Zabezpieczenia, dostęp i operacje migracji teradata
Ten artykuł jest trzecią częścią siedmioczęściowej serii, która zawiera wskazówki dotyczące migracji z usługi Teradata do usługi Azure Synapse Analytics. Celem tego artykułu są najlepsze rozwiązania dotyczące operacji dostępu do zabezpieczeń.
Zagadnienia dotyczące zabezpieczeń
W tym artykule omówiono metody połączeń dla istniejących starszych środowisk Teradata oraz sposób ich migracji do usługi Azure Synapse Analytics z minimalnym ryzykiem i wpływem użytkowników.
W tym artykule przyjęto założenie, że istnieje wymóg migrowania istniejących metod połączenia i struktury użytkownika/roli/uprawnień zgodnie z oczekiwaniami. Jeśli nie, użyj witryny Azure Portal, aby utworzyć nowy system zabezpieczeń i zarządzać nim.
Aby uzyskać więcej informacji na temat opcji zabezpieczeń usługi Azure Synapse, zobacz Oficjalny dokument dotyczący zabezpieczeń.
Połączenie i uwierzytelnianie
Opcje autoryzacji teradata
Napiwek
Uwierzytelnianie zarówno w usługach Teradata, jak i Azure Synapse może być "w bazie danych" lub za pośrednictwem metod zewnętrznych.
Usługa Teradata obsługuje kilka mechanizmów nawiązywania połączenia i autoryzacji. Prawidłowe wartości mechanizmu to:
TD1, który wybiera teradata 1 jako mechanizm uwierzytelniania. Wymagana jest nazwa użytkownika i hasło.
TD2, który wybiera teradata 2 jako mechanizm uwierzytelniania. Wymagana jest nazwa użytkownika i hasło.
TDNEGO, który wybiera jeden z mechanizmów uwierzytelniania automatycznie na podstawie zasad, bez udziału użytkownika.
Ldap, który wybiera protokół LDAP (Lightweight Directory Access Protocol) jako mechanizm uwierzytelniania. Aplikacja udostępnia nazwę użytkownika i hasło.
KRB5, który wybiera kerberos (KRB5) na klientach systemu Windows pracujących z serwerami z systemem Windows. Aby zalogować się przy użyciu krB5, użytkownik musi podać domenę, nazwę użytkownika i hasło. Domena jest określana przez ustawienie nazwy użytkownika na
MyUserName@MyDomain.NTLM, który wybiera NTLM na klientach systemu Windows pracujących z serwerami z systemem Windows. Aplikacja udostępnia nazwę użytkownika i hasło.
Protokół Kerberos (KRB5), zgodność protokołu Kerberos (KRB5C), NT LAN Manager (NTLM) i Zgodność nt LAN Manager (NTLMC) są przeznaczone tylko dla systemu Windows.
Opcje autoryzacji usługi Azure Synapse
Usługa Azure Synapse obsługuje dwie podstawowe opcje połączenia i autoryzacji:
Uwierzytelnianie SQL: uwierzytelnianie SQL odbywa się za pośrednictwem połączenia z bazą danych, które zawiera identyfikator bazy danych, identyfikator użytkownika i hasło oraz inne parametry opcjonalne. Jest to funkcjonalnie równoważne połączeniom teradata TD1, TD2 i domyślnym.
Uwierzytelnianie firmy Microsoft Entra: za pomocą uwierzytelniania firmy Microsoft Entra można centralnie zarządzać tożsamościami użytkowników bazy danych i innymi usługi firmy Microsoft w jednej centralnej lokalizacji. Centralne zarządzanie identyfikatorami zapewnia jedno miejsce do zarządzania użytkownikami usługi SQL Data Warehouse i upraszcza zarządzanie uprawnieniami. Identyfikator Entra firmy Microsoft może również obsługiwać połączenia z usługami LDAP i Kerberos — na przykład identyfikator Entra firmy Microsoft może służyć do nawiązywania połączenia z istniejącymi katalogami LDAP, jeśli mają one pozostać w miejscu po migracji bazy danych.
Użytkownicy, role i uprawnienia
Omówienie
Napiwek
Planowanie wysokiego poziomu jest niezbędne dla pomyślnego projektu migracji.
Zarówno Teradata, jak i Azure Synapse implementują kontrolę dostępu do bazy danych za pośrednictwem kombinacji użytkowników, ról i uprawnień. Obie metody używają standardowego języka SQL CREATE USER i CREATE ROLE instrukcji do definiowania użytkowników i ról oraz GRANT REVOKE instrukcji w celu przypisywania lub usuwania uprawnień do tych użytkowników i/lub ról.
Napiwek
Automatyzacja procesów migracji jest zalecana, aby skrócić czas i zakres błędów.
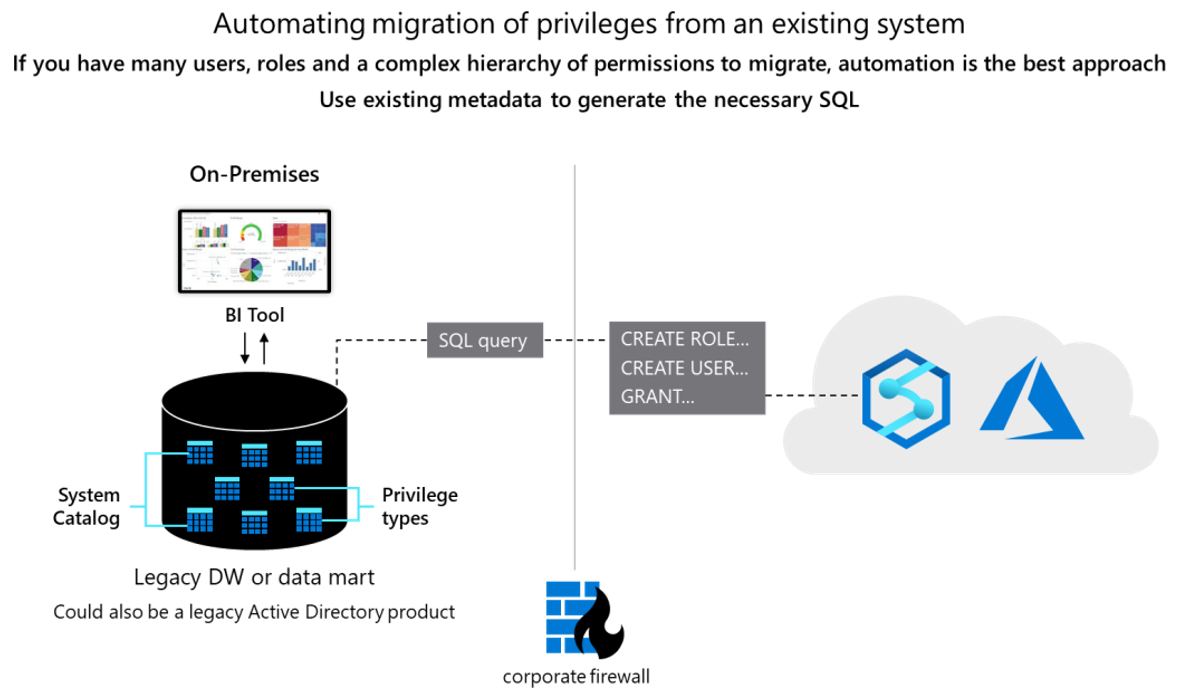
Koncepcyjnie dwie bazy danych są podobne i może być możliwe zautomatyzowanie migracji istniejących identyfikatorów użytkowników, ról i uprawnień do pewnego stopnia. Przeprowadź migrację takich danych, wyodrębniając istniejące informacje o starszej wersji użytkownika i roli z tabel katalogu systemu Teradata i generując pasujące równoważne CREATE USER instrukcje i CREATE ROLE uruchamiane w usłudze Azure Synapse w celu ponownego utworzenia tej samej hierarchii użytkownika/roli.
Po wyodrębnieniu danych użyj tabel wykazu systemu Teradata, aby wygenerować równoważne GRANT instrukcje w celu przypisania uprawnień (gdzie istnieje odpowiednik). Na poniższym diagramie pokazano, jak używać istniejących metadanych do generowania niezbędnego kodu SQL.
Użytkownicy i role
Napiwek
Migracja magazynu danych wymaga więcej niż tylko tabel, widoków i instrukcji SQL.
Informacje o bieżących użytkownikach i rolach w systemie Teradata znajdują się w tabelach DBC.USERS katalogu systemu (lub DBC.DATABASES) i DBC.ROLEMEMBERS. Wykonaj zapytanie dotyczące tych tabel (jeśli użytkownik ma SELECT dostęp do tych tabel), aby uzyskać bieżące listy użytkowników i ról zdefiniowanych w systemie. Poniżej przedstawiono przykłady zapytań, które należy wykonać dla poszczególnych użytkowników:
/***SQL to find all users***/
SELECT
DatabaseName AS UserName
FROM DBC.Databases
WHERE dbkind = 'u';
/***SQL to find all roles***/
SELECT A.ROLENAME, A.GRANTEE, A.GRANTOR,
A.DefaultRole,
A.WithAdmin,
B.DATABASENAME,
B.TABLENAME,
B.COLUMNNAME,
B.GRANTORNAME,
B.AccessRight
FROM DBC.ROLEMEMBERS A
JOIN DBC.ALLROLERIGHTS B
ON A.ROLENAME = B.ROLENAME
GROUP BY 1,2,3,4,5,6,7
ORDER BY 2,1,6;
Te przykłady modyfikują instrukcje SELECT , aby wygenerować zestaw wyników, który jest serią instrukcji CREATE USER i CREATE ROLE , uwzględniając odpowiedni tekst jako literał w instrukcji SELECT .
Nie ma możliwości pobrania istniejących haseł, dlatego należy zaimplementować schemat przydzielania nowych haseł początkowych w usłudze Azure Synapse.
Uprawnienia
Napiwek
Istnieją równoważne uprawnienia usługi Azure Synapse dla podstawowych operacji bazy danych, takich jak DML i DDL.
W systemie Teradata tabele DBC.ALLRIGHTS systemowe i DBC.ALLROLERIGHTS przechowują prawa dostępu dla użytkowników i ról. Wykonaj zapytanie względem tych tabel (jeśli użytkownik ma SELECT dostęp do tych tabel), aby uzyskać bieżące listy praw dostępu zdefiniowanych w systemie. Poniżej przedstawiono przykłady zapytań dla poszczególnych użytkowników:
/**SQL for AccessRights held by a USER***/
SELECT UserName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantAuthority, GrantorName, AllnessFlag, CreatorName, CreateTimeStamp
FROM DBC.ALLRIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE UserName='UserXYZ'
Order By 2,3,4,5;
/**SQL for AccessRights held by a ROLE***/
SELECT RoleName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantorName, CreateTimeStamp
FROM DBC.ALLROLERIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv
Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE RoleName='BI_DEVELOPER'
Order By 2,3,4,5;
Zmodyfikuj te przykładowe SELECT instrukcje, aby utworzyć zestaw wyników, który jest serią instrukcji GRANT , uwzględniając odpowiedni tekst jako literał w instrukcji SELECT .
Użyj tabeli AccessRightsAbbv , aby wyszukać pełny tekst prawa dostępu, ponieważ klucz sprzężenia jest skróconym polem "type". Poniższa tabela zawiera listę praw dostępu teradata i ich odpowiedników w usłudze Azure Synapse.
| Nazwa uprawnienia teradata | Typ teradata | Odpowiednik usługi Azure Synapse |
|---|---|---|
| PRZERWANIE SESJI | AS | ZABIJ POŁĄCZENIE Z BAZĄ DANYCH |
| ALTER EXTERNAL PROCEDURE | AE | 4 |
| ALTER, FUNKCJA | AF | ALTER, FUNKCJA |
| ALTER PROCEDURE | AP | ALTER PROCEDURE |
| PUNKT KONTROLNY | CP | PUNKT KONTROLNY |
| TWORZENIE AUTORYZACJI | CA | CREATE LOGIN |
| CREATE DATABASE | CD | CREATE DATABASE |
| TWORZENIE PROCEDURY ZEWNĘTRZNEJ | CE | 4 |
| CREATE FUNCTION | CF | CREATE FUNCTION |
| TWORZENIE BIBLIOTEKI GLOP | GC | 3 |
| TWORZENIE MAKRA | Chassis Manager (CM) | TWORZENIE PROCEDURY 2 |
| TWORZENIE PROCEDURY WŁAŚCICIELA | OP | TWORZENIE PROCEDURY |
| TWORZENIE PROCEDURY | PC | TWORZENIE PROCEDURY |
| TWORZENIE PROFILU | CO | TWORZENIE IDENTYFIKATORA LOGOWANIA 1 |
| TWORZENIE ROLI | CR | TWORZENIE ROLI |
| DROP DATABASE | DD | DROP DATABASE |
| DROP FUNCTION | DF | DROP FUNCTION |
| DROP GLOP | GD | 3 |
| UPUŚĆ MAKRO | DM | PROCEDURA UPUSZCZANIA 2 |
| PROCEDURA UPUSZCZANIA | PD | PROCEDURA USUWANIA |
| UPUŚĆ PROFIL | DO | DROP LOGIN 1 |
| UPUŚĆ ROLĘ | DR | USUWANIE ROLI |
| DROP TABLE | DT | DROP TABLE |
| WYZWALACZ DROP | DG | 3 |
| UPUŚĆ UŻYTKOWNIKA | DU | UPUŚĆ UŻYTKOWNIKA |
| DROP VIEW | DV | DROP VIEW |
| WYSYPISKO | DP | 4 |
| WYKONAĆ | E | WYKONAJ |
| EXECUTE, FUNKCJA | EF | WYKONAJ |
| PROCEDURA WYKONYWANIA | PE | WYKONAJ |
| CZŁONEK GLOP | GM | 3 |
| INDEKS | IX | CREATE INDEX |
| INSERT | I | INSERT |
| MONRESOURCE | MR | 5 |
| MONSESSION | RN | 5 |
| PRZESŁOŃ OGRANICZENIE ZRZUTU | OA | 4 |
| PRZESŁOŃ OGRANICZENIE PRZYWRACANIA | LUB | 4 |
| ODWOŁANIA | RF | DOKUMENTACJA |
| REPLCONTROL | RO | 5 |
| PRZYWRÓCIĆ | OS | 4 |
| SELECT | R | SELECT |
| SETRESRATE | SR | 5 |
| SETESSRATE | SS | 5 |
| POKAZAĆ | SH | 3 |
| UPDATE | U | UPDATE |
AccessRightsAbbv uwagi dotyczące tabeli:
Teradata
PROFILEjest funkcjonalnie równoważneLOGINw usłudze Azure Synapse.W poniższej tabeli przedstawiono podsumowanie różnic między makrami a procedurami składowanymi w usłudze Teradata. W usłudze Azure Synapse procedury zapewniają funkcjonalność opisaną w tabeli.
Makro Procedura składowana Zawiera sql Zawiera sql Może zawierać polecenia BTEQ dot Zawiera kompleksową usługę SPL Może odbierać przekazane do niego wartości parametrów Może odbierać przekazane do niego wartości parametrów Może pobrać co najmniej jeden wiersz Aby pobrać więcej niż jeden wiersz, należy użyć kursora Przechowywane w przestrzeni PERM bazy danych DBC Przechowywane w BAZIE DANYCH lub PERM UŻYTKOWNIKA Zwraca wiersze do klienta Może zwrócić co najmniej jedną wartość do klienta jako parametry SHOW,GLOPiTRIGGERnie mają bezpośredniego odpowiednika w usłudze Azure Synapse.Te funkcje są zarządzane automatycznie przez system w usłudze Azure Synapse. Zobacz Zagadnienia operacyjne.
W usłudze Azure Synapse te funkcje są obsługiwane poza bazą danych.
Aby uzyskać więcej informacji na temat praw dostępu w usłudze Azure Synapse, zobacz Uprawnienia zabezpieczeń usługi Azure Synapse Analytics.
Zagadnienia operacyjne
Napiwek
Zadania operacyjne są niezbędne do wydajnego działania magazynu danych.
W tej sekcji omówiono sposób implementowania typowych zadań operacyjnych Teradata w usłudze Azure Synapse z minimalnym ryzykiem i wpływem na użytkowników.
Podobnie jak w przypadku wszystkich produktów magazynu danych, gdy w środowisku produkcyjnym istnieją bieżące zadania zarządzania, które są niezbędne do wydajnego działania systemu i zapewnienia danych na potrzeby monitorowania i inspekcji. Wykorzystanie zasobów i planowanie pojemności na potrzeby przyszłego wzrostu również należy do tej kategorii, podobnie jak tworzenie kopii zapasowych/przywracanie danych.
Chociaż koncepcyjnie zadania związane z zarządzaniem i operacjami dla różnych magazynów danych są podobne, poszczególne implementacje mogą się różnić. Ogólnie rzecz biorąc, nowoczesne produkty oparte na chmurze, takie jak Azure Synapse, mają tendencję do uwzględnienia bardziej zautomatyzowanego i "zarządzanego przez system" podejścia (w przeciwieństwie do bardziej "ręcznego" podejścia w starszych magazynach danych, takich jak Teradata).
W poniższych sekcjach porównaliśmy opcje Teradata i Azure Synapse dla różnych zadań operacyjnych.
Zadania sprzątania
Napiwek
Zadania utrzymania domu umożliwiają wydajne działanie magazynu produkcyjnego i optymalizowanie wykorzystania zasobów, takich jak magazyn.
W większości starszych środowisk magazynu danych istnieje wymóg regularnego wykonywania zadań "utrzymania domu", takich jak odzyskiwanie miejsca do magazynowania dysku, które można zwolnić przez usunięcie starych wersji zaktualizowanych lub usuniętych wierszy albo reorganizację plików dziennika danych lub bloków indeksu w celu zapewnienia wydajności. Zbieranie statystyk jest również potencjalnie czasochłonnym zadaniem. Zbieranie statystyk jest wymagane po pozyskiwaniu zbiorczych danych w celu zapewnienia optymalizatora zapytań aktualnych danych do bazowej generacji planów wykonywania zapytań.
Teradata zaleca zbieranie statystyk w następujący sposób:
Zbierz statystyki dotyczące niepopulatowanych tabel, aby skonfigurować histogram interwału używany w przetwarzaniu wewnętrznym. Ta początkowa kolekcja sprawia, że kolejne kolekcje statystyk są szybsze. Pamiętaj, aby ponownie tworzyć statystyki po dodaniu danych.
Zbieranie statystyk fazy prototypu dla nowo wypełnionych tabel.
Zbierz statystyki fazy produkcji po znacznej wartości procentowej zmiany tabeli lub partycji (ok. 10% wierszy). W przypadku dużych ilości wartości niepowiązanych, takich jak daty lub znaczniki czasu, korzystne może być ponowne zbieranie na poziomie 7%.
Zbierz statystyki fazy produkcji po utworzeniu użytkowników i zastosowaniu rzeczywistych obciążeń zapytań do bazy danych (do około trzech miesięcy wykonywania zapytań).
Zbierz statystyki w ciągu pierwszych kilku tygodni po uaktualnieniu lub migracji w okresach niskiego wykorzystania procesora CPU.
Zbieranie statystyk można zarządzać ręcznie przy użyciu otwartych interfejsów API zarządzania statystykami automatycznymi lub automatycznie przy użyciu portletu Programu Teradata Viewpoint Stats Manager.
Napiwek
Automatyzowanie i monitorowanie zadań utrzymywania domu na platformie Azure.
Baza danych Teradata zawiera wiele tabel dzienników w słowniku danych, które gromadzą dane automatycznie lub po włączeniu niektórych funkcji. Ponieważ dane dziennika rosną wraz z upływem czasu, przeczyść starsze informacje, aby uniknąć używania stałego miejsca. Dostępne są opcje automatyzacji konserwacji tych dzienników. Tabele słownika Teradata, które wymagają konserwacji, zostaną omówione w następnej kolejności.
Tabele słowników do obsługi
Resetuj akumulatory i wartości szczytowe przy użyciu DBC.AMPUsage widoku i ClearPeakDisk makra dostarczonego z oprogramowaniem:
DBC.Acctg: użycie zasobów według konta/użytkownikaDBC.DataBaseSpace: ewidencjonowanie przestrzeni bazy danych i tabel
Teradata automatycznie utrzymuje te tabele, ale dobre rozwiązania mogą zmniejszyć ich rozmiar:
DBC.AccessRights: prawa użytkownika do obiektówDBC.RoleGrants: prawa roli do obiektówDBC.Roles: zdefiniowane roleDBC.Accounts: kody kont według użytkownika
Zarchiwizuj te tabele rejestrowania (w razie potrzeby) i przeczyść informacje 60–90 dni. Przechowywanie zależy od wymagań klienta:
DBC.SW_Event_Log: dziennik konsoli bazy danychDBC.ResUsage: tabele monitorowania zasobówDBC.EventLog: historia logowania/wylogowania sesjiDBC.AccLogTbl: zarejestrowane zdarzenia użytkownika/obiektuDBC.DBQL tables: zarejestrowane działanie użytkownika/sql.NETSecPolicyLogTbl: rejestruje dzienniki dzienników inspekcji zasad zabezpieczeń dynamicznych.NETSecPolicyLogRuleTbl: kontroluje, kiedy i jak są rejestrowane dynamiczne zasady zabezpieczeń
Przeczyść te tabele, gdy skojarzony nośnik wymienny wygasł i zastąpiony:
DBC.RCEvent: zdarzenia archiwum/odzyskiwaniaDBC.RCConfiguration: konfiguracja archiwum/odzyskiwaniaDBC.RCMedia: VolSerial do archiwizacji/odzyskiwania
Usługa Azure Synapse ma możliwość automatycznego tworzenia statystyk, dzięki czemu mogą być używane zgodnie z potrzebami. Wykonaj defragmentację indeksów i bloków danych ręcznie, zgodnie z harmonogramem lub automatycznie. Wykorzystanie natywnych wbudowanych funkcji platformy Azure może zmniejszyć nakład pracy wymagany w ćwiczeniu migracji.
