Przekształcanie danych w usłudze Azure Virtual Network przy użyciu działania hive w usłudze Azure Data Factory przy użyciu witryny Azure Portal
DOTYCZY:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym samouczku witryna Azure Portal umożliwia tworzenie potoku usługi Data Factory przekształcającego dane przy użyciu działania programu Hive w klastrze usługi HDInsight, który znajduje się w usłudze Azure Virtual Network (VNet). Ten samouczek obejmuje następujące procedury:
- Tworzenie fabryki danych.
- Tworzenie własnego środowiska Integration Runtime
- Tworzenie połączonych usług Azure Storage i Azure HDInsight
- Tworzenie potoku przy użycia działania Hive
- Wyzwalanie uruchomienia potoku.
- Monitorowanie działania potoku
- Sprawdzanie danych wyjściowych
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
Uwaga
Do interakcji z platformą Azure zalecamy używanie modułu Azure Az w programie PowerShell. Zobacz Instalowanie programu Azure PowerShell, aby rozpocząć. Aby dowiedzieć się, jak przeprowadzić migrację do modułu Az PowerShell, zobacz Migracja programu Azure PowerShell z modułu AzureRM do modułu Az.
Konto usługi Azure Storage. Utwórz skrypt programu Hive i przekaż go do usługi Azure Storage. Dane wyjściowe skryptu programu Hive są przechowywane na tym koncie magazynu. W tym przykładzie klaster usługi HDInsight używa tego konta usługi Azure Storage jako magazynu głównego.
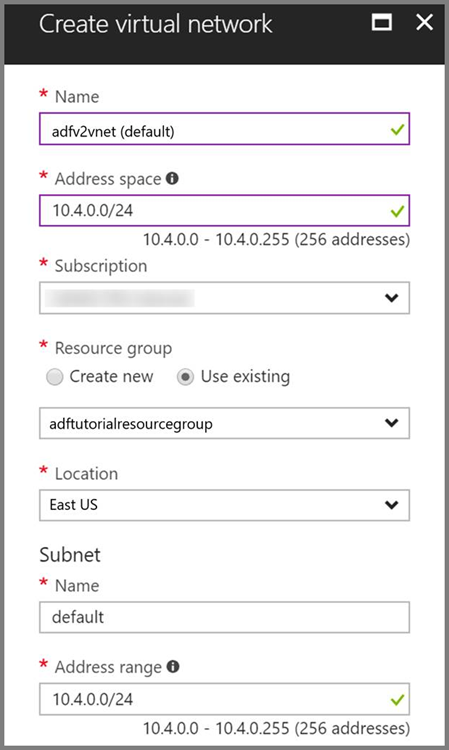
Azure Virtual Network. Jeśli nie masz sieci wirtualnej platformy Azure, utwórz ją, wykonując te instrukcje. W tym przykładzie usługa HDInsight znajduje się w usłudze Azure Virtual Network. Oto przykładowa konfiguracja usługi Azure Virtual Network.
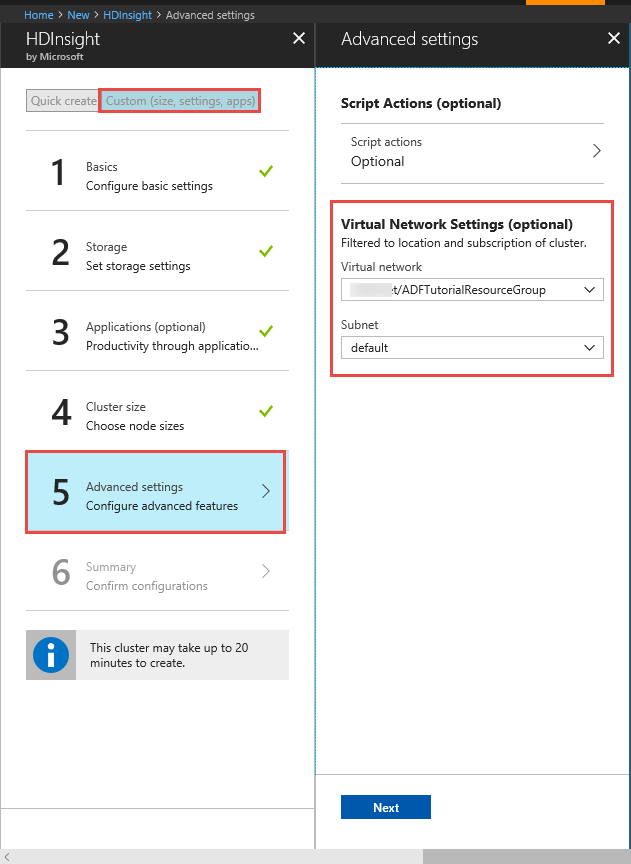
Klaster usługi HDInsight. Utwórz klaster usługi HDInsight i przyłącz go do sieci wirtualnej utworzonej w poprzednim kroku, postępując zgodnie z opisem podanym w tym artykule: Extend Azure HDInsight using an Azure Virtual Network (Rozszerzenie usługi Azure HDInsight za pomocą usługi Azure Virtual Network). Oto przykładowa konfiguracja usługi HDInsight w sieci wirtualnej.
Azure PowerShell. Wykonaj instrukcje podane w temacie Instalowanie i konfigurowanie programu Azure PowerShell.
Maszyna wirtualna. Utwórz maszynę wirtualną platformy Azure i przyłącz ją do tej samej sieci wirtualnej, która zawiera Twój klaster usługi HDInsight. Aby uzyskać szczegółowe informacje, zobacz How to create virtual machines (Jak utworzyć maszyny wirtualne).
Przekazywanie skryptu programu Hive do konta usługi Blob Storage
Utwórz plik SQL programu Hive SQL o nazwie hivescript.hql i następującej zawartości:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableW usłudze Azure Blob Storage utwórz kontener o nazwie adftutorial, jeśli nie istnieje.
Utwórz folder o nazwie hivescripts.
Przekaż plik hivescript.hql do podfolderu hivescripts.
Tworzenie fabryki danych
Jeśli fabryka danych nie została jeszcze utworzona, wykonaj kroki opisane w przewodniku Szybki start: Tworzenie fabryki danych przy użyciu witryny Azure Portal i programu Azure Data Factory Studio , aby je utworzyć. Po utworzeniu przejdź do fabryki danych w witrynie Azure Portal.
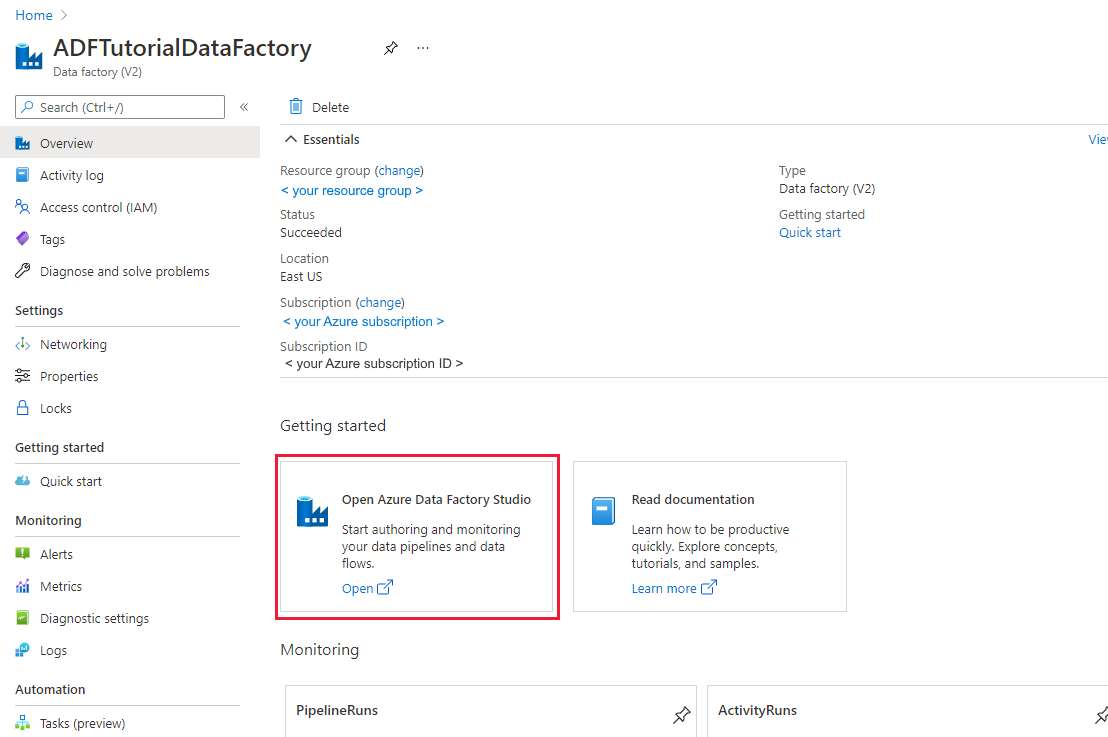
Wybierz pozycję Otwórz na kafelku Otwórz usługę Azure Data Factory Studio, aby uruchomić aplikację Integracja danych na osobnej karcie.
Tworzenie własnego środowiska Integration Runtime
Ponieważ klaster usługi Hadoop znajduje się wewnątrz sieci wirtualnej, należy zainstalować środowisko Integration Runtime (Self-hosted) w tej samej sieci wirtualnej. W tej sekcji utworzysz nową maszynę wirtualną, dołączysz ją do tej samej sieci wirtualnej i zainstalujesz na niej środowisko IR (Self-hosted). Środowisko IR (Self-hosted) umożliwia usłudze Data Factory wysyłanie żądań przetwarzania do usługi obliczeniowej, takiej jak HDInsight, w sieci wirtualnej. Pozwala ono również na przenoszenie danych do i z magazynów danych w sieci wirtualnej na platformę Azure. Środowisko IR (Self-hosted) jest używane, jeśli magazyn danych lub obliczenie znajduje się również w środowisku lokalnym.
W interfejsie użytkownika usługi Azure Data Factory kliknij pozycję Połączenia w dolnej części okna, przejdź do karty Środowiska Integration Runtime, a następnie kliknij przycisk + Nowy na pasku narzędzi.
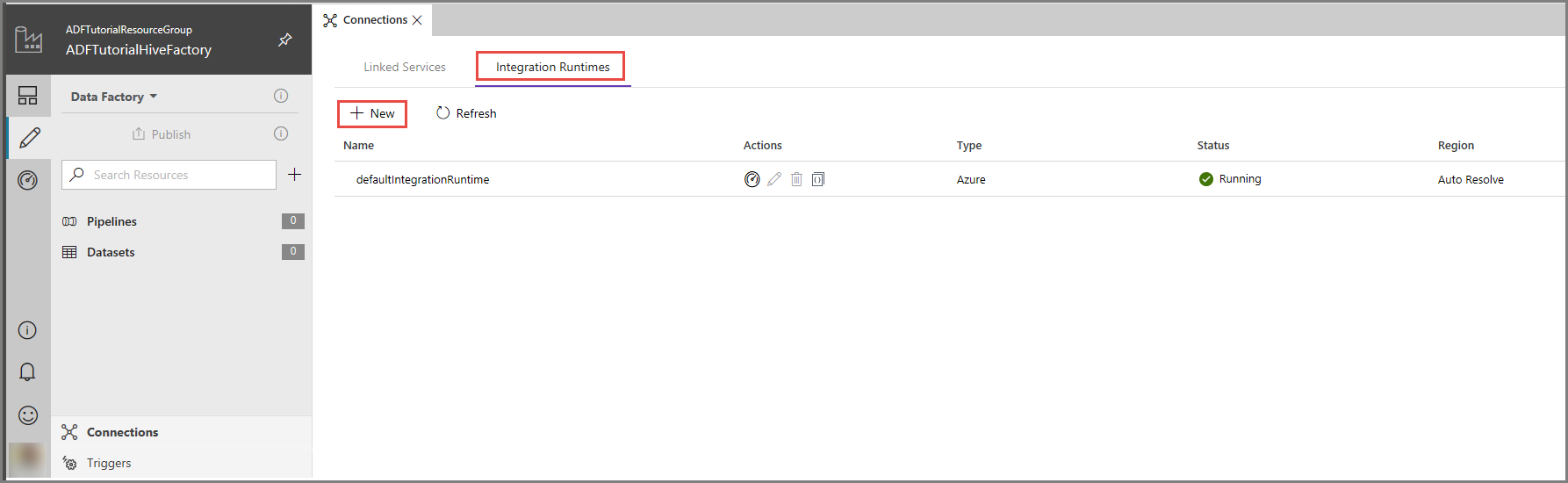
W oknie Konfiguracja środowiska Integration Runtime wybierz opcję Wykonuj przenoszenie danych i wysyłaj działania do obliczeń zewnętrznych, a następnie kliknij pozycję Dalej.
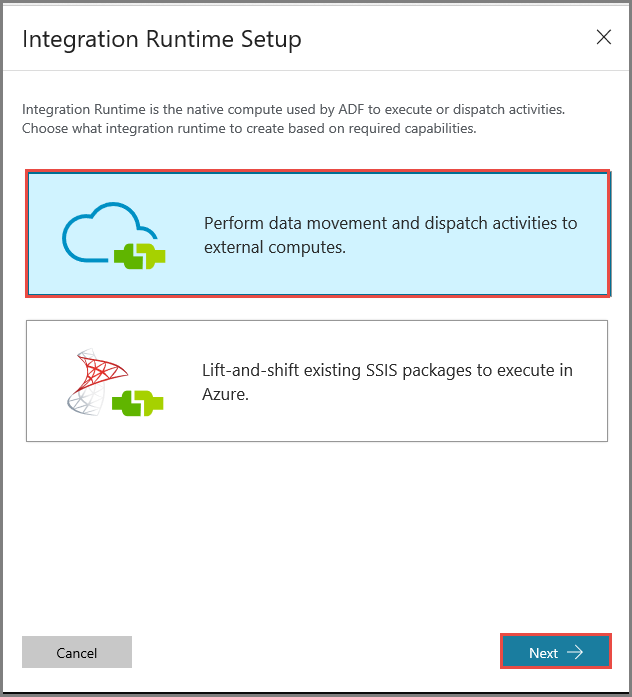
Wybierz pozycję Sieć prywatna i kliknij pozycję Dalej.
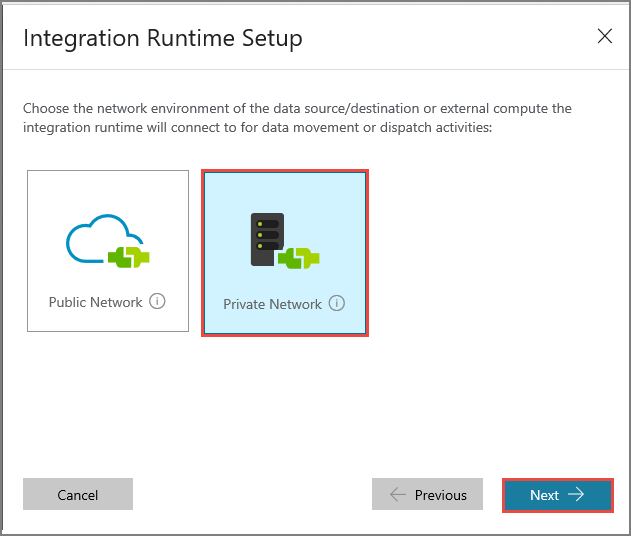
Wprowadź ciąg MySelfHostedIR w polu Nazwa i kliknij pozycję Dalej.
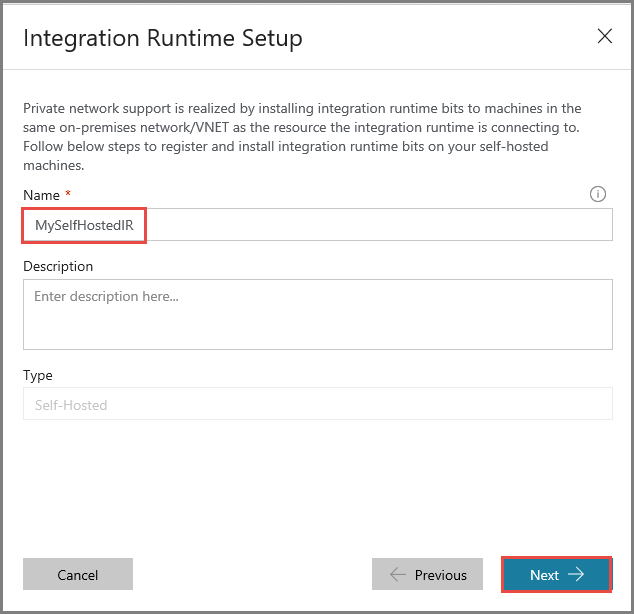
Skopiuj klucz uwierzytelniania środowiska Integration Runtime, klikając przycisk kopiowania, i zapisz go. Nie zamykaj okna. Ten klucz jest używany do rejestrowania środowiska IR zainstalowanego na maszynie wirtualnej.
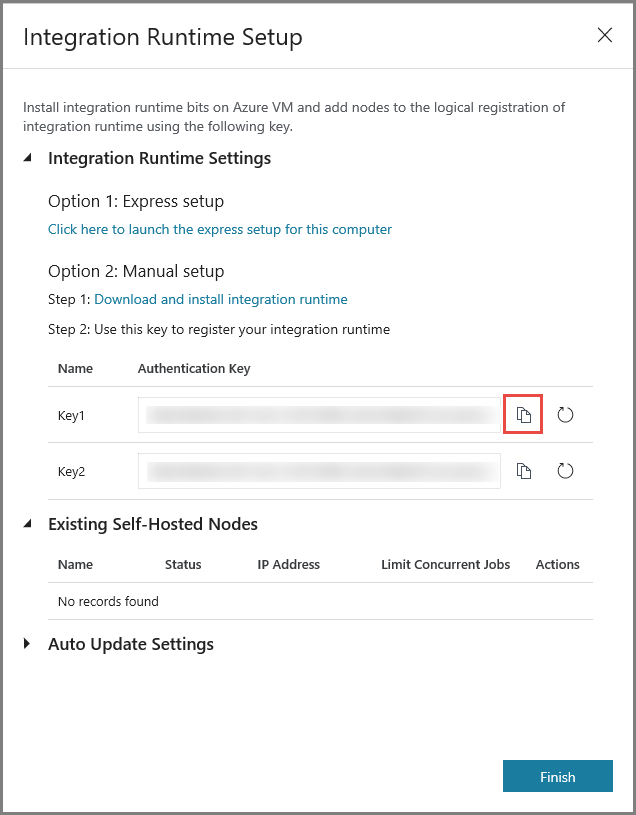
Instalowanie środowiska IR na maszynie wirtualnej
Na maszynę wirtualną platformy Azure pobierz środowisko Integration Runtime (Self-hosted). Użyj klucza uwierzytelniania uzyskanego w poprzednim kroku, aby ręcznie zarejestrować środowisko Integration Runtime (Self-hosted).
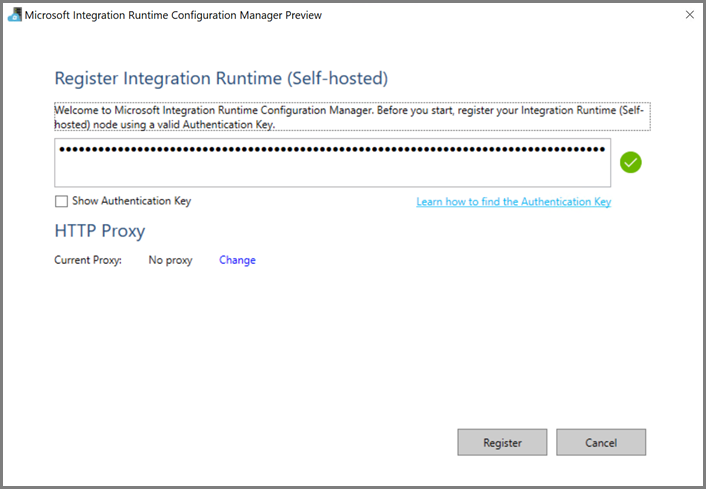
Po pomyślnym zakończeniu rejestrowania środowiska Integration Runtime (self-hosted) zostanie wyświetlony poniższy komunikat.
