Jak używać replikacji apache Hive w klastrach usługi Azure HDInsight
W kontekście baz danych i magazynów replikacja to proces duplikowania jednostek z jednego magazynu do innego. Duplikowanie może dotyczyć całej bazy danych lub mniejszego poziomu, takiego jak tabela lub partycja. Celem jest posiadanie repliki, która zmienia się za każdym razem, gdy zmienia się jednostka podstawowa. Replikacja w usłudze Apache Hive koncentruje się na odzyskiwaniu po awarii i oferuje jednokierunkową replikację kopii podstawowej. W klastrach usługi HDInsight replikacja Hive może służyć do jednokierunkowego replikowania magazynu metadanych Hive i skojarzonego podstawowego magazynu danych w usłudze Azure Data Lake Storage Gen2.
Replikacja Hive ewoluowała od lat wraz z nowszymi wersjami, zapewniając lepszą funkcjonalność i szybsze i mniej intensywnie korzystające z zasobów. W tym artykule omówiono replikację (Replv2) hive obsługiwaną zarówno w usługach HDInsight 3.6, jak i HDInsight 4.0.
Zalety replv2
Replikacja HiveV2 (nazywana Replv2również ) ma następujące zalety w porównaniu z pierwszą wersją replikacji programu Hive, która korzystała z programu Hive IMPORT-EXPORT:
- Replikacja przyrostowa oparta na zdarzeniach
- Replikacja do punktu w czasie
- Wymagania dotyczące mniejszej przepustowości
- Zmniejszenie liczby kopii pośrednich
- Stan replikacji jest utrzymywany
- Replikacja ograniczona
- Obsługa modelu piasty i szprych
- Obsługa tabel ACID (w usłudze HDInsight 4.0)
Fazy replikacji
Replikacja oparta na zdarzeniach programu Hive jest konfigurowana między klastrami podstawowymi i pomocniczymi. Ta replikacja składa się z dwóch odrębnych faz: uruchamiania i uruchamiania przyrostowego.
Bootstrap
Uruchamianie bootstrapping ma być uruchamiane raz w celu replikowania podstawowego stanu baz danych z podstawowej do pomocniczej. W razie potrzeby można skonfigurować uruchamianie, aby uwzględnić podzbiór tabel w docelowej bazie danych, w której należy włączyć replikację.
Uruchomienia przyrostowe
Po uruchomieniu uruchamiania przebiegi przyrostowe są zautomatyzowane w klastrze podstawowym, a zdarzenia generowane podczas tych przebiegów przyrostowych są odtwarzane w klastrze pomocniczym. Gdy klaster pomocniczy dogoni klaster podstawowy, pomocniczy staje się spójny ze zdarzeniami podstawowymi.
Polecenia replikacji
Usługa Hive oferuje zestaw poleceń REPL — DUMP, LOADi STATUS — do organizowania przepływu zdarzeń. Polecenie DUMP generuje lokalny dziennik wszystkich zdarzeń DDL/DML w klastrze podstawowym. Polecenie LOAD to podejście do leniwego kopiowania metadanych i danych rejestrowanych do wyodrębnionych danych wyjściowych zrzutu replikacji i jest wykonywane w klastrze docelowym. Polecenie STATUS jest uruchamiane z klastra docelowego, aby podać najnowszy identyfikator zdarzenia, że najnowsze obciążenie replikacji zostało pomyślnie zreplikowane.
Ustawianie źródła replikacji
Przed rozpoczęciem replikacji upewnij się, że baza danych, która ma zostać zreplikowana, jest ustawiona jako źródło replikacji. Możesz użyć DESC DATABASE EXTENDED <db_name> polecenia , aby określić, czy parametr repl.source.for jest ustawiony z nazwą zasad.
Jeśli zasady są zaplanowane i repl.source.for parametr nie jest ustawiony, należy najpierw ustawić ten parametr przy użyciu polecenia ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>').
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
Zrzut metadanych do usługi Data Lake
Polecenie REPL DUMP [database name]. => location / event_id jest używane w fazie uruchamiania, aby zrzucić odpowiednie metadane do usługi Azure Data Lake Storage Gen2. Określa event_id minimalne zdarzenie, do którego zostały wprowadzone odpowiednie metadane w usłudze Azure Data Lake Storage Gen2.
repl dump tpcds_orc;
Przykładowe wyjście:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
Ładowanie danych do klastra docelowego
Polecenie REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) } służy do ładowania danych do klastra docelowego zarówno dla fazy uruchamiania, jak i przyrostowej replikacji. Może [database name] być taka sama jak źródło lub inna nazwa w klastrze docelowym. Obiekt [location] reprezentuje lokalizację z danych wyjściowych wcześniejszego REPL DUMP polecenia. Oznacza to, że klaster docelowy powinien mieć możliwość komunikacji z klastrem źródłowym. Klauzula WITH została dodana przede wszystkim, aby zapobiec ponownemu uruchomieniu klastra docelowego, zezwalając na replikację.
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
Wyprowadza ostatni zreplikowany identyfikator zdarzenia
Polecenie REPL STATUS [database name] jest wykonywane w klastrach docelowych i zwraca ostatnio zreplikowany event_idelement . Polecenie umożliwia również użytkownikom poznanie stanu replikowanego przez klaster docelowy. Możesz użyć danych wyjściowych tego polecenia, aby skonstruować następne REPL DUMP polecenie na potrzeby replikacji przyrostowej.
repl status tpcds_orc;
Przykładowe wyjście:
| last_repl_id |
|---|
| 2925 |
Duplikuj odpowiednie dane i metadane do usługi Data Lake
Polecenie REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } służy do zrzutu odpowiednich metadanych i danych do usługi Azure Data Lake Storage. To polecenie jest używane w fazie przyrostowej i jest uruchamiane w magazynie źródłowym. Parametr FROM [event-id] jest wymagany dla fazy przyrostowej, a wartość parametru event-id może być pochodna przez uruchomienie REPL STATUS [database name] polecenia w magazynie docelowym.
repl dump tpcds_orc from 2925;
Przykładowe wyjście:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46646agadd0 | 2960 |
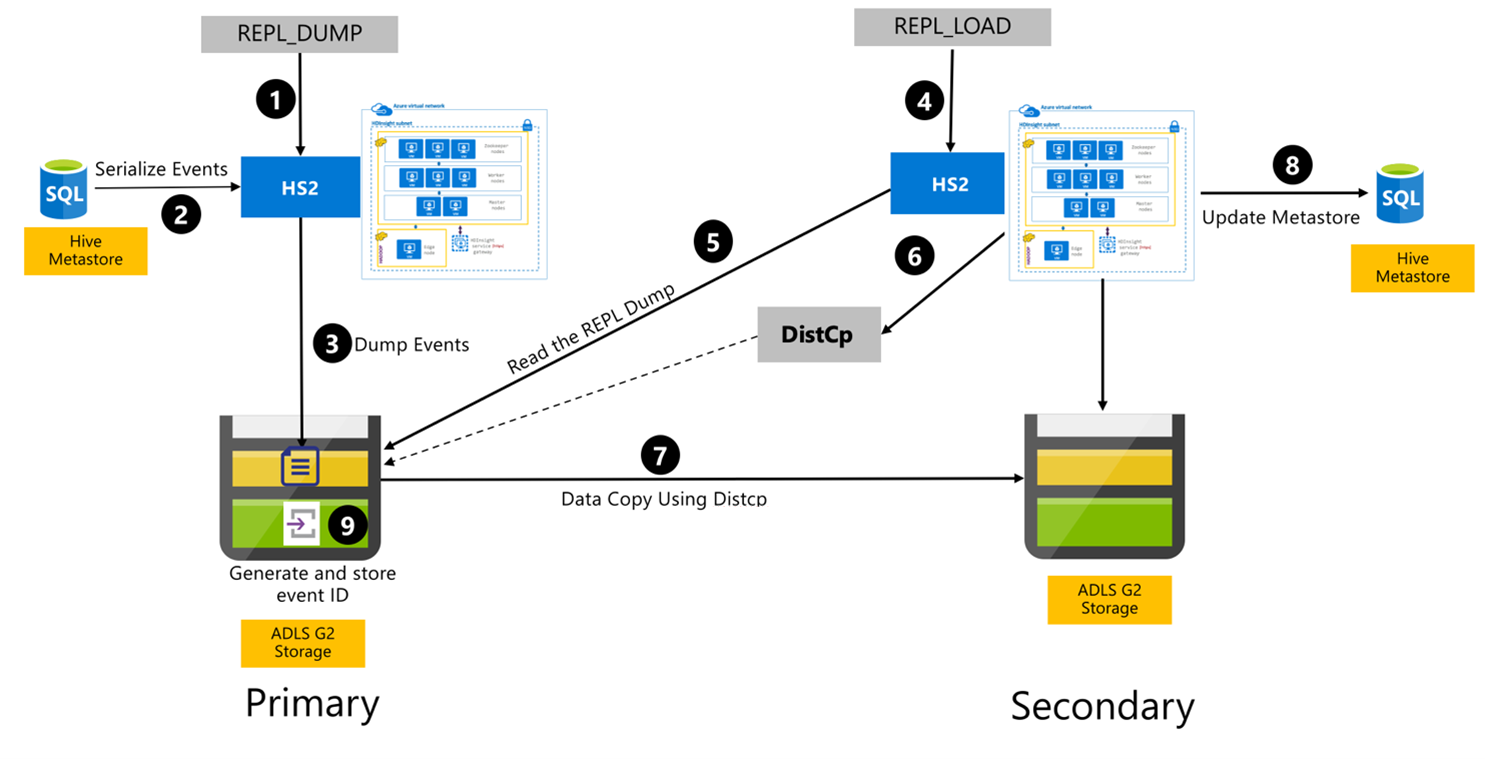
Proces replikacji programu Hive
Poniższe kroki to sekwencyjne zdarzenia, które mają miejsce podczas procesu replikacji programu Hive.
Upewnij się, że tabele do replikacji są ustawione jako źródło replikacji dla określonych zasad.
Polecenie
REPL_DUMPjest wydawane klastrowi podstawowemu ze skojarzonymi ograniczeniami, takimi jak nazwa bazy danych, zakres identyfikatorów zdarzeń i adres URL magazynu usługi Azure Data Lake Storage Gen2.System serializuje zrzut wszystkich śledzonych zdarzeń z magazynu metadanych do najnowszego. Ten zrzut jest przechowywany na koncie magazynu usługi Azure Data Lake Storage Gen2 w klastrze podstawowym pod adresem URL określonym przez .
REPL_DUMPKlaster podstawowy utrwala metadane replikacji w magazynie usługi Azure Data Lake Storage Gen2 klastra podstawowego. Ścieżka jest konfigurowalna w interfejsie użytkownika konfiguracji programu Hive w systemie Ambari. Proces zawiera ścieżkę, w której są przechowywane metadane, oraz identyfikator najnowszego śledzonego zdarzenia DML/DDL.
Polecenie
REPL_LOADjest wydawane z klastra pomocniczego. Polecenie wskazuje ścieżkę skonfigurowaną w kroku 3.Klaster pomocniczy odczytuje plik metadanych ze śledzonymi zdarzeniami utworzonymi w kroku 3. Upewnij się, że klaster pomocniczy ma łączność sieciową z magazynem usługi Azure Data Lake Storage Gen2 klastra podstawowego, z
REPL_DUMPktórego są przechowywane śledzone zdarzenia.Klaster pomocniczy duplikuje zasoby obliczeniowe kopii rozproszonej (
DistCP).Klaster pomocniczy kopiuje dane z magazynu klastra podstawowego.
Magazyn metadanych w klastrze pomocniczym jest aktualizowany.
Ostatni śledzony identyfikator zdarzenia jest przechowywany w podstawowym magazynie metadanych.
Replikacja przyrostowa jest zgodna z tym samym procesem i wymaga ostatniego zreplikowanego identyfikatora zdarzenia jako danych wejściowych. Prowadzi to do przyrostowej kopii od ostatniego zdarzenia replikacji. Replikacje przyrostowe są zwykle zautomatyzowane przy użyciu wstępnie ustalonej częstotliwości w celu osiągnięcia wymaganych celów punktu odzyskiwania (RPO).
Wzorce replikacji
Replikacja jest zwykle konfigurowana w sposób jednokierunkowy między podstawową i pomocniczą, gdzie podstawowe elementy zaspokajają żądania odczytu i zapisu. Klaster pomocniczy obsługuje tylko żądania odczytu. Zapisy są dozwolone w pomocniczym przypadku awarii, ale replikacja odwrotna musi zostać skonfigurowana z powrotem do podstawowego.
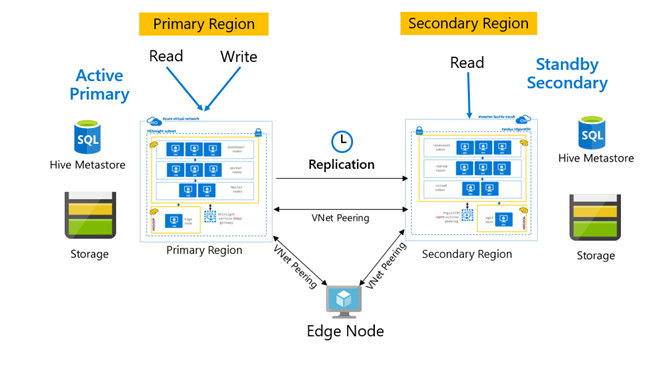
Istnieje wiele wzorców odpowiednich do replikacji hive, w tym podstawowej — pomocniczej, piasty i szprychy oraz przekaźnika.
W usłudze HDInsight Active Primary — Rezerwa pomocnicza jest typowym wzorcem ciągłości działania i odzyskiwania po awarii (BCDR), a klaster HiveReplicationV2 może używać tego wzorca z regionalnie oddzielonymi klastrami usługi HDInsight Hadoop z komunikacją równorzędną sieci wirtualnych. Typowa maszyna wirtualna równorzędna z obydwoma klastrami może służyć do hostowania skryptów automatyzacji replikacji. Aby uzyskać więcej informacji na temat możliwych wzorców BCDR usługi HDInsight, zapoznaj się z dokumentacją dotyczącą ciągłości działania usługi HDInsight.
Replikacja programu Hive z pakietem Enterprise Security
W przypadkach, gdy replikacja Hive jest planowana w klastrach usługi HDInsight Hadoop z pakietem Enterprise Security, należy uwzględnić mechanizmy replikacji dla magazynu metadanych Ranger i usług Microsoft Entra Domain Services.
Użyj funkcji zestawów replik usług Microsoft Entra Domain Services, aby utworzyć więcej niż jeden zestaw replik usług Microsoft Entra Domain Services dla dzierżawy firmy Microsoft Entra w wielu regionach. Każdy zestaw replik musi być równorzędny z sieciami wirtualnymi usługi HDInsight w odpowiednich regionach. W tej konfiguracji zmiany w usługach Microsoft Entra Domain Services, w tym konfiguracja, tożsamość użytkownika i poświadczenia, grupy, obiekty zasad grupy, obiekty komputera i inne zmiany są stosowane do wszystkich zestawów replik w domenie zarządzanej przy użyciu replikacji usług Microsoft Entra Domain Services.
Zasady platformy Ranger mogą być okresowo tworzone i replikowane z podstawowego do pomocniczego przy użyciu funkcji Ranger Import-Export. Możesz wybrać replikację wszystkich lub podzestaw zasad platformy Ranger w zależności od poziomu autoryzacji, które chcesz zaimplementować w klastrze pomocniczym.
Przykładowy kod
Poniższa sekwencja kodu zawiera przykład sposobu implementacji replikacji początkowej i przyrostowej w przykładowej tabeli o nazwie tpcds_orc.
Ustaw tabelę jako źródło zasad replikacji.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');Zrzut bootstrap w klastrze podstawowym.
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');Przykładowe wyjście:
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 Ładowanie bootstrap w klastrze pomocniczym.
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';REPLSprawdź stan w klastrze pomocniczym.repl status tpcds_orc;last_repl_id 2925 Przyrostowy zrzut w klastrze podstawowym.
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');Przykładowe wyjście:
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 Obciążenie przyrostowe w klastrze pomocniczym.
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';Sprawdź
REPLstan w klastrze pomocniczym.repl status tpcds_orc;last_repl_id 2960
Następne kroki
Aby dowiedzieć się więcej o elementach omówionych w tym artykule, zobacz: