Samouczek: używanie strumieni ze strukturą platformy Apache Spark z platformą Kafka w usłudze HDInsight
W tym samouczku przedstawiono sposób użycia przesyłania strumieniowego platformy Apache Spark do odczytywania i zapisywania danych przy użyciu platformy Apache Kafka w usłudze Azure HDInsight.
Przesyłanie strumieniowe ze strukturą platformy Spark to aparat przetwarzania strumieniowego oparty na usłudze Spark SQL. Aparat ten umożliwia wyrażanie obliczeń strumieniowych tak samo jak obliczeń wsadowych na danych statycznych.
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Tworzenie klastrów przy użyciu szablonu usługi Azure Resource Manager
- Używanie przesyłania strumieniowego ze strukturą platformy Spark z platformą Kafka
Po wykonaniu kroków w tym dokumencie pamiętaj, aby usunąć klastry, aby uniknąć nadmiarowych opłat.
Wymagania wstępne
jq, procesor JSON wiersza polecenia. Zobacz: https://stedolan.github.io/jq/.
Znajomość zagadnień dotyczących używania notesów Jupyter za pomocą platformy Spark w usłudze HDInsight. Aby uzyskać więcej informacji, zobacz dokument Ładowanie danych i uruchamianie zapytań za pomocą platformy Apache Spark w usłudze HDInsight.
Znajomość języka programowania Scala. Kod używany w tym samouczku jest napisany w języku Scala.
Znajomość zagadnień dotyczących tworzenia tematów platformy Kafka. Aby uzyskać więcej informacji, zobacz dokument Przewodnik Szybki start dla platformy Apache Kafka w usłudze HDInsight.
Ważne
Kroki przedstawione w tym dokumencie wymagają grupy zasobów platformy Azure, która zawiera zarówno platformę Spark w usłudze HDInsight, jak i platformę Kafka w klastrze usługi HDInsight. Oba klastry znajdują się w usłudze Azure Virtual Network, dzięki czemu klaster Spark może komunikować się bezpośrednio z klastrem Kafka.
Dla Twojej wygody w tym dokumencie umieszczono link do szablonu, który umożliwia utworzenie wszystkich wymaganych zasobów platformy Azure.
Aby uzyskać więcej informacji na temat korzystania z usługi HDInsight w sieci wirtualnej, zobacz dokument Planowanie sieci wirtualnej dla usługi HDInsight .
Przesyłanie strumieniowe ze strukturą na platformie Apache Kafka
Przesyłanie strumieniowe ze strukturą platformy Spark to aparat przetwarzania strumieni oparty na aparacie SQL platformy Spark. W przypadku korzystania z przesyłania strumieniowego ze strukturą można pisać zapytania przesyłane strumieniowo w taki sam sposób, jak w przypadku pisania zapytań wsadowych.
Poniższe fragmenty kodu demonstrują odczytywanie z platformy Kafka i zapisywanie do pliku. Pierwszy z nich to operacja wsadowa, a drugi to operacja przesyłania strumieniowego:
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
W obu fragmentach dane są odczytywane z platformy Kafka i zapisywane do pliku. Różnice między przykładami:
| Batch | Przesyłanie strumieniowe |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
Operacja przesyłania strumieniowego używa awaitTermination(30000)również metody , która zatrzymuje strumień po 30 000 ms.
Aby używać przesyłania strumieniowego ze strukturą na platformie Kafka, projekt musi mieć zdefiniowaną zależność od pakietu org.apache.spark : spark-sql-kafka-0-10_2.11. Wersja tego pakietu powinna być zgodna z wersją platformy Spark w usłudze HDInsight. W przypadku platformy Spark 2.4 (dostępnej w usłudze HDInsight 4.0) informacje o zależnościach dla różnych typów projektów można znaleźć na stronie https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar.
W przypadku notesu Jupyter Używanego w tym samouczku następująca komórka ładuje tę zależność pakietu:
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
Tworzenie klastrów
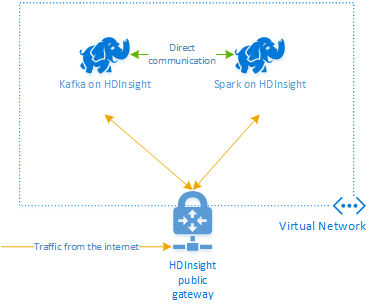
Platforma Apache Kafka w usłudze HDInsight nie zapewnia dostępu do brokerów platformy Kafka za pośrednictwem publicznego Internetu. Wszystkie elementy, które używają platformy Kafka, muszą znajdować się w tej samej sieci wirtualnej platformy Azure. W tym samouczku zarówno klaster Kafka, jak i klaster Spark znajdują się w tej samej sieci wirtualnej platformy Azure.
Na poniższym diagramie przedstawiono przepływ komunikacji między platformami Spark i Kafka:
Uwaga
Komunikacja usługi Kafka jest ograniczona do sieci wirtualnej. Inne usługi w klastrze, takie jak SSH i Ambari, są dostępne przez Internet. Aby uzyskać więcej informacji o publicznych portach dostępnych z usługą HDInsight, zobacz Ports and URIs used by HDInsight (Porty i identyfikatory URI używane przez usługę HDInsight).
Aby utworzyć usługę Azure Virtual Network, a następnie utworzyć w niej klastry Kafka i Spark, wykonaj następujące kroki:
Kliknij poniższy przycisk, aby zalogować się do platformy Azure i otworzyć szablon w witrynie Azure Portal.

Szablon usługi Azure Resource Manager znajduje się tutaj: https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json.
Ten szablon umożliwia utworzenie następujących zasobów:
Kafka w klastrze usługi HDInsight 4.0 lub 5.0.
Klaster Spark 2.4 lub 3.1 w usłudze HDInsight 4.0 lub 5.0.
Sieć wirtualna platformy Azure zawierająca klastry usługi HDInsight.
Ważne
Notes przesyłania strumieniowego ze strukturą używany w tym samouczku wymaga platformy Spark 2.4 lub 3.1 w usłudze HDInsight 4.0 lub 5.0. W przypadku użycia starszej wersji platformy Spark w usłudze HDInsight podczas korzystania z notesu wystąpią błędy.
Wypełnij pola w sekcji Dostosowany szablon, korzystając z poniższych informacji:
Ustawienie Wartość Subskrypcja Subskrypcja platformy Azure Grupa zasobów Grupa zasobów zawierająca zasoby. Lokalizacja Region świadczenia usługi Azure, w którym są tworzone zasoby. Nazwa klastra Spark Nazwa klastra Spark. Pierwszych sześć znaków musi być innych niż nazwa klastra Kafka. Nazwa klastra Kafka Nazwa klastra Kafka. Pierwszych sześć znaków musi być innych niż nazwa klastra Spark. Nazwa użytkownika logowania klastra Nazwa użytkownika będącego administratorem klastrów. Hasło logowania klastra Hasło użytkownika będącego administratorem klastrów. Nazwa użytkownika SSH Użytkownik SSH tworzony na potrzeby obsługi klastrów. Hasło SSH Hasło użytkownika SSH. 
Przeczytaj warunki i postanowienia, a następnie wybierz pozycję Zgadzam się na powyższe warunki i postanowienia.
Wybierz pozycję Kup.
Uwaga
Tworzenie klastrów może potrwać do 20 minut.
Korzystanie ze przesyłania strumieniowego ze strukturą platformy Spark
W tym przykładzie pokazano, jak używać przesyłania strumieniowego ze strukturą platformy Spark z platformą Kafka w usłudze HDInsight. Wykorzystuje dane dotyczące przejazdów taksówką, które są dostarczane przez Nowy Jork. Zestaw danych używany przez ten notes pochodzi z danych z 2016 green taxi trip.
Zbierz informacje o hoście. Użyj poniższych poleceń curl i jq , aby uzyskać informacje o hostach hostów i hostów platformy Kafka ZooKeeper. Polecenia są przeznaczone dla wiersza polecenia systemu Windows, niewielkie odmiany będą potrzebne w innych środowiskach. Zastąp
KafkaClusterciąg nazwą klastra platformy Kafka iKafkaPasswordhasłem logowania klastra. Zastąp równieżC:\HDI\jq-win64.exerzeczywistą ścieżką do instalacji jq. Wprowadź polecenia w wierszu polecenia systemu Windows i zapisz dane wyjściowe do użycia w kolejnych krokach.REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"W przeglądarce internetowej przejdź do
https://CLUSTERNAME.azurehdinsight.net/jupyterlokalizacji , gdzieCLUSTERNAMEjest nazwą klastra. Po wyświetleniu monitu wprowadź nazwę użytkownika klastra (administratora) i hasło użyte podczas tworzenia klastra.Wybierz pozycję Nowa > platforma Spark , aby utworzyć notes.
Przesyłanie strumieniowe platformy Spark ma mikrobatching, co oznacza, że dane są wykonywane w partiach i funkcjach wykonawczej w partiach danych. Jeśli funkcja wykonawcza ma limit czasu bezczynności krótszy niż czas przetwarzania partii, funkcja wykonawcza będzie stale dodawana i usuwana. Jeśli limit czasu bezczynności funkcji wykonawczej jest większy niż czas trwania partii, funkcja wykonawcza nigdy nie zostanie usunięta. Dlatego zalecamy wyłączenie alokacji dynamicznej przez ustawienie wartości spark.dynamicAllocation.enabled na wartość false podczas uruchamiania aplikacji przesyłania strumieniowego.
Załaduj pakiety używane przez notes, wprowadzając następujące informacje w komórce Notes. Uruchom polecenie za pomocą klawiszy CTRL + ENTER.
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }Utwórz temat platformy Kafka. Zmodyfikuj poniższe polecenie, zastępując
YOUR_ZOOKEEPER_HOSTSciąg informacjami o hoście zookeeper wyodrębnionym w pierwszym kroku. Wprowadź edytowane polecenie w notesie Jupyter Notebook, aby utworzyćtripdatatemat.%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepersPobieranie danych dotyczących przejazdów taksówką. Wprowadź polecenie w następnej komórce, aby załadować dane dotyczące przejazdów taksówek w Nowym Jorku. Dane są ładowane do ramki danych, a następnie ramka danych jest wyświetlana jako dane wyjściowe komórki.
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()Ustaw informacje o hostach brokera platformy Kafka. Zastąp ciąg
YOUR_KAFKA_BROKER_HOSTSinformacjami o hostach brokera wyodrębnionych w kroku 1. Wprowadź edytowane polecenie w następnej komórce notesu Jupyter Notebook.// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")Wyślij dane do platformy Kafka. W poniższym pole
vendoridjest używane jako wartość klucza komunikatu platformy Kafka. Klucz jest używany przez platformę Kafka podczas partycjonowania danych. Wszystkie pola są przechowywane w komunikacie platformy Kafka jako wartość ciągu JSON. Wprowadź następujące polecenie w programie Jupyter, aby zapisać dane na platformie Kafka przy użyciu zapytania wsadowego.// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")Zadeklaruj schemat. Poniższe polecenie pokazuje, jak używać schematu podczas odczytywania danych JSON z platformy kafka. Wprowadź polecenie w następnej komórce Jupyter.
// Import bits used for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")Wybierz dane i uruchom strumień. Poniższe polecenie pokazuje, jak pobrać dane z platformy Kafka przy użyciu zapytania wsadowego. Następnie zapisz wyniki w systemie plików HDFS w klastrze Spark. W tym przykładzie
selectpolecenie pobiera komunikat (pole wartości) z platformy Kafka i stosuje do niego schemat. Dane są następnie zapisywane w systemie plików HDFS (WASB lub ADL) w formacie parquet. Wprowadź polecenie w następnej komórce Jupyter.// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")Możesz sprawdzić, czy pliki zostały utworzone, wprowadzając polecenie w następnej komórce Jupyter. Wyświetla listę plików w
/example/batchtripdatakatalogu.%%bash hdfs dfs -ls /example/batchtripdataPodczas gdy w poprzednim przykładzie użyto zapytania wsadowego, następujące polecenie pokazuje, jak wykonać to samo przy użyciu zapytania przesyłania strumieniowego. Wprowadź polecenie w następnej komórce Jupyter.
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")Uruchom następującą komórkę, aby sprawdzić, czy pliki zostały zapisane przez zapytanie przesyłane strumieniowo.
%%bash hdfs dfs -ls /example/streamingtripdata
Czyszczenie zasobów
Aby wyczyścić zasoby utworzone w tym samouczku, możesz usunąć grupę zasobów. Usunięcie grupy zasobów spowoduje również usunięcie skojarzonego klastra usługi HDInsight. Wszystkie inne zasoby skojarzone z grupą zasobów.
Aby usunąć grupę zasobów za pomocą witryny Azure Portal:
- W witrynie Azure Portal rozwiń menu po lewej stronie, aby otworzyć menu usług, a następnie wybierz pozycję Grupy zasobów, aby wyświetlić listę grup zasobów.
- Znajdź grupę zasobów do usunięcia, a następnie kliknij prawym przyciskiem myszy przycisk Więcej (...) po prawej stronie listy.
- Wybierz pozycję Usuń grupę zasobów i potwierdź.
Ostrzeżenie
Naliczanie opłat rozpoczyna się w momencie utworzenia klastra usługi HDInsight i kończy się wraz z jego usunięciem. Opłaty są naliczane za minutę, więc jeśli klaster nie jest używany, należy go usunąć.
Usunięcie platformy Kafka w klastrze usługi HDInsight powoduje usunięcie wszystkich danych przechowywanych na platformie Kafka.