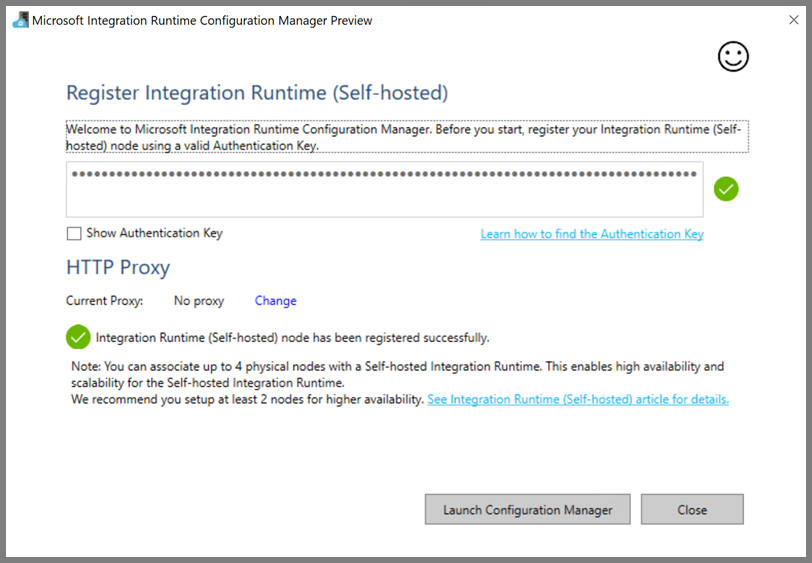
Kliknij pozycję Uruchom program Configuration Manager. Gdy węzeł zostanie połączony z usługą w chmurze, zostanie wyświetlona następująca strona:
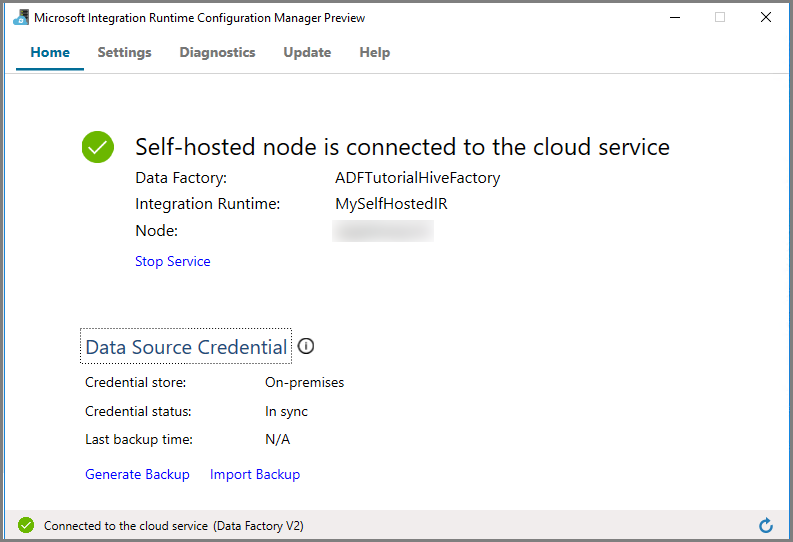
Środowisko IR (Self-hosted) w interfejsie użytkownika usługi Azure Data Factory
W interfejsie użytkownika usługi Azure Data Factory powinna być widoczna nazwa samodzielnie hostowanej maszyny wirtualnej.
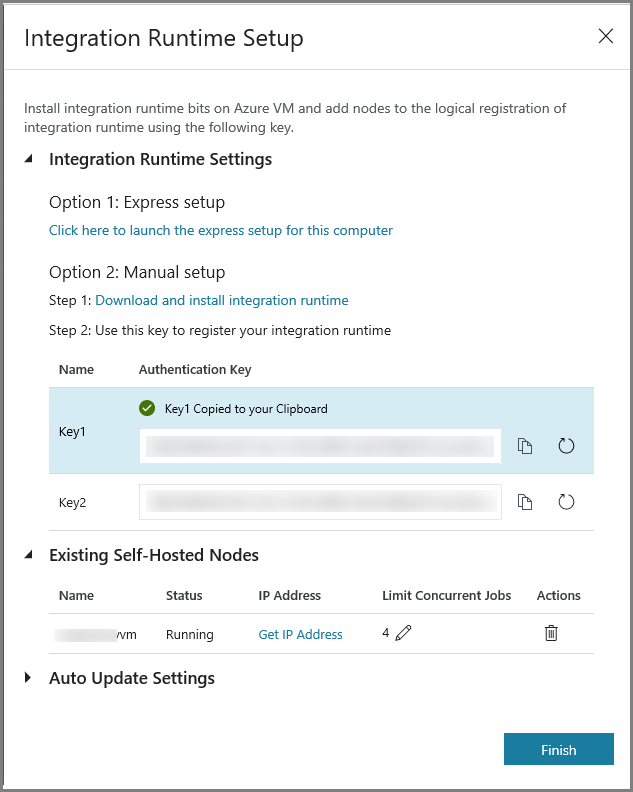
Kliknij pozycję Zakończ, aby zamknąć okno Konfiguracja środowiska Integration Runtime okna. Środowisko IR (Self-hosted) pojawi się na liście środowisk Integration Runtime.

Tworzenie połączonych usług
W tej sekcji zredagujesz i wdrożysz dwie połączone usługi:
- Połączoną usługę Azure Storage, która łączy konto usługi Azure Storage z fabryką danych. Ten magazyn jest podstawowym magazynem używanym przez Twój klaster usługi HDInsight. W takim przypadku używasz konta usługi Azure Storage do przechowywania skryptu programu Hive i przekazywania skryptu na wyjście.
- Połączoną usługę Azure HDInsight. Usługa Azure Data Factory przesyła skrypt Hive do tego klastra usługi HDInsight w celu wykonania.
Tworzenie połączonej usługi Azure Storage
Przejdź do karty Połączone usługi, a następnie kliknij pozycję Nowy.
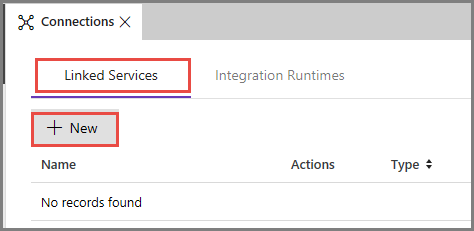
W oknie Nowa połączona usługa wybierz pozycję Azure Blob Storage, a następnie kliknij pozycję Kontynuuj.
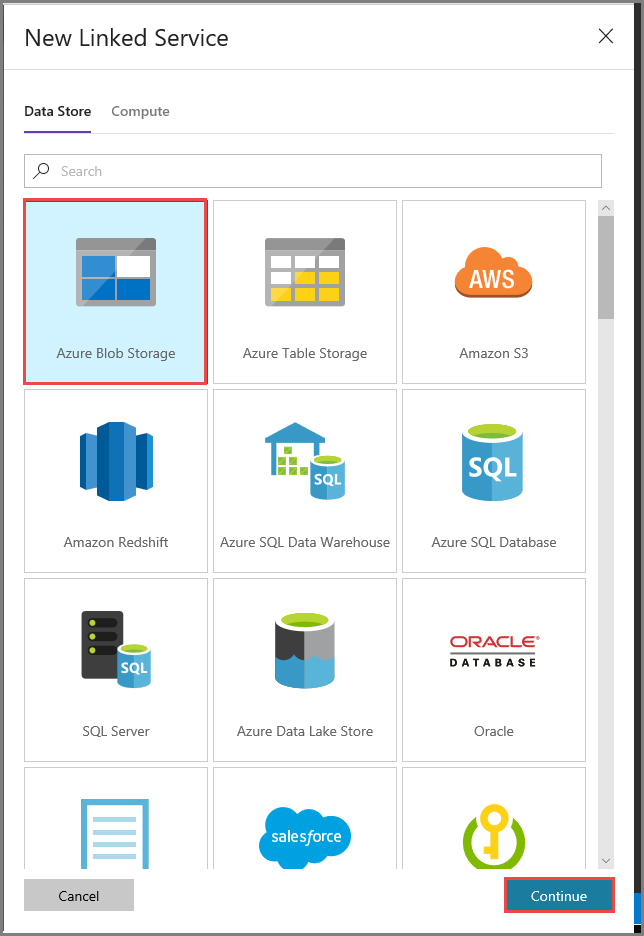
W oknie Nowa połączona usługa wykonaj następujące czynności:
Wprowadź wartość AzureStorageLinkedService w polu Nazwa.
Wybierz pozycję MySelfHostedIR w polu Połącz za pośrednictwem środowiska Integration Runtime.
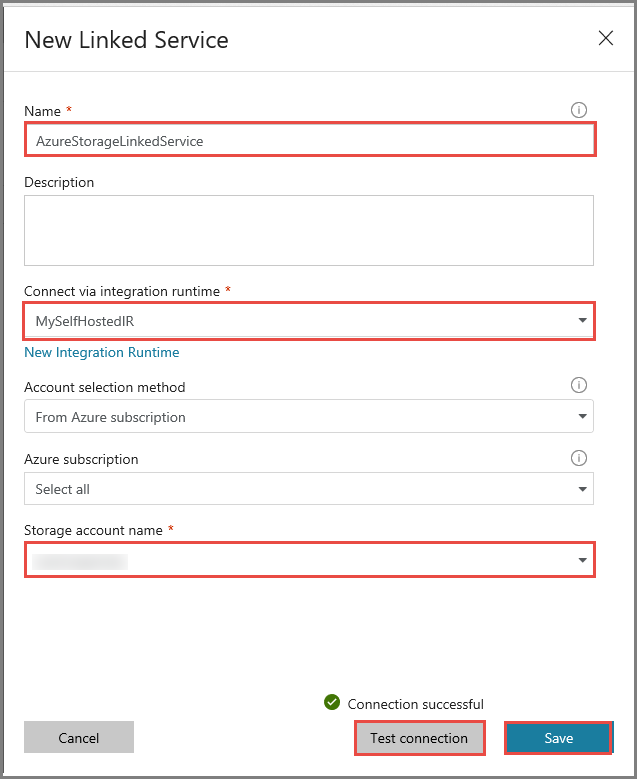
W polu Nazwa konta magazynu wybierz konto usługi Azure Storage.
Aby przetestować połączenie z kontem magazynu, kliknij pozycję Testuj połączenie.
Kliknij przycisk Zapisz.
Tworzenie połączonej usługi HDInsight
Kliknij ponownie pozycję Nowy, aby utworzyć kolejną połączoną usługę.
Przejdź do karty Obliczanie, wybierz pozycję Azure HDInsight i kliknij pozycję Kontynuuj.
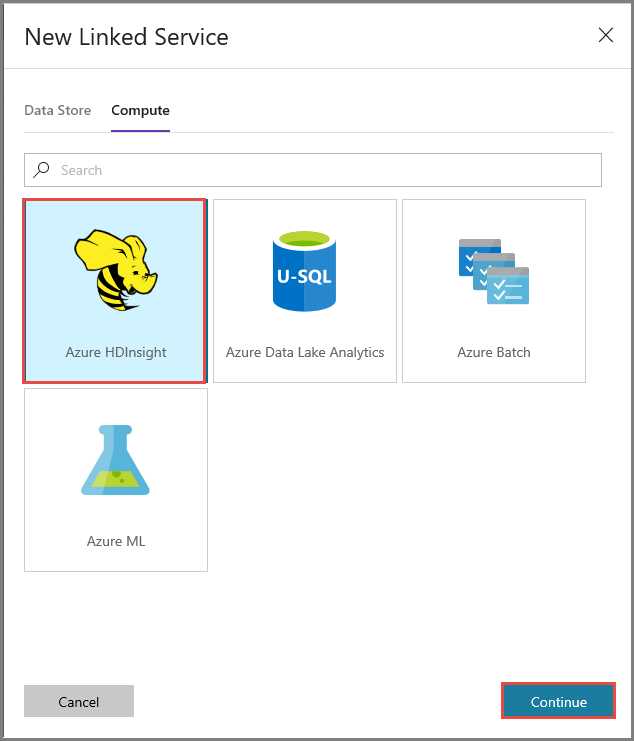
W oknie Nowa połączona usługa wykonaj następujące czynności:
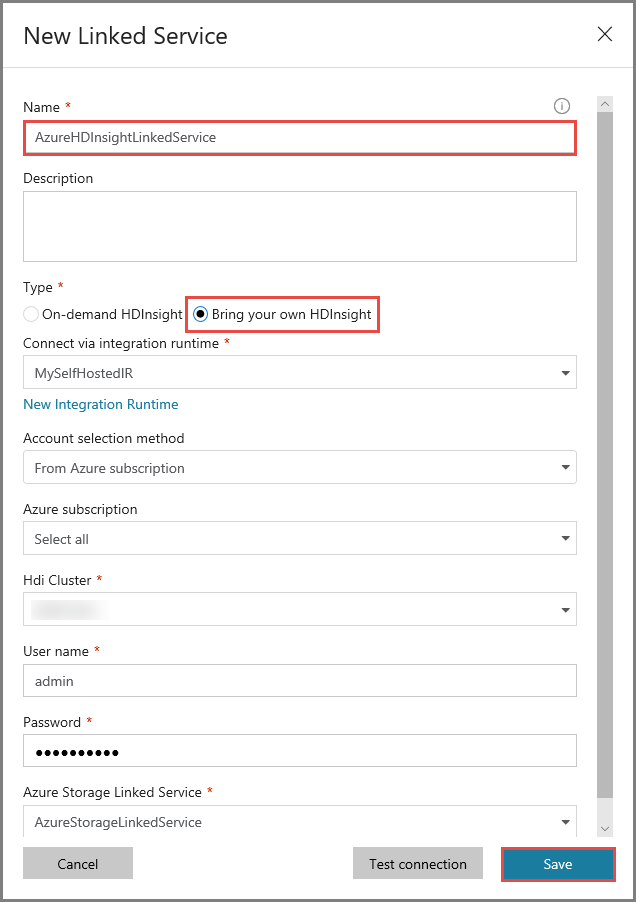
Wprowadź ciąg AzureHDInsightLinkedService w polu Nazwa.
Wybierz pozycję Użyj własnej usługi HDInsight.
Wybierz klaster usługi HDInsight w obszarze Klaster HDI.
Wprowadź nazwę użytkownika dla klastra usługi HDInsight.
Wprowadź hasło dla użytkownika.
W tym artykule przyjęto założenie, że masz dostęp do klastra za pośrednictwem Internetu. Na przykład możesz połączyć się z klastrem pod adresem https://clustername.azurehdinsight.net. Ten adres używa publicznej bramy, która jest niedostępna w przypadku używania sieciowych grup zabezpieczeń lub tras zdefiniowanych przez użytkownika (UDR) do ograniczania dostępu z Internetu. Aby fabryka danych mogła przekazać zadania do klastra usługi HDInsight w usłudze Azure Virtual Network, musisz skonfigurować swoją usługę Azure Virtual Network tak, aby adres URL mógł zostać rozpoznany jako prywatny adres IP bramy używany przez usługę HDInsight.
W witrynie Azure Portal otwórz sieć wirtualną, w której znajduje się usługa HDInsight. Otwórz interfejs sieciowy mający nazwę zaczynającą się od
nic-gateway-0. Zanotuj jego prywatny adres IP. Na przykład 10.6.0.15.Jeśli usługa Azure Virtual Network ma serwer usługi DNS, zaktualizuj rekord usługi DNS tak, aby adres URL klastra usługi HDInsight
https://<clustername>.azurehdinsight.netmożna było rozpoznać jako10.6.0.15. Jeśli w usłudze Azure Virtual Network nie masz serwera DNS, możesz tymczasowo obejść to, edytując plik hosts (C:\Windows\System32\drivers\etc) wszystkich maszyn wirtualnych, które są zarejestrowane jako węzły środowiska Integration Runtime (Self-hosted) przez dodanie wpisu podobnego do następującego:10.6.0.15 myHDIClusterName.azurehdinsight.net
Tworzenie potoku
W tym kroku utworzysz nowy potok za pomocą działania programu Hive. Działanie wykonuje skrypt programu Hive służący do zwracania danych z przykładowej tabeli i zapisania ich w ramach ścieżki zdefiniowanej przez użytkownika.
Należy uwzględnić następujące informacje:
- Argument scriptPath wskazuje ścieżkę do skryptu programu Hive na koncie Azure Storage użytym dla usługi MyStorageLinkedService. W ścieżce jest rozróżniana wielkość liter.
- Output jest argumentem używanym w skrypcie programu Hive. Użyj formatu
wasbs://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/, aby wskazać istniejący folder w usłudze Azure Storage. W ścieżce jest rozróżniana wielkość liter.
W interfejsie użytkownika usługi Data Factory kliknij pozycję + (plus) w lewym okienku, a następnie kliknij pozycję Potok.
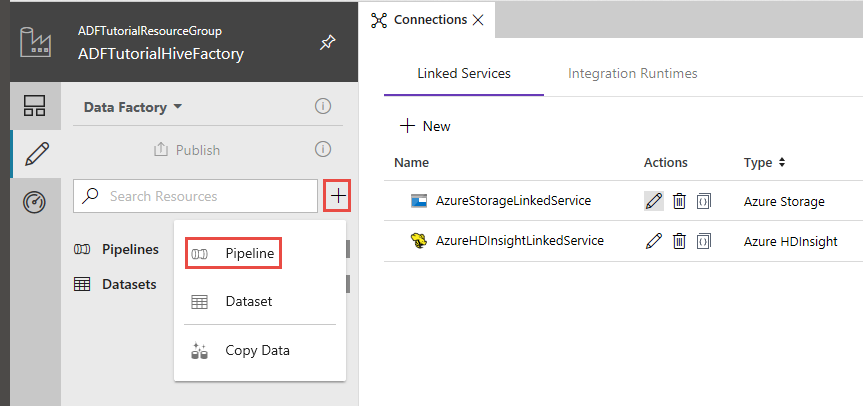
W przyborniku Działania rozwiń pozycję HDInsight, a następnie przeciągnij i upuść działanie Hive do powierzchni projektanta potoku.
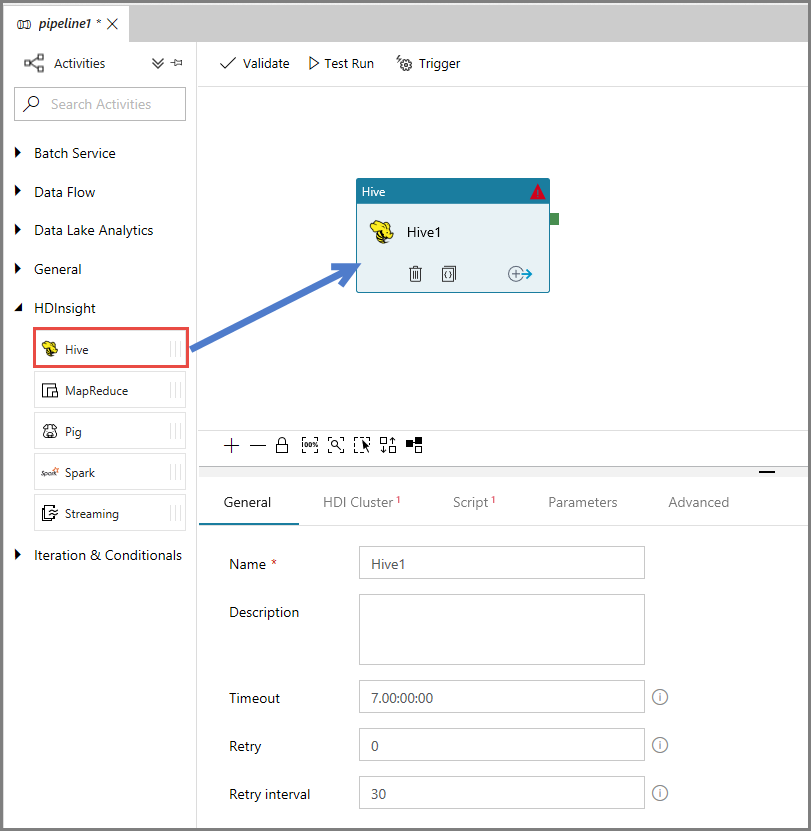
W oknie właściwości przejdź do karty Klaster usługi HDI, a następnie wybierz pozycję AzureHDInsightLinkedService w polu Połączona usługa HDInsight.

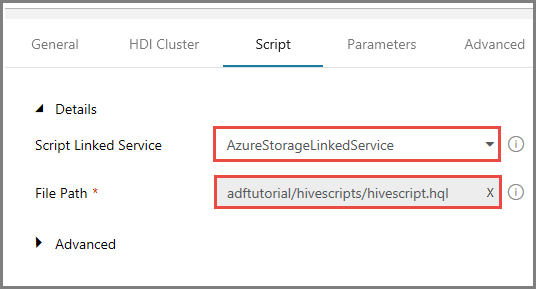
Przejdź do karty Skrypty i wykonaj następujące czynności:
Wybierz pozycję AzureStorageLinkedService w polu Połączona usługa skryptu.
W polu Ścieżka pliku kliknij pozycję Przeglądaj magazyn.
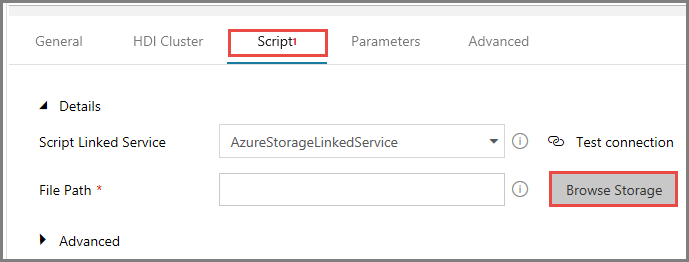
W oknie Wybieranie pliku lub folderu przejdź do folderu hivescripts w kontenerze adftutorial, wybierz plik hivescript.hql, a następnie kliknij przycisk Zakończ.
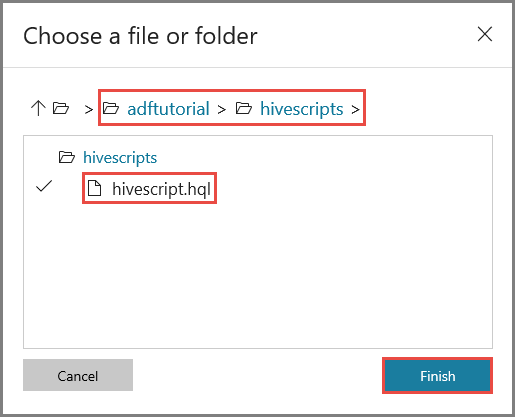
Sprawdź, czy w polu Ścieżka pliku jest widoczna lokalizacja adftutorial/hivescripts/hivescript.hql.
Na karcie Skrypt rozwiń sekcję Zaawansowane.
Kliknij pozycję Automatycznie wypełniaj ze skryptu w obszarze Parametry.
Wprowadź wartość parametru Dane wyjściowe w następującym formacie:
wasbs://<Blob Container>@<StorageAccount>.blob.core.windows.net/outputfolder/. Na przykład:wasbs://adftutorial@mystorageaccount.blob.core.windows.net/outputfolder/.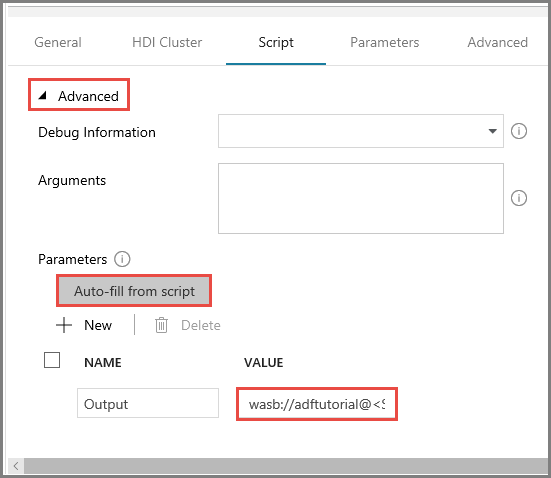
Aby opublikować artefakty do usługi Data Factory, kliknij pozycję Opublikuj.
Wyzwalanie uruchomienia potoku
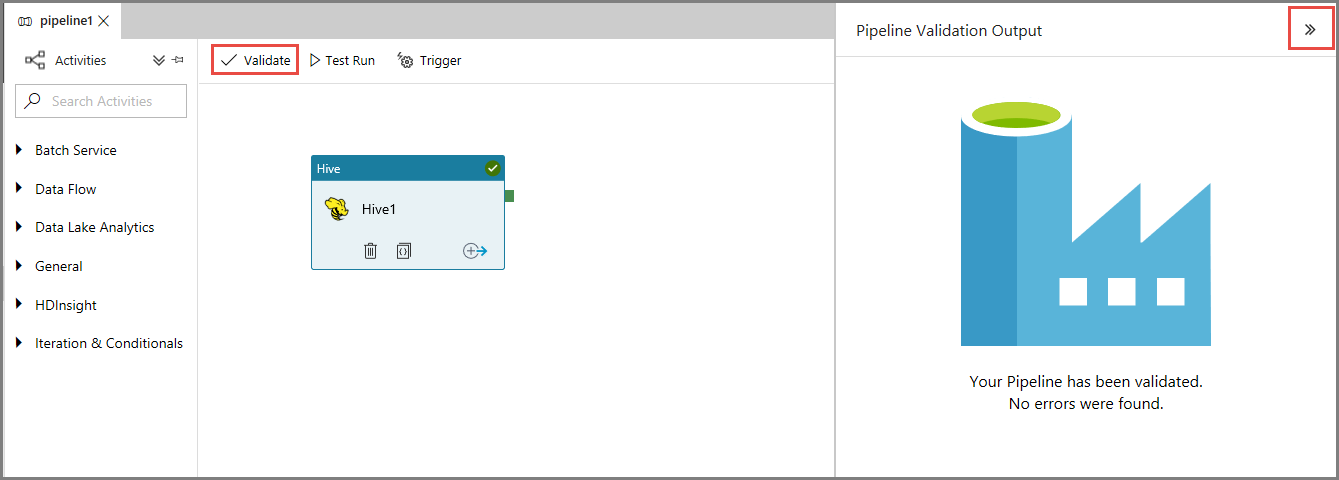
Najpierw zweryfikuj potok, klikając przycisk Weryfikuj na pasku narzędzi. Zamknij okno Dane wyjściowe weryfikacji potoku, klikając strzałkę w prawo (>>).
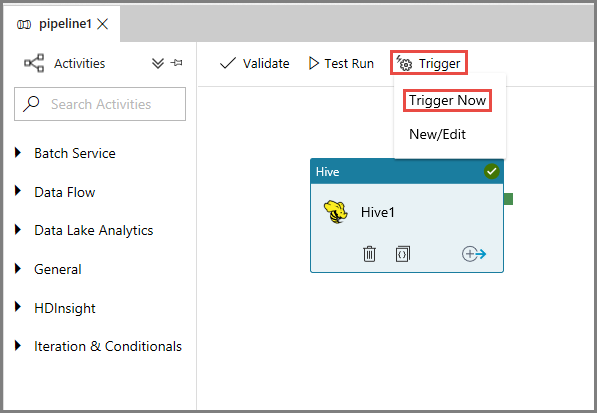
Aby wyzwolić uruchomienie potoku, kliknij pozycję Wyzwól na pasku narzędzi, a następnie kliknij polecenie Wyzwól teraz.
Monitorowanie działania potoku
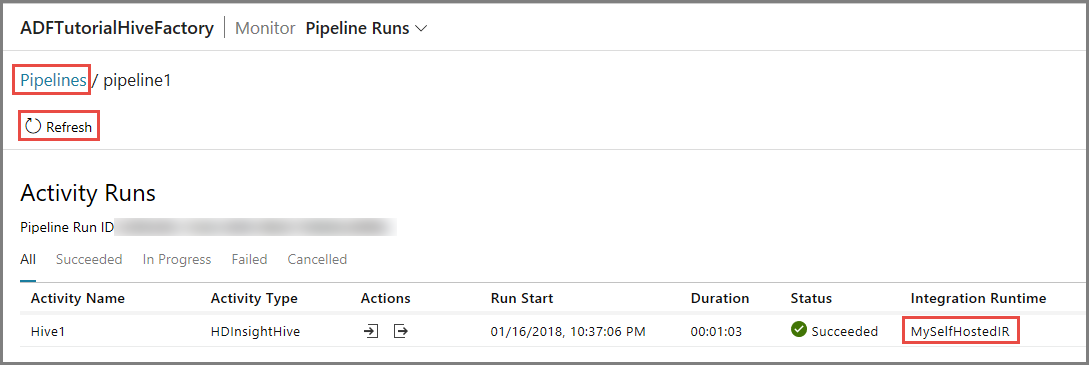
Przejdź do karty Monitorowanie po lewej stronie. Uruchomienie potoku zostanie wyświetlone na liście Uruchomienia potoku.
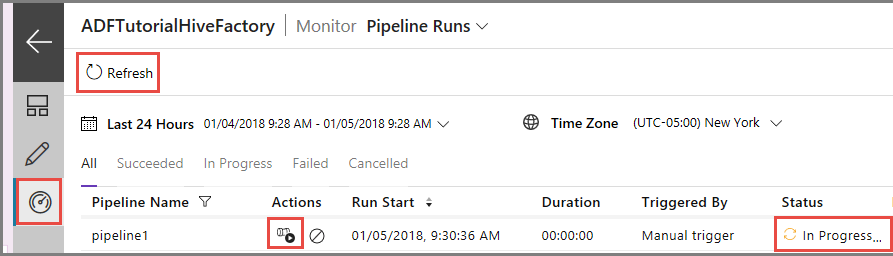
Aby odświeżyć listę, kliknij pozycję Odśwież.
Aby wyświetlić uruchomienia działań skojarzone z uruchomieniami potoku, kliknij pozycję Wyświetl uruchomienia działań w kolumnie Akcje. Inne linki akcji służą do zatrzymywania/ponownego uruchamiania potoku.
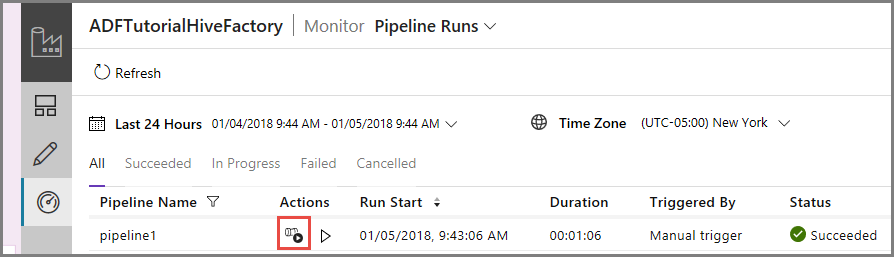
Zobaczysz tylko jedno uruchomienie działania, ponieważ w potoku typu HDInsightHive jest tylko jedno działanie. Aby wrócić do poprzedniego widoku, kliknij link Potoki w górnej części strony.
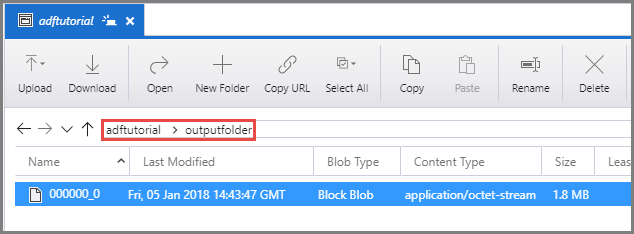
Sprawdź, czy plik wyjściowy znajduje się w folderze outputfolder kontenera adftutorial.
Powiązana zawartość
W ramach tego samouczka wykonano następujące procedury:
- Tworzenie fabryki danych.
- Tworzenie własnego środowiska Integration Runtime
- Tworzenie połączonych usług Azure Storage i Azure HDInsight
- Tworzenie potoku przy użycia działania Hive
- Wyzwalanie uruchomienia potoku.
- Monitorowanie działania potoku
- Sprawdzanie danych wyjściowych
Przejdź do następującego samouczka, aby dowiedzieć się więcej o przekształcaniu danych za pomocą klastra Spark na platformie Azure: