Definiowanie i uruchamianie przepływu pracy w opartej na systemie Linux usłudze Azure HDInsight za pomocą programu Apache Oozie z narzędziem Apache Hadoop
Dowiedz się, jak używać rozwiązania Apache Oozie z usługą Apache Hadoop w usłudze Azure HDInsight. Oozie to system przepływu pracy i koordynacji, który zarządza zadaniami usługi Hadoop. Rozwiązanie Oozie jest zintegrowane ze stosem usługi Hadoop i obsługuje następujące zadania:
- Apache Hadoop MapReduce
- Apache Pig
- Apache Hive
- Apache Sqoop
Możesz również użyć usługi Oozie do planowania zadań specyficznych dla systemu, takich jak programy Java lub skrypty powłoki.
Uwaga
Inną opcją definiowania przepływów pracy w usłudze HDInsight jest użycie usługi Azure Data Factory. Aby dowiedzieć się więcej o usłudze Data Factory, zobacz Używanie technologii Apache Pig i Apache Hive z usługą Data Factory. Aby użyć rozwiązania Oozie w klastrach z pakietem Enterprise Security, zobacz Uruchamianie rozwiązania Apache Oozie w klastrach hadoop usługi HDInsight z pakietem Enterprise Security.
Wymagania wstępne
Klaster Hadoop w usłudze HDInsight. Zobacz Wprowadzenie do usługi HDInsight w systemie Linux.
Klient SSH. Zobacz Nawiązywanie połączenia z usługą HDInsight (Apache Hadoop) przy użyciu protokołu SSH.
Azure SQL Database. Zobacz Tworzenie bazy danych w usłudze Azure SQL Database w witrynie Azure Portal. W tym artykule jest używana baza danych o nazwie oozietest.
Schemat identyfikatora URI dla magazynu podstawowego klastrów.
wasb://dla usługi Azure Storage dlaabfs://usługi Azure Data Lake Storage Gen2 lubadl://usługi Azure Data Lake Storage Gen1. Jeśli bezpieczny transfer jest włączony dla usługi Azure Storage, identyfikator URI towasbs://. Zobacz również bezpieczny transfer.
Przykładowy przepływ pracy
Przepływ pracy używany w tym dokumencie zawiera dwie akcje. Akcje to definicje zadań, takich jak uruchamianie programu Hive, Sqoop, MapReduce lub innych procesów:
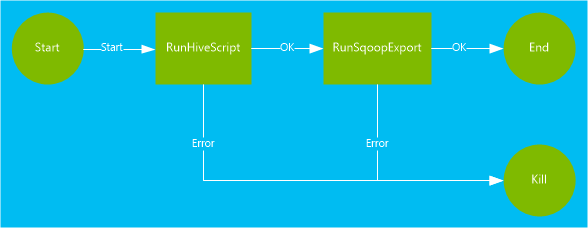
Akcja programu Hive uruchamia skrypt HiveQL w celu wyodrębnienia rekordów z elementu dołączonego
hivesampletabledo usługi HDInsight. Każdy wiersz danych opisuje wizytę z określonego urządzenia przenośnego. Format rekordu jest wyświetlany podobnie do następującego tekstu:8 18:54:20 en-US Android Samsung SCH-i500 California United States 13.9204007 0 0 23 19:19:44 en-US Android HTC Incredible Pennsylvania United States NULL 0 0 23 19:19:46 en-US Android HTC Incredible Pennsylvania United States 1.4757422 0 1Skrypt hive używany w tym dokumencie zlicza łączną liczbę wizyt dla każdej platformy, takiej jak Android lub iPhone, i przechowuje liczby do nowej tabeli Programu Hive.
Aby uzyskać więcej informacji na temat programu Hive, zobacz [Use Apache Hive with HDInsight][hdinsight-use-hive].
Akcja Sqoop eksportuje zawartość nowej tabeli Programu Hive do tabeli utworzonej w usłudze Azure SQL Database. Aby uzyskać więcej informacji na temat narzędzia Sqoop, zobacz Use Apache Sqoop with HDInsight (Używanie narzędzia Apache Sqoop z usługą HDInsight).
