Zarządzanie magazynem kubernetes na urządzeniu z procesorem GPU Usługi Azure Stack Edge Pro
DOTYCZY:  Azure Stack Edge Pro — GPUAzure Stack Edge Pro 2Azure Stack Edge Pro R Azure Stack Edge Mini R
Azure Stack Edge Pro — GPUAzure Stack Edge Pro 2Azure Stack Edge Pro R Azure Stack Edge Mini R
Na urządzeniu Azure Stack Edge Pro klaster Kubernetes jest tworzony podczas konfigurowania roli obliczeniowej. Po utworzeniu klastra Kubernetes konteneryzowane aplikacje można wdrożyć w klastrze Kubernetes w zasobnikach. Istnieją różne sposoby udostępniania magazynu zasobnikom w klastrze Kubernetes.
W tym artykule opisano metody aprowizowania magazynu w klastrze Kubernetes ogólnie i w szczególności w kontekście urządzenia Azure Stack Edge Pro.
Wymagania dotyczące magazynu dla zasobników Kubernetes
Zasobniki kubernetes są bezstanowe, ale aplikacje, które są uruchamiane, są zwykle stanowe. Ponieważ zasobniki mogą być krótkotrwałe i ponownie uruchamiają się, przechodzą w tryb failover lub przechodzą między węzłami Kubernetes, należy spełnić następujące wymagania dotyczące magazynu skojarzonego z zasobnikiem.
Magazyn musi:
- Na żywo poza zasobnikem.
- Być niezależny od cyklu życia zasobnika.
- Być dostępny ze wszystkich węzłów platformy Kubernetes.
Aby zrozumieć, jak magazyn jest zarządzany dla platformy Kubernetes, należy poznać dwa zasoby interfejsu API:
PersistentVolume (PV): jest to fragment magazynu w klastrze Kubernetes. Magazyn Kubernetes może być statycznie aprowizowany jako
PersistentVolume. Można go również dynamicznie aprowizować jakoStorageClass.PersistentVolumeClaim (PVC): jest to żądanie magazynu przez użytkownika. PvCs zużywają zasoby PV. PvCs mogą żądać określonego rozmiaru i trybów dostępu.
Ponieważ użytkownicy potrzebują
PersistentVolumesróżnych właściwości dla różnych problemów, dlatego administratorzy klastra muszą mieć możliwość zaoferowania różnychPersistentVolumesróżnych sposobów niż tylko rozmiar i tryby dostępu. W przypadku tych potrzeb potrzebnyStorageClassjest zasób.
Aprowizacja magazynu może być statyczna lub dynamiczna. Każdy z typów aprowizacji jest omówiony w poniższych sekcjach.
Statyczna aprowizacja
Administratorzy klastrów Kubernetes mogą statycznie aprowizować magazyn. W tym celu mogą używać zaplecza magazynu opartego na systemach plików SMB/NFS lub używać dysków iSCSI, które są dołączane lokalnie przez sieć w środowisku lokalnym, a nawet korzystać z usług Azure Files lub Azure Disks w chmurze. Ten typ magazynu nie jest domyślnie aprowizowany, a administratorzy klastra muszą planować tę aprowizację i zarządzać nią.
Oto diagram przedstawiający sposób, w jaki statycznie aprowizowany magazyn jest używany na platformie Kubernetes:
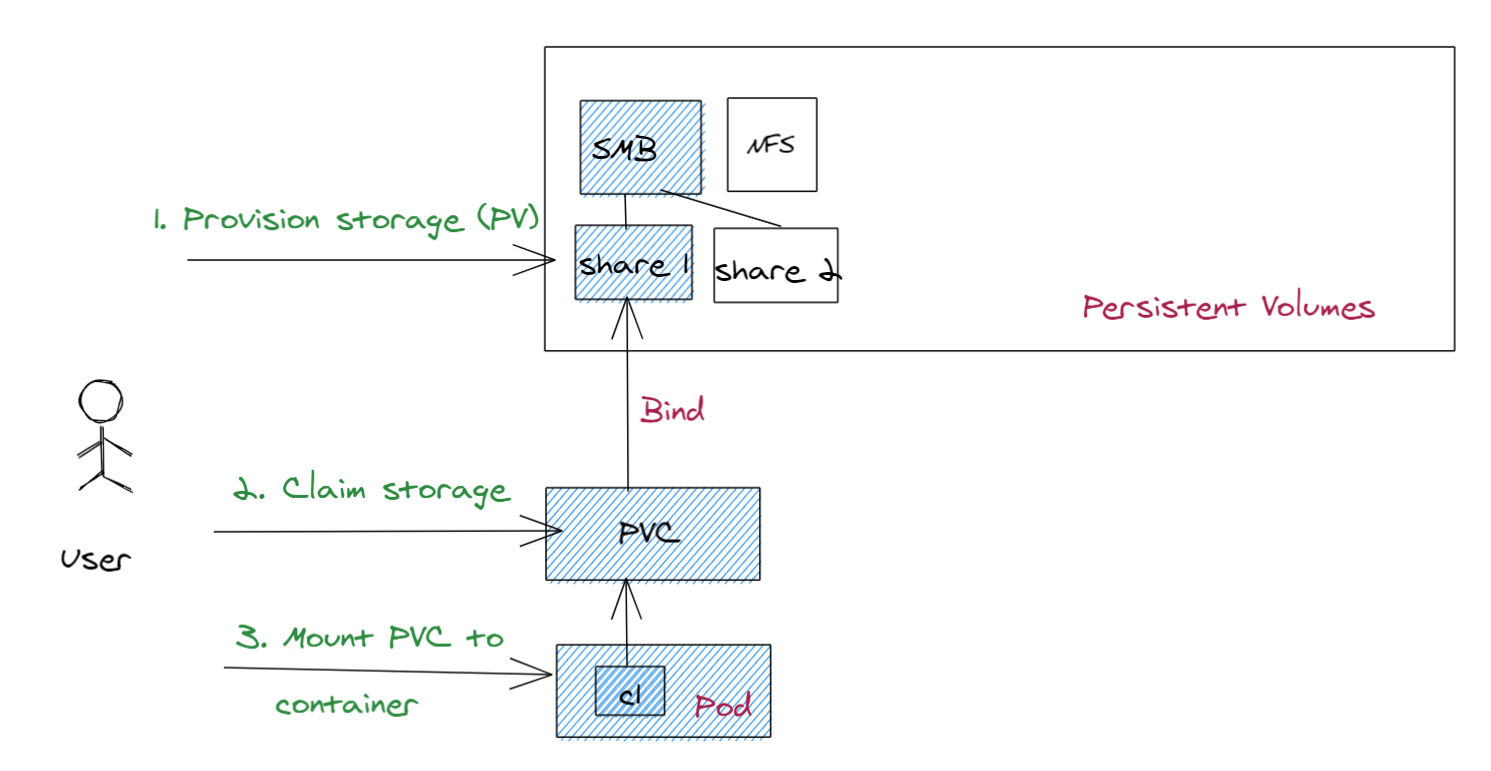
Są wykonywane następujące czynności:
Aprowizuj magazyn: administrator klastra aprowizuje magazyn. W tym przykładzie administrator klastra tworzy co najmniej jeden udział SMB, który automatycznie tworzy trwałe obiekty woluminów w klastrze Kubernetes odpowiadającym tym udziałom.
Magazyn oświadczeń: należy przesłać wdrożenie PVC, które żąda magazynu. To oświadczenie dotyczące magazynu to PersistentVolumeClaim (PVC). Jeśli rozmiar i tryb dostępu PV są zgodne z PVC, pcv jest powiązany z PV. PVC i PV mapować jeden do jednego.
Zamontować PVC w kontenerze: po powiązaniu PVC z PV można zamontować ten PVC na ścieżce w kontenerze. Gdy logika aplikacji w kontenerze odczytuje/zapisuje z/do tej ścieżki, dane są zapisywane w magazynie SMB.
Dynamiczna aprowizacja
Oto diagram przedstawiający sposób, w jaki statycznie aprowizowany magazyn jest używany na platformie Kubernetes:
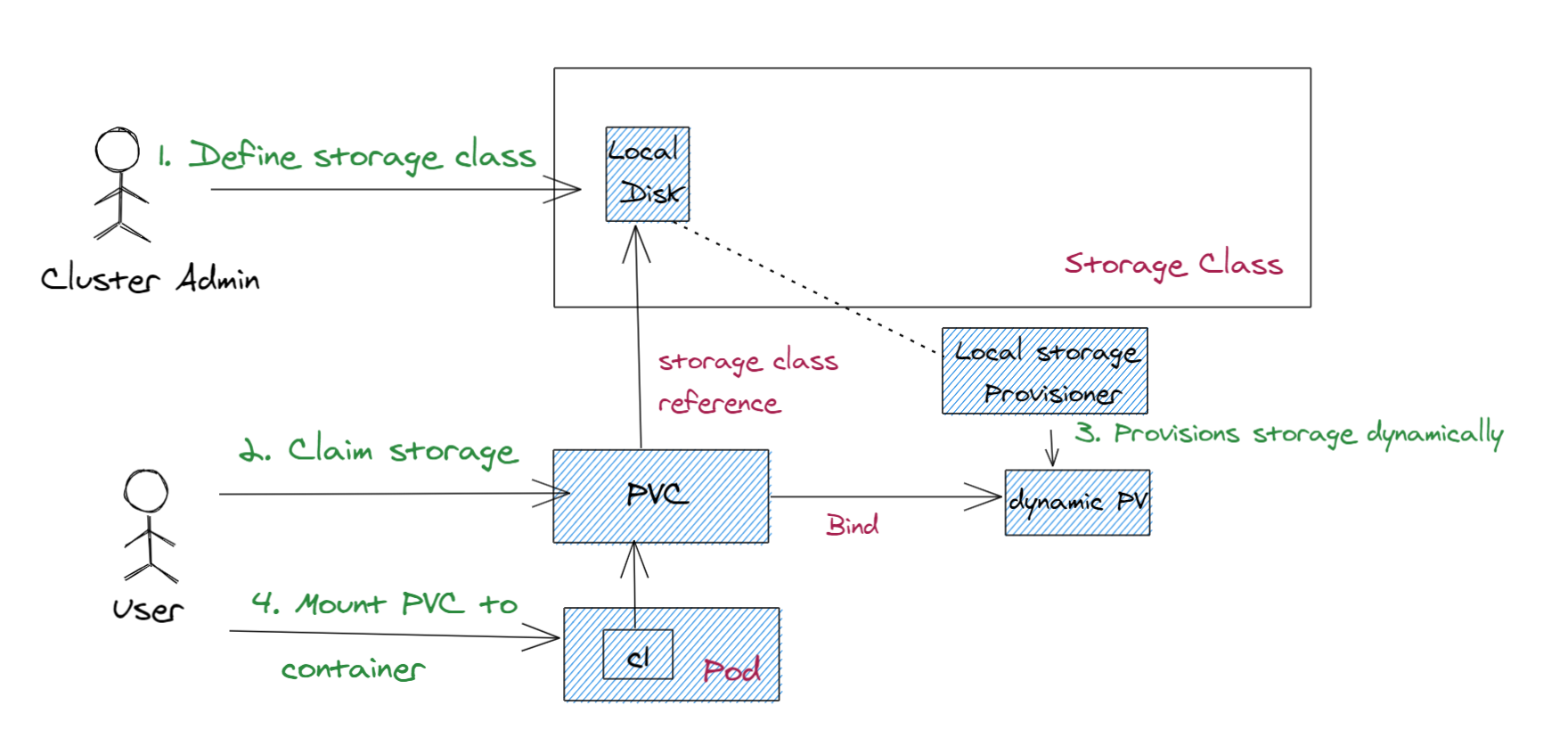
Są wykonywane następujące czynności:
Definiowanie klasy magazynu: administrator klastra definiuje klasę magazynu w zależności od środowiska operacyjnego klastra Kubernetes. Administrator klastra wdraża również aprowizację, która jest kolejnym zasobnikem lub aplikacją wdrożona w klastrze Kubernetes. Inicjowanie obsługi administracyjnej zawiera wszystkie szczegóły dotyczące dynamicznego aprowizowania udziałów.
Magazyn oświadczeń: przesyłasz aplikację, która będzie twierdziła magazyn. Po utworzeniu elementu PVC przy użyciu tego odwołania do klasy magazynu aprowizacja jest wywoływana.
Dynamiczne aprowizuj magazyn: aprowizacja dynamicznie tworzy udział skojarzony z magazynem dysku lokalnego. Po utworzeniu udziału tworzy on również obiekt PV automatycznie odpowiadający temu udziałowi.
Zamontować PCW do kontenera: po powiązaniu PVC z PV można zamontować PVC na kontenerze na ścieżce w taki sam sposób jak statyczna aprowizacja i odczyt lub zapis do udziału.
Aprowizowanie magazynu w usłudze Azure Stack Edge Pro
Na urządzeniu Azure Stack Edge Pro statycznie aprowizowane PersistentVolumes są tworzone przy użyciu funkcji magazynu urządzenia. Po aprowizacji udziału i włączeniu opcji Użyj udziału w obliczeniach usługi Edge ta akcja powoduje automatyczne utworzenie zasobu PV w klastrze Kubernetes.
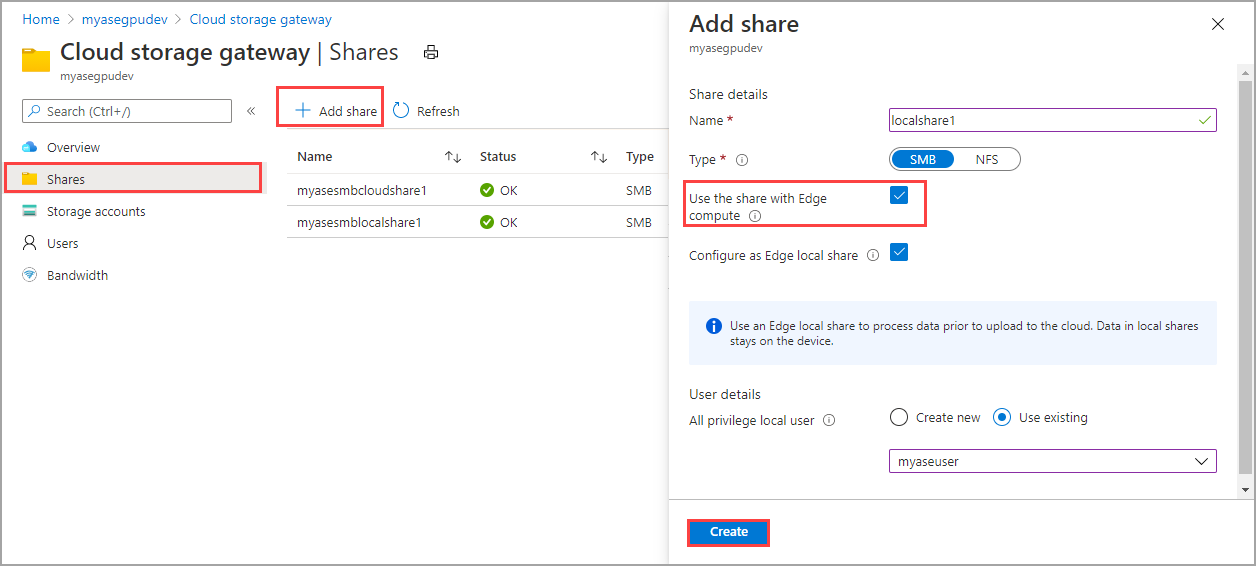
Aby użyć obsługi warstw w chmurze, możesz utworzyć udział w chmurze edge z włączoną opcją Użyj udziału z usługą Obliczeniową Edge. Dla tego udziału zostanie ponownie utworzony automatycznie element PV. Wszystkie dane aplikacji zapisywane w udziale usługi Edge są warstwowe w chmurze.
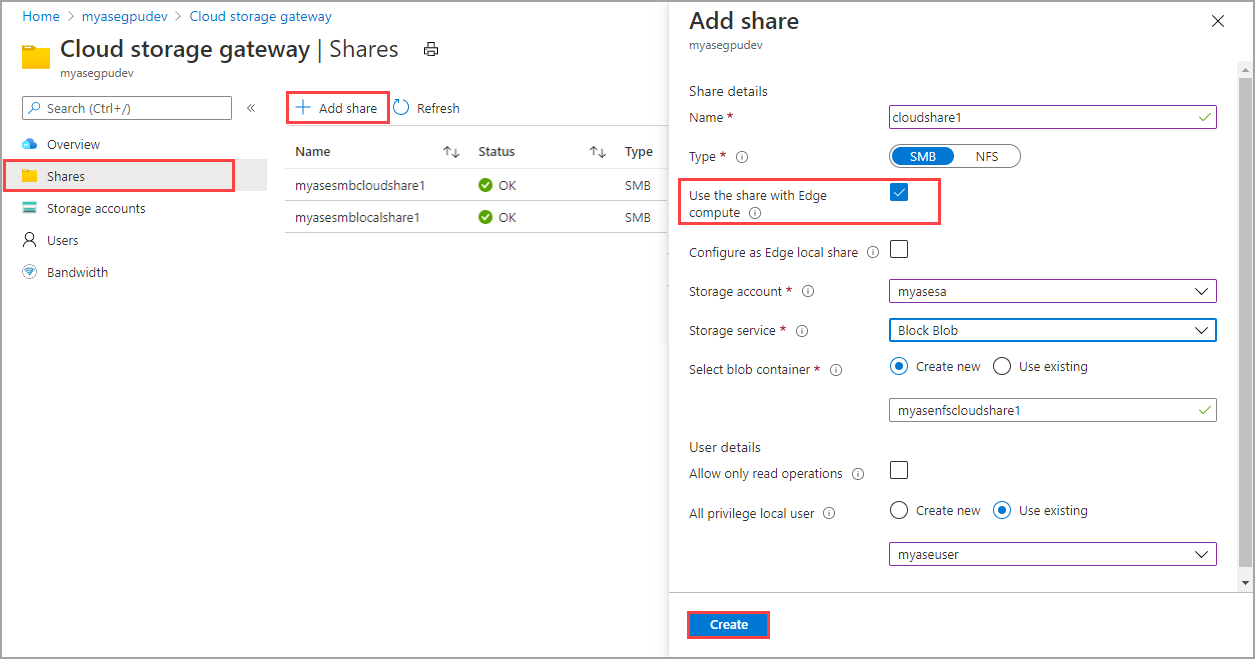
Udziały SMB i NFS można utworzyć, aby statycznie aprowizować woluminy wirtualne na urządzeniu Azure Stack Edge Pro. Po aprowizowanej sieci PV należy przesłać element PVC, aby ubiegać się o ten magazyn. Oto przykład wdrożenia yaml PCW, który twierdzi, że magazyn i korzysta z aprowizowanych udziałów.
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc-smb-flexvol
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
volumeName: <nfs-or-smb-share-name-here>
storageClassName: ""
Aby uzyskać wartość volumeName pola, wybierz lokalny punkt instalacji dla modułów obliczeniowych usługi Edge po wybraniu udziału SMB lub NFS po utworzeniu. Jest to taka sama jak nazwa udziału.
Aby uzyskać więcej informacji, zobacz Deploy a stateful application via static provisioning on your Azure Stack Edge Pro via kubectl (Wdrażanie aplikacji stanowej za pomocą statycznej aprowizacji w usłudze Azure Stack Edge Pro za pośrednictwem narzędzia kubectl).
Aby uzyskać dostęp do tego samego statycznie aprowizowanego magazynu, odpowiednie opcje instalacji woluminu dla powiązań magazynu dla IoT są następujące. To /home/input ścieżka, w której wolumin jest dostępny w kontenerze.
{
"HostConfig": {
"Mounts": [
{
"Target": "/home/input",
"Source": "<nfs-or-smb-share-name-here>",
"Type": "volume"
},
{
"Target": "/home/output",
"Source": "<nfs-or-smb-share-name-here>",
"Type": "volume"
}]
}
}
Usługa Azure Stack Edge Pro ma również wbudowaną nazwę StorageClass ase-node-local , która używa magazynu dysku danych dołączonego do węzła Kubernetes. Obsługuje to StorageClass dynamiczną aprowizację. Możesz utworzyć StorageClass odwołanie w aplikacjach zasobników i automatycznie utworzyć pv. Aby uzyskać więcej informacji, zobacz pulpit nawigacyjny platformy Kubernetes do wykonywania zapytań dotyczących usługi ase-node-local StorageClass.
Aby uzyskać więcej informacji, zobacz Wdrażanie aplikacji stanowej za pośrednictwem dynamicznej aprowizacji w usłudze Azure Stack Edge Pro za pośrednictwem usługi kuebctl.
Wybieranie typu magazynu
W zależności od wdrażanych obciążeń może być konieczne wybranie typu magazynu.
Jeśli chcesz
ReadWriteManyużyć trybu dostępu dlaPersistentVolumesmiejsca, w którym woluminy są instalowane jako odczyt-zapis przez wiele węzłów wdrażanych, użyj statycznej aprowizacji dla udziałów SMB/NFS.Jeśli wdrażane aplikacje mają na przykład wymagania dotyczące zgodności z rozwiązaniem POSIX, takie jak MongoDB, PostgreSQL, MySQL lub Prometheus, użyj wbudowanej klasy StorageClass. Tryby dostępu to
ReadWriteOncelub wolumin jest instalowany jako odczyt-zapis przez jeden węzeł.
Aby uzyskać więcej informacji na temat trybów dostępu, zobacz Tryb dostępu do woluminów Kubernetes.
Następne kroki
Aby dowiedzieć się, jak statycznie aprowizować element PersistentVolume, zobacz:
Aby dowiedzieć się, jak dynamicznie aprowizować element StorageClass, zobacz: