Korzystanie z platformy .NET for Apache Spark z usługą Azure Synapse Analytics
Platforma .NET dla platformy Apache Spark zapewnia bezpłatną, open source i międzyplatformową obsługę platformy .NET dla platformy Spark.
Udostępnia powiązania platformy .NET dla platformy Spark, które umożliwiają dostęp do interfejsów API platformy Spark za pośrednictwem języków C# i F#. Za pomocą platformy .NET dla platformy Apache Spark można również pisać i wykonywać funkcje zdefiniowane przez użytkownika dla platformy Spark napisane na platformie .NET. Interfejsy API platformy .NET dla platformy Spark umożliwiają dostęp do wszystkich aspektów ramek danych platformy Spark, które ułatwiają analizowanie danych, w tym spark SQL, delta lake i przesyłania strumieniowego ze strukturą.
Dane można analizować za pomocą platformy .NET dla platformy Apache Spark za pomocą definicji zadań wsadowych platformy Spark lub interaktywnych notesów usługi Azure Synapse Analytics. Z tego artykułu dowiesz się, jak używać platformy .NET dla platformy Apache Spark z usługą Azure Synapse przy użyciu obu technik.
Ważne
Platforma .NET dla platformy Apache Spark to projekt open source w programie .NET Foundation, który obecnie wymaga biblioteki .NET 3.1, która osiągnęła stan braku obsługi. Chcemy poinformować użytkowników usługi Azure Synapse Spark o usunięciu biblioteki platformy .NET for Apache Spark w środowisku Uruchomieniowym usługi Azure Synapse dla platformy Apache Spark w wersji 3.3. Aby uzyskać więcej informacji na ten temat, użytkownicy mogą zapoznać się z zasadami pomocy technicznej platformy .NET.
W związku z tym użytkownicy nie będą już mogli korzystać z interfejsów API platformy Apache Spark za pośrednictwem języka C# i F# ani wykonywać kodu C# w notesach w usłudze Synapse lub za pomocą definicji zadań platformy Apache Spark w usłudze Synapse. Należy pamiętać, że ta zmiana ma wpływ tylko na środowisko uruchomieniowe usługi Azure Synapse dla platformy Apache Spark 3.3 lub nowszej.
Będziemy nadal obsługiwać platformę .NET dla platformy Apache Spark we wszystkich poprzednich wersjach środowiska Azure Synapse Runtime zgodnie z ich etapami cyklu życia. Nie mamy jednak planów obsługi platformy .NET dla platformy Apache Spark w środowisku Azure Synapse Runtime dla platformy Apache Spark 3.3 i przyszłych wersji. Zalecamy, aby użytkownicy z istniejącymi obciążeniami napisanymi w języku C# lub F# migrowali do języka Python lub Scala. Użytkownicy powinni zanotować te informacje i odpowiednio zaplanować.
Przesyłanie zadań wsadowych przy użyciu definicji zadania platformy Spark
Odwiedź samouczek, aby dowiedzieć się, jak używać usługi Azure Synapse Analytics do tworzenia definicji zadań platformy Apache Spark dla pul platformy Synapse Spark. Jeśli aplikacja nie została spakowana do przesłania do usługi Azure Synapse, wykonaj następujące kroki.
dotnetSkonfiguruj zależności aplikacji pod kątem zgodności z usługą Synapse Spark. Wymagana wersja platformy .NET Spark zostanie zanotowany w interfejsie programu Synapse Studio w ramach konfiguracji puli platformy Apache Spark w obszarze Przybornik Zarządzanie.
Utwórz projekt jako aplikację konsolową platformy .NET, która generuje plik wykonywalny systemu Ubuntu x86.
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.1</TargetFramework> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.Spark" Version="2.1.0" /> </ItemGroup> </Project>Uruchom następujące polecenia, aby opublikować aplikację. Pamiętaj, aby zastąpić ciąg mySparkApp ścieżką do aplikacji.
cd mySparkApp dotnet publish -c Release -f netcoreapp3.1 -r ubuntu.18.04-x64Spakuj zawartość folderu publikowania,
publish.zipna przykład utworzoną w wyniku kroku 1. Wszystkie zestawy powinny znajdować się w katalogu głównym pliku ZIP i nie powinno być warstwy folderu pośredniego. Oznacza to, że podczas rozpakowywaniapublish.zipwszystkie zestawy są wyodrębniane do bieżącego katalogu roboczego.W systemie Windows:
Za pomocą programu Windows PowerShell lub programu PowerShell 7 utwórz plik zip z zawartości katalogu publikowania.
Compress-Archive publish/* publish.zip -UpdateW systemie Linux:
Otwórz powłokę powłoki bash i dysk cd do katalogu bin ze wszystkimi opublikowanymi plikami binarnymi i uruchom następujące polecenie.
zip -r publish.zip
Platforma .NET dla platformy Apache Spark w notesach usługi Azure Synapse Analytics
Notesy są doskonałym rozwiązaniem do tworzenia prototypów platformy .NET dla potoków i scenariuszy platformy Apache Spark. Możesz rozpocząć pracę z danymi, zrozumieniem, filtrowaniem, wyświetlaniem i wizualizowaniem danych szybko i wydajnie.
Inżynierowie danych, analitycy danych, analitycy biznesowi i inżynierowie uczenia maszynowego mogą współpracować nad udostępnionym, interaktywnym dokumentem. Natychmiastowe wyniki eksploracji danych są widoczne i mogą wizualizować dane w tym samym notesie.
Jak używać platformy .NET dla notesów platformy Apache Spark
Podczas tworzenia nowego notesu wybierasz jądro języka, które chcesz wyrazić logikę biznesową. Obsługa jądra jest dostępna dla kilku języków, w tym języka C#.
Aby użyć platformy .NET dla platformy Apache Spark w notesie usługi Azure Synapse Analytics, wybierz pozycję .NET Spark (C#) jako jądro i dołącz notes do istniejącej bezserwerowej puli platformy Apache Spark.
Notes platformy .NET Spark jest oparty na środowiskach interakcyjnych platformy .NET i zapewnia interaktywne środowiska języka C# z możliwością korzystania z platformy .NET dla platformy Spark z już wstępnie zdefiniowaną zmienną spark sesji platformy Spark.
Instalowanie pakietów NuGet w notesach
Pakiety NuGet można zainstalować w notesie przy użyciu #r nuget polecenia magic przed nazwą pakietu NuGet. Na poniższym diagramie przedstawiono przykład:
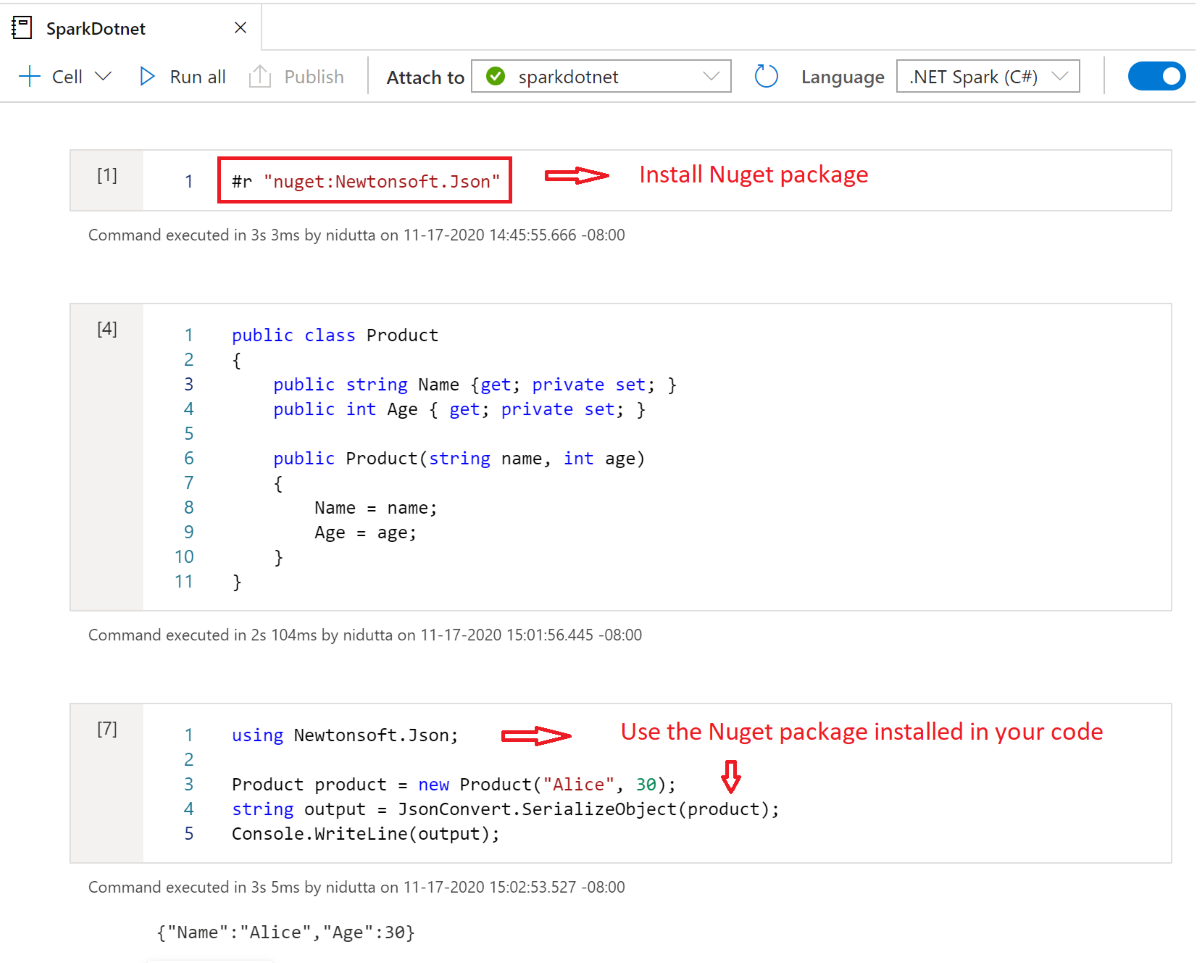
Aby dowiedzieć się więcej o sposobie pracy z pakietami NuGet w notesach, zobacz dokumentację interaktywną platformy .NET.
Platforma .NET dla funkcji jądra języka C# platformy Apache Spark
Podczas korzystania z platformy .NET dla platformy Apache Spark w notesie usługi Azure Synapse Analytics są dostępne następujące funkcje:
- Deklaratywny kod HTML: wygeneruj dane wyjściowe z komórek przy użyciu składni HTML, takiej jak nagłówki, listy punktowane, a nawet wyświetlanie obrazów.
- Proste instrukcje języka C# (takie jak przypisania, drukowanie w konsoli, zgłaszanie wyjątków itd.).
- Wielowierszowe bloki kodu języka C# (takie jak instrukcje if, pętle foreach, definicje klas itd.).
- Dostęp do standardowej biblioteki języka C# (takiej jak System, LINQ, Enumerables itd.).
- Obsługa funkcji języka C# 8.0.
sparkjako wstępnie zdefiniowana zmienna, która zapewnia dostęp do sesji platformy Apache Spark.- Obsługa definiowania funkcji zdefiniowanych przez użytkownika platformy .NET, które można uruchamiać na platformie Apache Spark. Zalecamy pisanie i wywoływanie funkcji zdefiniowanych przez użytkownika na platformie .NET dla środowisk interaktywnych platformy Apache Spark, aby dowiedzieć się, jak używać funkcji zdefiniowanych przez użytkownika na platformie .NET dla środowisk interaktywnych platformy Apache Spark.
- Obsługa wizualizowania danych wyjściowych z zadań platformy Spark przy użyciu różnych wykresów (takich jak linia, słupek lub histogram) i układów (takich jak pojedyncze, nakładane itd.) przy użyciu
XPlot.Plotlybiblioteki. - Możliwość dołączania pakietów NuGet do notesu języka C#.
Rozwiązywanie problemów
DotNetRunner: null / Futures timeout W uruchomieniu definicji zadania platformy Spark w usłudze Synapse Spark
Definicje zadań platformy Synapse Spark w pulach platformy Spark przy użyciu platformy Spark w wersji 2.4 wymagają Microsoft.Spark wersji 1.0.0. bin Wyczyść katalogi i obj i opublikuj projekt przy użyciu wersji 1.0.0.
OutOfMemoryError: przestrzeń sterty java w org.apache.spark
Platforma Dotnet Spark 1.0.0 używa innej architektury debugowania niż 1.1.1+. Konieczne będzie użycie wersji 1.0.0 dla opublikowanej wersji i wersji 1.1.1 lub nowszej na potrzeby debugowania lokalnego.