Uwaga
Aby uzyskać informacje o obsługiwanych wersjach Oozie w klastrach usługi HDInsight, zobacz Co nowego w wersjach klastra Hadoop udostępnianych przez usługę HDInsight.
Tworzenie katalogu roboczego
Oozie oczekuje, że wszystkie zasoby wymagane dla zadania będą przechowywane w tym samym katalogu. W tym przykładzie użyto wartości wasbs:///tutorials/useoozie. Aby utworzyć ten katalog, wykonaj następujące kroki:
Zmodyfikuj poniższy kod, aby zastąpić
sshuserciąg nazwą użytkownika SSH klastra, a następnie zastąpCLUSTERNAMEciąg nazwą klastra. Następnie wprowadź kod, aby nawiązać połączenie z klastrem usługi HDInsight przy użyciu protokołu SSH.ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netAby utworzyć katalog, użyj następującego polecenia:
hdfs dfs -mkdir -p /tutorials/useoozie/dataUwaga
Parametr
-ppowoduje utworzenie wszystkich katalogów w ścieżce. Katalogdatajest używany do przechowywania danych używanychuseooziewf.hqlprzez skrypt.Edytuj poniższy kod, aby zastąpić
sshuserciąg nazwą użytkownika SSH. Aby upewnić się, że usługa Oozie może personifikować konto użytkownika, użyj następującego polecenia:sudo adduser sshuser usersUwaga
Możesz zignorować błędy wskazujące, że użytkownik jest już członkiem
usersgrupy.
Dodawanie sterownika bazy danych
Ten przepływ pracy używa narzędzia Sqoop do eksportowania danych do bazy danych SQL. Dlatego należy podać kopię sterownika JDBC używanego do interakcji z bazą danych SQL. Aby skopiować sterownik JDBC do katalogu roboczego, użyj następującego polecenia z sesji SSH:
hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /tutorials/useoozie/
Ważne
Sprawdź rzeczywisty sterownik JDBC, który istnieje pod adresem /usr/share/java/.
Jeśli przepływ pracy używał innych zasobów, takich jak plik jar zawierający aplikację MapReduce, musisz również dodać te zasoby.
Definiowanie zapytania Hive
Wykonaj poniższe kroki, aby utworzyć skrypt języka zapytań Hive (HiveQL), który definiuje zapytanie. Użyjesz zapytania w przepływie pracy Oozie w dalszej części tego dokumentu.
Z poziomu połączenia SSH użyj następującego polecenia, aby utworzyć plik o nazwie
useooziewf.hql:nano useooziewf.hqlPo otwarciu edytora nano GNU użyj następującego zapytania jako zawartości pliku:
DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName}(deviceplatform string, count string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT deviceplatform, COUNT(*) as count FROM hivesampletable GROUP BY deviceplatform;W skrycie są używane dwie zmienne:
${hiveTableName}: zawiera nazwę tabeli do utworzenia.${hiveDataFolder}: zawiera lokalizację do przechowywania plików danych dla tabeli.Plik definicji przepływu pracy, workflow.xml w tym artykule, przekazuje te wartości do tego skryptu HiveQL w czasie wykonywania.
Aby zapisać plik, naciśnij Ctrl+X, wprowadź Y, a następnie naciśnij Enter.
Użyj następującego polecenia, aby skopiować
useooziewf.hqlplik dowasbs:///tutorials/useoozie/useooziewf.hqlpliku :hdfs dfs -put useooziewf.hql /tutorials/useoozie/useooziewf.hqlTo polecenie przechowuje
useooziewf.hqlplik w magazynie zgodnym z systemem plików HDFS dla klastra.
Definiowanie przepływu pracy
Definicje przepływu pracy Oozie są zapisywane w języku hPDL (Hadoop Process Definition Language), który jest językiem definicji procesu XML. Aby zdefiniować przepływ pracy, wykonaj następujące czynności:
Użyj następującej instrukcji, aby utworzyć i edytować nowy plik:
nano workflow.xmlPo otwarciu edytora nano wprowadź następujący kod XML jako zawartość pliku:
<workflow-app name="useooziewf" xmlns="uri:oozie:workflow:0.2"> <start to = "RunHiveScript"/> <action name="RunHiveScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScript}</script> <param>hiveTableName=${hiveTableName}</param> <param>hiveDataFolder=${hiveDataFolder}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>W przepływie pracy zdefiniowano dwie akcje:
RunHiveScript: Ta akcja jest akcją początkową i uruchamiauseooziewf.hqlskrypt Programu Hive.RunSqoopExport: Ta akcja eksportuje dane utworzone ze skryptu programu Hive do bazy danych SQL przy użyciu narzędzia Sqoop. Ta akcja jest uruchamiana tylko wtedy, gdyRunHiveScriptakcja zakończy się pomyślnie.Przepływ pracy zawiera kilka wpisów, takich jak
${jobTracker}. Te wpisy zostaną zastąpione wartościami używanymi w definicji zadania. W dalszej części tego dokumentu utworzysz definicję zadania.Zwróć również uwagę na
<archive>mssql-jdbc-7.0.0.jre8.jar</archive>wpis w sekcji Sqoop. Ten wpis instruuje Oozie, aby to archiwum było dostępne dla sqoop po uruchomieniu tej akcji.
Aby zapisać plik, naciśnij Ctrl+X, wprowadź Y, a następnie naciśnij Enter.
Użyj następującego polecenia, aby skopiować
workflow.xmlplik do/tutorials/useoozie/workflow.xmlpliku :hdfs dfs -put workflow.xml /tutorials/useoozie/workflow.xml
Utwórz tabelę
Uwaga
Istnieje wiele sposobów nawiązywania połączenia z usługą SQL Database w celu utworzenia tabeli. W poniższej procedurze użyto rozwiązania FreeTDS z klastra usługi HDInsight.
Użyj następującego polecenia, aby zainstalować usługę FreeTDS w klastrze usługi HDInsight:
sudo apt-get --assume-yes install freetds-dev freetds-binZmodyfikuj poniższy kod, aby zastąpić
<serverName>ciąg nazwą serwera logicznego SQL i<sqlLogin>nazwą logowania serwera. Wprowadź polecenie , aby nawiązać połączenie z wstępnie wymaganą bazą danych SQL. Wprowadź hasło po wyświetleniu monitu.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestOtrzymasz dane wyjściowe podobne do następującego tekstu:
locale is "en_US.UTF-8" locale charset is "UTF-8" using default charset "UTF-8" Default database being set to oozietest 1>W wierszu
1>wprowadź następujące wiersze:CREATE TABLE [dbo].[mobiledata]( [deviceplatform] [nvarchar](50), [count] [bigint]) GO CREATE CLUSTERED INDEX mobiledata_clustered_index on mobiledata(deviceplatform) GOJeśli wprowadzono instrukcję
GO, zostaną obliczone poprzednie instrukcje. Te instrukcje tworzą tabelę o nazwiemobiledata, która jest używana przez przepływ pracy.Aby sprawdzić, czy tabela została utworzona, użyj następujących poleceń:
SELECT * FROM information_schema.tables GOZobaczysz dane wyjściowe podobne do następującego tekstu:
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME TABLE_TYPE oozietest dbo mobiledata BASE TABLEZamknij narzędzie tsql, wprowadzając
exitpolecenie w1>wierszu polecenia.
Tworzenie definicji zadania
Definicja zadania opisuje, gdzie znaleźć workflow.xml. Opisano również, gdzie można znaleźć inne pliki używane przez przepływ pracy, na przykład useooziewf.hql. Ponadto definiuje wartości właściwości używanych w przepływie pracy i skojarzonych plików.
Aby uzyskać pełny adres domyślnego magazynu, użyj następującego polecenia. Ten adres jest używany w pliku konfiguracji utworzonym w następnym kroku.
sed -n '/<name>fs.default/,/<\/value>/p' /etc/hadoop/conf/core-site.xmlTo polecenie zwraca informacje podobne do następującego kodu XML:
<name>fs.defaultFS</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value>Uwaga
Jeśli klaster usługi HDInsight używa usługi Azure Storage jako magazynu domyślnego,
<value>zawartość elementu zaczyna się odwasbs://. Jeśli zamiast tego jest używana usługa Azure Data Lake Storage Gen1, zaczyna się odadl://. Jeśli jest używana usługa Azure Data Lake Storage Gen2, zaczyna się odabfs://.Zapisz zawartość
<value>elementu, ponieważ jest on używany w następnych krokach.Edytuj poniższy kod XML w następujący sposób:
Wartość symbolu zastępczego Zamieniono wartość wasbs://mycontainer@mystorageaccount.blob.core.windows.net Wartość odebrana z kroku 1. administrator Nazwa logowania klastra usługi HDInsight, jeśli nie jest administratorem. serverName Nazwa serwera usługi Azure SQL Database. sqlLogin Logowanie do serwera usługi Azure SQL Database. sqlPassword Hasło logowania serwera usługi Azure SQL Database. <?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>nameNode</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value> </property> <property> <name>jobTracker</name> <value>headnodehost:8050</value> </property> <property> <name>queueName</name> <value>default</value> </property> <property> <name>oozie.use.system.libpath</name> <value>true</value> </property> <property> <name>hiveScript</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/useooziewf.hql</value> </property> <property> <name>hiveTableName</name> <value>mobilecount</value> </property> <property> <name>hiveDataFolder</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/data</value> </property> <property> <name>sqlDatabaseConnectionString</name> <value>"jdbc:sqlserver://serverName.database.windows.net;user=sqlLogin;password=sqlPassword;database=oozietest"</value> </property> <property> <name>sqlDatabaseTableName</name> <value>mobiledata</value> </property> <property> <name>user.name</name> <value>admin</value> </property> <property> <name>oozie.wf.application.path</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property> </configuration>Większość informacji w tym pliku służy do wypełniania wartości używanych w plikach workflow.xml lub ooziewf.hql, takich jak
${nameNode}. Jeśli ścieżka jest ścieżkąwasbs, musisz użyć pełnej ścieżki. Nie skracaj go tylko dowasbs:///. Wpisoozie.wf.application.pathdefiniuje miejsce znalezienia pliku workflow.xml. Ten plik zawiera przepływ pracy, który został uruchomiony przez to zadanie.Aby utworzyć konfigurację definicji zadania Oozie, użyj następującego polecenia:
nano job.xmlPo otwarciu edytora nano wklej edytowany kod XML jako zawartość pliku.
Aby zapisać plik, naciśnij Ctrl+X, wprowadź Y, a następnie naciśnij Enter.
Przesyłanie zadania i zarządzanie nim
W poniższych krokach użyj polecenia Oozie, aby przesłać przepływy pracy Oozie i zarządzać nimi w klastrze. Polecenie Oozie to przyjazny interfejs interfejsu api REST Oozie.
Ważne
W przypadku korzystania z polecenia Oozie należy użyć nazwy FQDN dla węzła głównego usługi HDInsight. Ta nazwa FQDN jest dostępna tylko z klastra lub jeśli klaster znajduje się w sieci wirtualnej platformy Azure, z innych maszyn w tej samej sieci.
Aby uzyskać adres URL usługi Oozie, użyj następującego polecenia:
sed -n '/<name>oozie.base.url/,/<\/value>/p' /etc/oozie/conf/oozie-site.xmlSpowoduje to zwrócenie informacji, takich jak następujący kod XML:
<name>oozie.base.url</name> <value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozie</value>Część
http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/ooziejest adresem URL do użycia z poleceniem Oozie.Zmodyfikuj kod, aby zastąpić adres URL wcześniej otrzymaną. Aby utworzyć zmienną środowiskową dla adresu URL, użyj następującej wartości, aby nie trzeba było wprowadzać jej dla każdego polecenia:
export OOZIE_URL=http://HOSTNAMEt:11000/oozieAby przesłać zadanie, użyj następującego kodu:
oozie job -config job.xml -submitTo polecenie ładuje informacje o zadaniu i
job.xmlprzesyła je do Oozie, ale nie uruchamia go.Po zakończeniu polecenia powinien zwrócić identyfikator zadania, na przykład
0000005-150622124850154-oozie-oozi-W. Ten identyfikator służy do zarządzania zadaniem.Zmodyfikuj poniższy kod, aby zastąpić
<JOBID>identyfikatorem zwróconym w poprzednim kroku. Aby wyświetlić stan zadania, użyj następującego polecenia:oozie job -info <JOBID>Spowoduje to zwrócenie informacji, takich jak następujący tekst:
Job ID : 0000005-150622124850154-oozie-oozi-W ------------------------------------------------------------------------------------------------------------------------------------ Workflow Name : useooziewf App Path : wasb:///tutorials/useoozie Status : PREP Run : 0 User : USERNAME Group : - Created : 2015-06-22 15:06 GMT Started : - Last Modified : 2015-06-22 15:06 GMT Ended : - CoordAction ID: - ------------------------------------------------------------------------------------------------------------------------------------To zadanie ma stan
PREP. Ten stan wskazuje, że zadanie zostało utworzone, ale nie zostało uruchomione.Zmodyfikuj poniższy kod, aby zastąpić
<JOBID>element identyfikatorem zwróconym wcześniej. Aby uruchomić zadanie, użyj następującego polecenia:oozie job -start <JOBID>Jeśli sprawdzisz stan po tym poleceniu, jest on w stanie uruchomienia, a informacje są zwracane dla akcji w zadaniu. Wykonanie zadania potrwa kilka minut.
Zmodyfikuj poniższy kod, aby zastąpić
<serverName>nazwą serwera i<sqlLogin>nazwą logowania serwera. Po pomyślnym zakończeniu zadania można sprawdzić, czy dane zostały wygenerowane i wyeksportowane do tabeli bazy danych SQL, używając następującego polecenia. Wprowadź hasło po wyświetleniu monitu.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestW
1>wierszu polecenia wprowadź następujące zapytanie:SELECT * FROM mobiledata GOZwrócone informacje są podobne do następującego tekstu:
deviceplatform count Android 31591 iPhone OS 22731 proprietary development 3 RIM OS 3464 Unknown 213 Windows Phone 1791 (6 rows affected)
Aby uzyskać więcej informacji na temat polecenia Oozie, zobacz Narzędzie wiersza polecenia apache Oozie.
Oozie REST API
Za pomocą interfejsu API REST Oozie możesz tworzyć własne narzędzia współpracujące z usługą Oozie. Następujące informacje specyficzne dla usługi HDInsight dotyczące korzystania z interfejsu API REST Oozie:
Identyfikator URI: dostęp do interfejsu API REST można uzyskać spoza klastra pod adresem
https://CLUSTERNAME.azurehdinsight.net/oozie.Uwierzytelnianie: aby się uwierzytelnić, użyj interfejsu API konta HTTP klastra (administratora) i hasła. Na przykład:
curl -u admin:PASSWORD https://CLUSTERNAME.azurehdinsight.net/oozie/versions
Aby uzyskać więcej informacji na temat korzystania z interfejsu API REST Oozie, zobacz Interfejs API usług internetowych Apache Oozie.
Interfejs użytkownika sieci Web Oozie
Internetowy interfejs użytkownika Oozie udostępnia internetowy widok stanu zadań Oozie w klastrze. Za pomocą internetowego interfejsu użytkownika można wyświetlić następujące informacje:
- Stan zadania
- Definicja zadania
- Konfigurowanie
- Wykres akcji w zadaniu
- Dzienniki zadania
Możesz również wyświetlić szczegóły akcji w zadaniu.
Aby uzyskać dostęp do internetowego interfejsu użytkownika usługi Oozie, wykonaj następujące kroki:
Utwórz tunel SSH w klastrze usługi HDInsight. Aby uzyskać więcej informacji, zobacz Use SSH Tunneling with HDInsight (Używanie tunelowania SSH z usługą HDInsight).
Po utworzeniu tunelu otwórz internetowy interfejs użytkownika systemu Ambari w przeglądarce internetowej przy użyciu identyfikatora URI
http://headnodehost:8080.Po lewej stronie wybierz pozycję Oozie>Quick Links>Oozie Web UI.
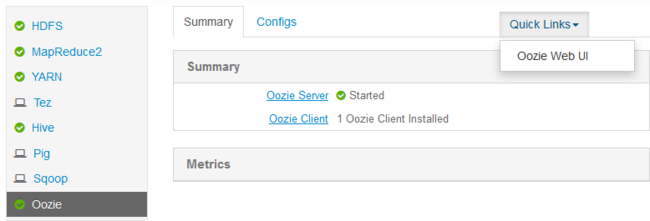
Interfejs użytkownika sieci Web Oozie domyślnie wyświetla uruchomione zadania przepływu pracy. Aby wyświetlić wszystkie zadania przepływu pracy, wybierz pozycję Wszystkie zadania.
