapisu przy użyciu podstawowego podejścia do uwierzytelniania SQL:
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
W podejściu do uwierzytelniania podstawowego wymagane jest odczytywanie danych ze źródłowej ścieżki magazynu innych opcji konfiguracji. Poniższy fragment kodu zawiera przykład odczytu ze źródła danych usługi Azure Data Lake Storage Gen2 przy użyciu poświadczeń jednostki usługi:
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
Obsługiwane tryby zapisywania ramki danych
Następujące tryby zapisywania są obsługiwane podczas zapisywania danych źródłowych w tabeli docelowej w dedykowanej puli SQL usługi Azure Synapse:
- ErrorIfExists (domyślny tryb zapisywania)
- Jeśli tabela docelowa istnieje, zapis zostanie przerwany z wyjątkiem zwróconym do obiektu wywoływanego. W przeciwnym razie zostanie utworzona nowa tabela z danymi z folderów przejściowych.
- Ignorować
- Jeśli tabela docelowa istnieje, zapis zignoruje żądanie zapisu bez zwracania błędu. W przeciwnym razie zostanie utworzona nowa tabela z danymi z folderów przejściowych.
- Zastąpić
- Jeśli tabela docelowa istnieje, istniejące dane w miejscu docelowym zostaną zastąpione danymi z folderów przejściowych. W przeciwnym razie zostanie utworzona nowa tabela z danymi z folderów przejściowych.
- Dołączyć
- Jeśli tabela docelowa istnieje, nowe dane zostaną do niej dołączone. W przeciwnym razie zostanie utworzona nowa tabela z danymi z folderów przejściowych.
Obsługa wywołania zwrotnego żądań zapisu
Nowe zmiany interfejsu API ścieżki zapisu wprowadziły funkcję eksperymentalną, aby zapewnić klientowi mapę klucz-wartość> metryk po zapisie. Klucze metryk są definiowane w nowej definicji obiektu — Constants.FeedbackConstants. Metryki można pobrać jako ciąg JSON, przekazując dojście wywołania zwrotnego (a Scala Function). Poniżej znajduje się podpis funkcji:
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
Poniżej przedstawiono kilka godnych uwagi metryk (przedstawionych w przypadku camel):
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
Poniżej znajduje się przykładowy ciąg JSON z metrykami po zapisie:
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
Więcej przykładów kodu
Używanie zmaterializowanych danych między komórkami
Ramki danych platformy createOrReplaceTempView Spark można używać do uzyskiwania dostępu do danych pobranych w innej komórce, rejestrując widok tymczasowy.
- Komórka, w której dane są pobierane (np. z preferencjami języka notesu jako
Scala)
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- Teraz zmień preferencje językowe notesu
PySpark (Python)na i pobierz dane z zarejestrowanego widoku<temporary_view_name>
spark.sql("select * from <temporary_view_name>").show()
Obsługa odpowiedzi
Wywoływanie synapsesql ma dwa możliwe stany końcowe — powodzenie lub stan niepowodzenia. W tej sekcji opisano sposób obsługi odpowiedzi na żądanie dla każdego scenariusza.
Odczytywanie odpowiedzi na żądanie
Po zakończeniu fragment odpowiedzi odczytu jest wyświetlany w danych wyjściowych komórki. Błąd w bieżącej komórce spowoduje również anulowanie kolejnych wykonań komórek. Szczegółowe informacje o błędzie są dostępne w dziennikach aplikacji platformy Spark.
Pisanie odpowiedzi na żądanie
Domyślnie odpowiedź zapisu jest drukowana w danych wyjściowych komórki. Po awarii bieżąca komórka jest oznaczona jako nieudana, a kolejne wykonania komórek zostaną przerwane. Innym podejściem jest przekazanie opcji obsługi wywołania zwrotnego do synapsesql metody . Dojście wywołania zwrotnego zapewni programowy dostęp do odpowiedzi zapisu.
Inne uwagi
- Podczas odczytywania z tabel dedykowanej puli SQL usługi Azure Synapse:
- Rozważ zastosowanie niezbędnych filtrów w ramce danych, aby skorzystać z funkcji oczyszczania kolumn łącznika.
- Scenariusz odczytu nie obsługuje klauzuli
TOP(n-rows)podczas tworzenia ramek instrukcjiSELECTzapytania. Możliwość ograniczenia danych polega na użyciu klauzuli limit(.) ramki danych.- Zapoznaj się z przykładem — używanie zmaterializowanych danych w sekcji komórek .
- Podczas zapisywania w tabelach dedykowanej puli SQL usługi Azure Synapse:
- W przypadku typów tabel wewnętrznych:
- Tabele są tworzone przy użyciu ROUND_ROBIN dystrybucji danych.
- Typy kolumn są wnioskowane z ramki danych, która odczytuje dane ze źródła. Kolumny ciągów są mapowane na
NVARCHAR(4000).
- W przypadku typów tabel zewnętrznych:
- Początkowa równoległość ramki danych napędza organizację danych dla tabeli zewnętrznej.
- Typy kolumn są wnioskowane z ramki danych, która odczytuje dane ze źródła.
- Lepszą dystrybucję danych między funkcjami wykonawczych można osiągnąć przez dostrajanie parametru
spark.sql.files.maxPartitionBytesi ramkirepartitiondanych. - Podczas pisania dużych zestawów danych ważne jest, aby uwzględnić wpływ ustawienia poziomu wydajności jednostek DWU, które ogranicza rozmiar transakcji.
- W przypadku typów tabel wewnętrznych:
- Monitorowanie trendów wykorzystania usługi Azure Data Lake Storage Gen2 w celu wykrycia zachowań ograniczania przepustowości, które mogą mieć wpływ na wydajność odczytu i zapisu.