Monitorowanie i inspekcja
Napiwek
W czasie zaimplementowano kilka różnych narzędzi w celu umożliwienia monitorowania i rejestrowania systemów Teradata.
Teradata udostępnia kilka narzędzi do monitorowania operacji, w tym Teradata Viewpoint i Ecosystem Manager. W przypadku historii zapytań rejestrowania dziennik zapytań bazy danych (DBQL) to funkcja bazy danych Teradata, która udostępnia szereg wstępnie zdefiniowanych tabel, które mogą przechowywać historyczne rekordy zapytań oraz ich czas trwania, wydajność i działanie docelowe na podstawie reguł zdefiniowanych przez użytkownika.
Administratorzy baz danych mogą używać widoku teradata do określania stanu systemu, trendów i stanu poszczególnych zapytań. Obserwując trendy w zakresie użycia systemu, administratorzy systemu mogą lepiej planować implementacje projektów, zadania wsadowe i konserwację, aby uniknąć okresów szczytowych użycia. Użytkownicy biznesowi mogą używać widoku teradata, aby szybko uzyskać dostęp do stanu raportów i zapytań oraz przejść do szczegółów.
Napiwek
Witryna Azure Portal udostępnia interfejs użytkownika do zarządzania zadaniami monitorowania i inspekcji dla wszystkich danych i procesów platformy Azure.
Podobnie usługa Azure Synapse udostępnia zaawansowane środowisko monitorowania w witrynie Azure Portal, aby zapewnić wgląd w obciążenie magazynu danych. Witryna Azure Portal jest zalecanym narzędziem do monitorowania magazynu danych, ponieważ zapewnia konfigurowalne okresy przechowywania, alerty, zalecenia i dostosowywalne wykresy i pulpity nawigacyjne dla metryk i dzienników.
Portal umożliwia również integrację z innymi usługami monitorowania platformy Azure, takimi jak Operations Management Suite (OMS) i Azure Monitor (dzienniki), aby zapewnić całościowe środowisko monitorowania nie tylko dla magazynu danych, ale także całej platformy analizy Azure na potrzeby zintegrowanego środowiska monitorowania.
Napiwek
Metryki niskiego poziomu i całego systemu są automatycznie rejestrowane w usłudze Azure Synapse.
Statystyki wykorzystania zasobów dla usługi Azure Synapse są automatycznie rejestrowane w systemie. Metryki dla każdego zapytania obejmują statystyki użycia procesora CPU, pamięci, pamięci podręcznej, operacji we/wy i tymczasowego obszaru roboczego, a także informacje o łączności, takie jak nieudane próby połączenia.
Usługa Azure Synapse udostępnia zestaw dynamicznych widoków zarządzania (DMV). Te widoki są przydatne podczas aktywnego rozwiązywania problemów i identyfikowania wąskich gardeł wydajności w obciążeniu.
Aby uzyskać więcej informacji, zobacz Azure Synapse operations and management options (Operacje i opcje zarządzania w usłudze Azure Synapse).
Wysoka dostępność (HA) i odzyskiwanie po awarii (DR)
Teradata implementuje funkcje, takie jak FALLBACK, narzędzie do przywracania archiwum (ARC) i architektura strumienia danych (DSA), aby zapewnić ochronę przed utratą danych i wysoką dostępnością za pośrednictwem replikacji i archiwizacji danych. Opcje odzyskiwania po awarii obejmują podwójne aktywne rozwiązanie, odzyskiwanie po awarii jako usługę lub system zastępczy w zależności od wymagania dotyczącego czasu odzyskiwania.
Napiwek
Usługa Azure Synapse automatycznie tworzy migawki w celu zapewnienia szybkiego czasu odzyskiwania.
Usługa Azure Synapse używa migawek baz danych w celu zapewnienia wysokiej dostępności magazynu. Migawka magazynu danych tworzy punkt przywracania, którego można użyć do odzyskania lub skopiowania magazynu danych do poprzedniego stanu. Ponieważ usługa Azure Synapse jest systemem rozproszonym, migawka magazynu danych składa się z wielu plików, które znajdują się w usłudze Azure Storage. Migawki przechwytują przyrostowe zmiany danych przechowywanych w magazynie danych.
Usługa Azure Synapse automatycznie tworzy migawki przez cały dzień, tworząc punkty przywracania, które są dostępne przez siedem dni. Nie można zmienić tego okresu przechowywania. Usługa Azure Synapse obsługuje ośmiogodzinny cel punktu odzyskiwania (RPO). Magazyn danych można przywrócić w regionie podstawowym z dowolnej migawki wykonanej w ciągu ostatnich siedmiu dni.
Napiwek
Użyj migawek zdefiniowanych przez użytkownika, aby zdefiniować punkt odzyskiwania przed aktualizacjami klucza.
Obsługiwane są również punkty przywracania zdefiniowane przez użytkownika, co umożliwia ręczne wyzwalanie migawek w celu utworzenia punktów przywracania magazynu danych przed dużymi modyfikacjami. Ta funkcja gwarantuje, że punkty przywracania są logicznie spójne, co zapewnia dodatkową ochronę danych w przypadku przerw w obciążeniu lub błędów użytkownika dla żądanego celu punktu odzyskiwania krótszego niż 8 godzin.
Napiwek
Platforma Microsoft Azure udostępnia automatyczne kopie zapasowe do oddzielnej lokalizacji geograficznej w celu włączenia odzyskiwania po awarii.
Oprócz opisanych wcześniej migawek usługa Azure Synapse również wykonuje standardowa geograficzną kopię zapasową raz dziennie w sparowanym centrum danych. Cel punktu odzyskiwania dla przywracania geograficznego wynosi 24 godziny. Możesz przywrócić geograficzną kopię zapasową na serwer w dowolnym innym regionie, w którym jest obsługiwana usługa Azure Synapse. Geograficzna kopia zapasowa gwarantuje, że magazyn danych można przywrócić w przypadku niedostępności punktów przywracania w regionie podstawowym.
Zarządzanie obciążeniami
Napiwek
W magazynie danych produkcyjnych zwykle występują mieszane obciążenia z różnymi charakterystykami użycia zasobów uruchomionymi współbieżnie.
Obciążenie to klasa żądań bazy danych o typowych cechach, których dostęp do bazy danych można zarządzać za pomocą zestawu reguł. Obciążenia są przydatne w następujących celach:
Ustawianie różnych priorytetów dostępu dla różnych typów żądań.
Monitorowanie wzorców użycia zasobów, dostrajanie wydajności i planowanie pojemności.
Ograniczenie liczby żądań lub sesji, które mogą być uruchamiane w tym samym czasie.
W systemie Teradata zarządzanie obciążeniami jest działaniem zarządzania wydajnością obciążenia przez monitorowanie aktywności systemu i działanie w przypadku osiągnięcia wstępnie zdefiniowanych limitów. Zarządzanie obciążeniami używa reguł, a każda reguła ma zastosowanie tylko do niektórych żądań bazy danych. Jednak kolekcja wszystkich reguł ma zastosowanie do wszystkich aktywnych prac na platformie. Usługa Teradata Active System Management (TASM) wykonuje pełne zarządzanie obciążeniami w bazie danych Teradata Database.
W usłudze Azure Synapse klasy zasobów są wstępnie określonymi limitami zasobów, które zarządzają zasobami obliczeniowymi i współbieżnością na potrzeby wykonywania zapytań. Klasy zasobów mogą ułatwić zarządzanie obciążeniem, ustawiając limity liczby zapytań uruchamianych współbieżnie i zasobów obliczeniowych przypisanych do każdego zapytania. Istnieje kompromis między pamięcią a współbieżnością.
Usługa Azure Synapse automatycznie rejestruje statystyki wykorzystania zasobów. Metryki obejmują statystyki użycia procesora CPU, pamięci, pamięci podręcznej, operacji we/wy i tymczasowego obszaru roboczego dla każdego zapytania. Usługa Azure Synapse rejestruje również informacje o łączności, takie jak nieudane próby połączenia.
Napiwek
Metryki niskiego poziomu i całego systemu są automatycznie rejestrowane na platformie Azure.
Usługa Azure Synapse obsługuje następujące podstawowe pojęcia dotyczące zarządzania obciążeniami:
Klasyfikacja obciążeń: możesz przypisać żądanie do grupy obciążeń w celu ustawienia poziomów ważności.
Ważność obciążenia: możesz wpływać na kolejność, w jakiej żądanie uzyskuje dostęp do zasobów. Domyślnie zapytania są zwalniane z kolejki w pierwszej kolejności, gdy zasoby stają się dostępne. Ważność obciążenia umożliwia wykonywanie zapytań o wyższym priorytcie natychmiast odbierać zasoby niezależnie od kolejki.
Izolacja obciążenia: możesz zarezerwować zasoby dla grupy obciążeń, przypisać maksymalne i minimalne użycie dla różnych zasobów, ograniczyć zasoby, z których może korzystać grupa żądań, i ustawić wartość limitu czasu, aby automatycznie zabić zapytania uruchamiania.
Uruchamianie mieszanych obciążeń może stanowić wyzwanie dla zasobów w systemach zajętych. Pomyślny schemat zarządzania obciążeniami skutecznie zarządza zasobami, zapewnia wysoce wydajne wykorzystanie zasobów i maksymalizuje zwrot z inwestycji (ROI). Klasyfikacja obciążeń, ważność obciążenia i izolacja obciążenia zapewnia większą kontrolę nad sposobem korzystania z zasobów systemowych przez obciążenie.
W przewodniku zarządzania obciążeniami opisano techniki analizowania obciążenia, zarządzania i monitorowania ważności obciążenia](.. /.. /sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md) oraz kroki konwertowania klasy zasobów na grupę obciążeń. Użyj witryny Azure Portal i zapytań T-SQL w widokach DMV, aby monitorować obciążenie w celu zapewnienia efektywnego wykorzystania odpowiednich zasobów. Usługa Azure Synapse udostępnia zestaw dynamicznych widoków zarządzania (DMV) do monitorowania wszystkich aspektów zarządzania obciążeniami. Te widoki są przydatne podczas aktywnego rozwiązywania problemów i identyfikowania wąskich gardeł wydajności w obciążeniu.
Te informacje mogą być również używane do planowania pojemności, określania zasobów wymaganych dla dodatkowych użytkowników lub obciążeń aplikacji. Dotyczy to również planowania skalowania w górę/w dół zasobów obliczeniowych w celu ekonomicznego wsparcia obciążeń "szczytowych".
Aby uzyskać więcej informacji na temat zarządzania obciążeniami w usłudze Azure Synapse, zobacz Zarządzanie obciążeniami przy użyciu klas zasobów.
Skalowanie zasobów obliczeniowych
Napiwek
Główną zaletą platformy Azure jest możliwość niezależnego skalowania zasobów obliczeniowych w górę i w dół na żądanie w celu efektywnego obsługi obciążeń szczytowych.
Architektura usługi Azure Synapse oddziela magazyn i zasoby obliczeniowe, co pozwala na niezależne skalowanie każdego z nich. W związku z tym zasoby obliczeniowe można skalować w celu spełnienia wymagań dotyczących wydajności niezależnie od magazynu danych. Można również wstrzymywać i wznawiać działanie zasobów obliczeniowych. Naturalną zaletą tej architektury jest to, że rozliczenia dla zasobów obliczeniowych i magazynu są oddzielne. Jeśli magazyn danych nie jest używany, możesz zaoszczędzić na kosztach obliczeń, wstrzymując obliczenia.
Zasoby obliczeniowe można skalować w górę lub skalować z powrotem, dostosowując ustawienie jednostek magazynu danych dla magazynu danych. Wydajność ładowania i wykonywania zapytań zwiększa się liniowo w miarę dodawania większej liczby jednostek magazynu danych.
Dodanie większej liczby węzłów obliczeniowych zwiększa moc obliczeniową i możliwość korzystania z bardziej przetwarzania równoległego. Wraz ze wzrostem liczby węzłów obliczeniowych liczba dystrybucji na węzeł obliczeniowy zmniejsza się, zapewniając większą moc obliczeniową i przetwarzanie równoległe zapytań. Podobnie zmniejszenie liczby jednostek magazynu danych zmniejsza liczbę węzłów obliczeniowych, co zmniejsza zasoby obliczeniowe zapytań.
Następne kroki
Aby dowiedzieć się więcej na temat wizualizacji i raportowania, zobacz następny artykuł z tej serii: Wizualizacja i raportowanie migracji teradata.