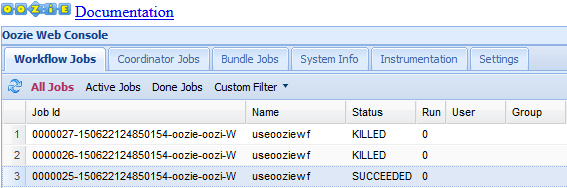
Aby wyświetlić więcej informacji o zadaniu, wybierz zadanie.
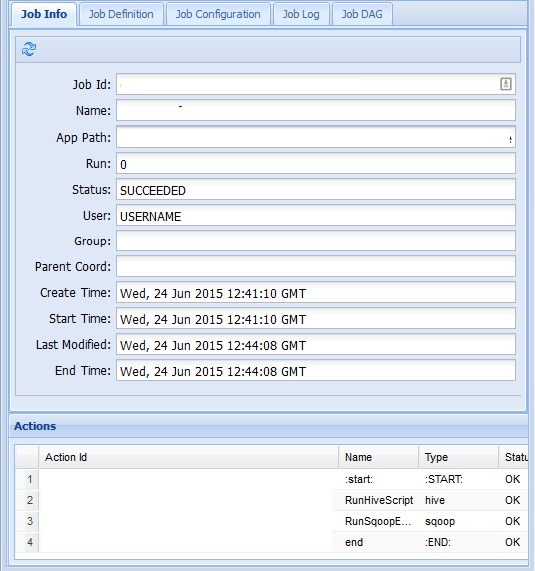
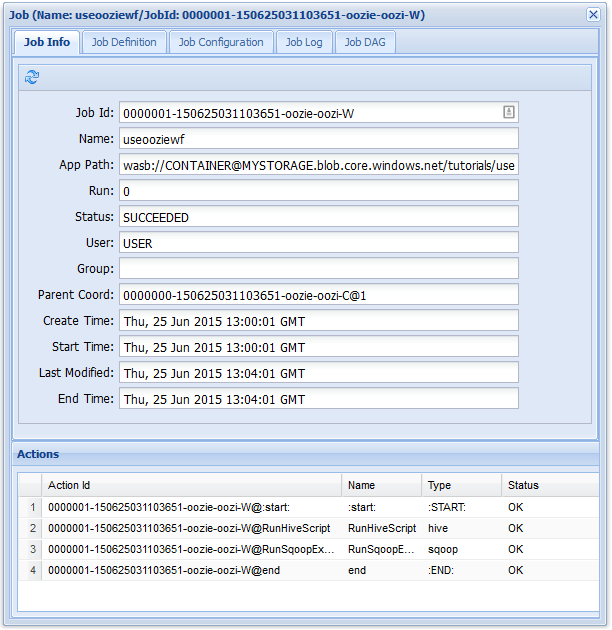
Na karcie Informacje o zadaniu można wyświetlić podstawowe informacje o zadaniu i poszczególne akcje w ramach zadania. Możesz użyć kart u góry, aby wyświetlić definicję zadania, konfigurację zadania, uzyskać dostęp do dziennika zadań lub wyświetlić skierowany wykres acykliczny (DAG) zadania w obszarze DaG zadania.
Dziennik zadań: wybierz przycisk Pobierz dzienniki, aby pobrać wszystkie dzienniki dla zadania, lub użyj
Enter Search Filterpola do filtrowania dzienników.
DaG zadania: DAG to graficzny przegląd ścieżek danych wykonywanych przez przepływ pracy.
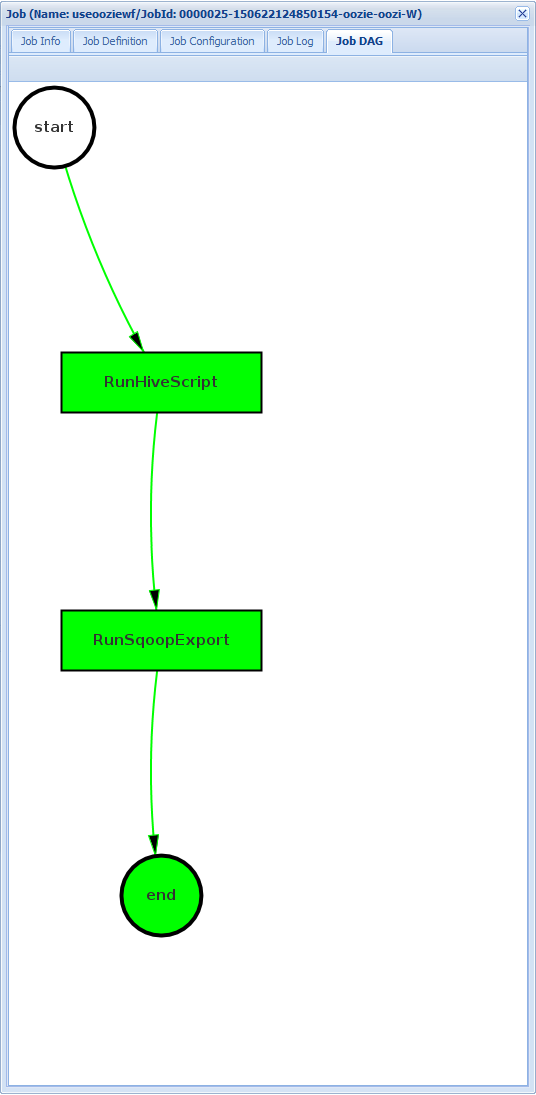
Jeśli wybierzesz jedną z akcji z karty Informacje o zadaniu, zostanie wyświetlona informacja o akcji. Na przykład wybierz akcję UruchomSqoopExport .
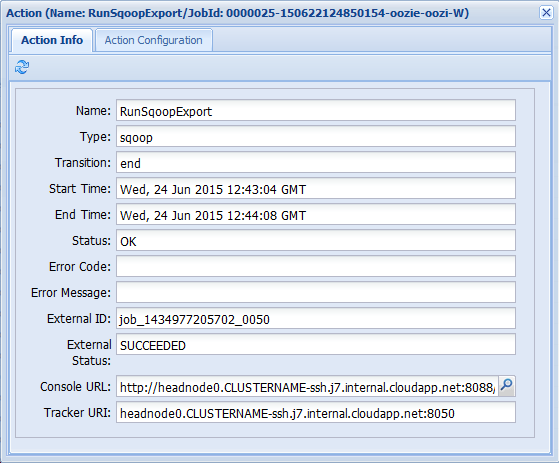
Szczegółowe informacje dotyczące akcji, takie jak link do adresu URL konsoli. Użyj tego linku, aby wyświetlić informacje o monitorze zadań dla zadania.
Planowanie zadań
Za pomocą koordynatora można określić początek, koniec i częstotliwość występowania zadań. Aby zdefiniować harmonogram przepływu pracy, wykonaj następujące kroki:
Użyj następującego polecenia, aby utworzyć plik o nazwie coordinator.xml:
nano coordinator.xmlUżyj następującego kodu XML jako zawartości pliku:
<coordinator-app name="my_coord_app" frequency="${coordFrequency}" start="${coordStart}" end="${coordEnd}" timezone="${coordTimezone}" xmlns="uri:oozie:coordinator:0.4"> <action> <workflow> <app-path>${workflowPath}</app-path> </workflow> </action> </coordinator-app>Uwaga
Zmienne
${...}są zastępowane wartościami w definicji zadania w czasie wykonywania. Zmienne to:${coordFrequency}: czas między uruchomionymi wystąpieniami zadania.${coordStart}: godzina rozpoczęcia zadania.${coordEnd}: godzina zakończenia zadania.${coordTimezone}: Zadania koordynatora znajdują się w stałej strefie czasowej bez czasu letniego, zwykle reprezentowane przy użyciu czasu UTC. Ta strefa czasowa jest określana jako strefa czasowa przetwarzania Oozie.${wfPath}: ścieżka do workflow.xml.
Aby zapisać plik, naciśnij Ctrl+X, wprowadź Y, a następnie naciśnij Enter.
Aby skopiować plik do katalogu roboczego dla tego zadania, użyj następującego polecenia:
hadoop fs -put coordinator.xml /tutorials/useoozie/coordinator.xmlAby zmodyfikować
job.xmlutworzony wcześniej plik, użyj następującego polecenia:nano job.xmlWprowadź następujące zmiany:
Aby poinstruować Oozie, aby uruchomić plik koordynatora zamiast przepływu pracy, zmień wartość
<name>oozie.wf.application.path</name>na<name>oozie.coord.application.path</name>.Aby ustawić zmienną
workflowPathużywaną przez koordynatora, dodaj następujący kod XML:<property> <name>workflowPath</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property>wasbs://mycontainer@mystorageaccount.blob.core.windowsZastąp tekst wartością używaną w innych wpisach w pliku job.xml.Aby zdefiniować początek, koniec i częstotliwość koordynatora, dodaj następujący kod XML:
<property> <name>coordStart</name> <value>2018-05-10T12:00Z</value> </property> <property> <name>coordEnd</name> <value>2018-05-12T12:00Z</value> </property> <property> <name>coordFrequency</name> <value>1440</value> </property> <property> <name>coordTimezone</name> <value>UTC</value> </property>Te wartości ustawiają godzinę rozpoczęcia na 12:00 w dniu 10 maja 2018 r. i godzinę zakończenia na 12 maja 2018 r. Interwał uruchamiania tego zadania jest ustawiony na codziennie. Częstotliwość jest wyrażona w minutach, więc 24 godziny x 60 minut = 1440 minut. Na koniec strefa czasowa jest ustawiona na utc.
Aby zapisać plik, naciśnij Ctrl+X, wprowadź Y, a następnie naciśnij Enter.
Aby przesłać i uruchomić zadanie, użyj następującego polecenia:
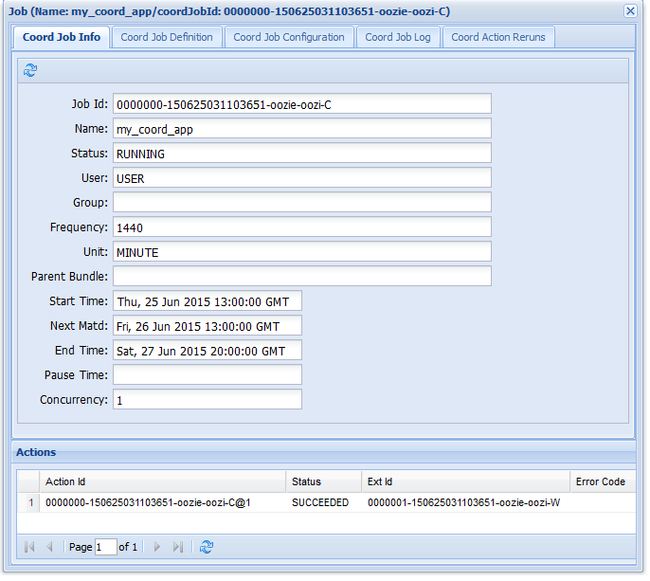
oozie job -config job.xml -runJeśli przejdziesz do internetowego interfejsu użytkownika usługi Oozie i wybierzesz kartę Zadania koordynatora, zobaczysz informacje podobne do na poniższej ilustracji:

Wpis Następna materializacja zawiera następny raz, gdy zadanie zostanie uruchomione.
Podobnie jak we wcześniejszym zadaniu przepływu pracy, jeśli wybierzesz wpis zadania w internetowym interfejsie użytkownika, wyświetla informacje o zadaniu:
Uwaga
Ten obraz przedstawia tylko pomyślne uruchomienia zadania, a nie poszczególne akcje w zaplanowanym przepływie pracy. Aby wyświetlić poszczególne akcje, wybierz jeden z wpisów Akcja .
Następne kroki
W tym artykule przedstawiono sposób definiowania przepływu pracy Oozie i uruchamiania zadania Oozie. Aby dowiedzieć się więcej o sposobie pracy z usługą HDInsight, zobacz następujące artykuły: