Rozgałęzianie działań i tworzenie łańcuchów działań w potoku usługi Data Factory
DOTYCZY:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
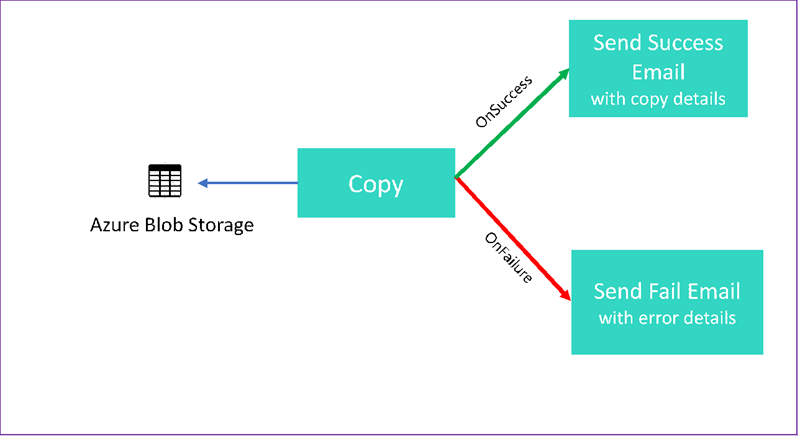
W tym samouczku utworzysz potok usługi Data Factory, który prezentuje niektóre funkcje przepływu sterowania. Ten potok kopiuje z kontenera w usłudze Azure Blob Storage do innego kontenera na tym samym koncie magazynu. Jeśli działanie kopiowania zakończy się pomyślnie, potok wysyła szczegóły pomyślnej operacji kopiowania w wiadomości e-mail. Te informacje mogą obejmować ilość zapisanych danych. Jeśli działanie kopiowania nie powiedzie się, wysyła szczegóły błędu kopiowania, takie jak komunikat o błędzie, w wiadomości e-mail. W samouczku pokazano, jak przekazać parametry.
Ta grafika zawiera omówienie scenariusza:
W tym samouczku przedstawiono sposób wykonywania następujących zadań:
- Tworzenie fabryki danych
- Tworzenie połączonej usługi Azure Storage
- Tworzenie zestawu danych obiektów blob platformy Azure
- Tworzenie potoku zawierającego działanie kopiowania i działanie internetowe
- Wysyłanie danych wyjściowych działań do kolejnych działań
- Używanie przekazywania parametrów i zmiennych systemowych
- Uruchamianie potoku
- Monitorowanie uruchomień działań i potoku
W tym samouczku jest używany zestaw SDK platformy .NET. Do interakcji z usługą Azure Data Factory można użyć innych mechanizmów. Aby zapoznać się z przewodnikami Szybki start usługi Data Factory, zobacz 5-minutowe przewodniki Szybki start.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
- Konto usługi Azure Storage. Magazyn obiektów blob jest używany jako źródłowy magazyn danych. Jeśli nie masz konta usługi Azure Storage, zobacz Tworzenie konta magazynu.
- Eksplorator magazynu Azure. Aby zainstalować to narzędzie, zobacz Eksplorator usługi Azure Storage.
- Usługa Azure SQL Database. Baza danych jest używana jako magazyn danych będący ujściem. Jeśli nie masz bazy danych w usłudze Azure SQL Database, zobacz Tworzenie bazy danych w usłudze Azure SQL Database.
- Visual Studio. W tym artykule jest używany program Visual Studio 2019.
- Zestaw .NET SDK platformy Azure. Pobierz i zainstaluj zestaw AZURE .NET SDK.
Aby uzyskać listę regionów świadczenia usługi Azure, w których usługa Data Factory jest obecnie dostępna, zobacz Dostępność produktów według regionów. Magazyny danych i obliczenia mogą znajdować się w innych regionach. Magazyny obejmują usługi Azure Storage i Azure SQL Database. Obliczenia obejmują usługę HDInsight, której używa usługa Data Factory.
Utwórz aplikację zgodnie z opisem w temacie Tworzenie aplikacji firmy Microsoft Entra. Przypisz aplikację do roli Współautor , postępując zgodnie z instrukcjami w tym samym artykule. W kolejnych częściach tego samouczka będzie potrzebnych kilka wartości, takich jak identyfikator aplikacji (klienta) i identyfikator katalogu (dzierżawy).
Tworzenie tabeli obiektów blob
Uruchom edytor tekstów. Skopiuj następujący tekst i zapisz go lokalnie jako input.txt.
Ethel|Berg Tamika|WalshOtwórz Eksplorator usługi Azure Storage. Rozwiń konto magazynu. Kliknij prawym przyciskiem myszy pozycję Blob Containers (Kontenery obiektów blob) i wybierz polecenie Create Blob Container (Utwórz kontener obiektów blob).
Nadaj nowemu kontenerowi nazwę adfv2branch i wybierz pozycję Przekaż , aby dodać plik input.txt do kontenera.
Tworzenie projektu programu Visual Studio
Utwórz aplikację konsolową platformy .NET w języku C#:
- Uruchom program Visual Studio i wybierz pozycję Utwórz nowy projekt.
- W obszarze Utwórz nowy projekt wybierz pozycję Aplikacja konsolowa (.NET Framework) dla języka C#, a następnie wybierz pozycję Dalej.
- Nadaj projektowi nazwę ADFv2BranchTutorial.
- Wybierz pozycję .NET w wersji 4.5.2 lub nowszej, a następnie wybierz pozycję Utwórz.
Instalowanie pakietów NuGet
Wybierz pozycję Narzędzia NuGet>Menedżer pakietów> Menedżer pakietów Konsola.
W oknie Konsola menedżera pakietów uruchom następujące polecenia, aby zainstalować pakiety. Aby uzyskać szczegółowe informacje, zapoznaj się z pakietem NuGet Microsoft.Azure.Management.DataFactory.
Install-Package Microsoft.Azure.Management.DataFactory Install-Package Microsoft.Azure.Management.ResourceManager -IncludePrerelease Install-Package Microsoft.IdentityModel.Clients.ActiveDirectory
Tworzenie klienta fabryki danych
Otwórz Program.cs i dodaj następujące instrukcje:
using System; using System.Collections.Generic; using System.Linq; using Microsoft.Rest; using Microsoft.Azure.Management.ResourceManager; using Microsoft.Azure.Management.DataFactory; using Microsoft.Azure.Management.DataFactory.Models; using Microsoft.IdentityModel.Clients.ActiveDirectory;Dodaj te zmienne statyczne do
Programklasy. Zastąp symbole zastępcze własnymi wartościami.// Set variables static string tenantID = "<tenant ID>"; static string applicationId = "<application ID>"; static string authenticationKey = "<Authentication key for your application>"; static string subscriptionId = "<Azure subscription ID>"; static string resourceGroup = "<Azure resource group name>"; static string region = "East US"; static string dataFactoryName = "<Data factory name>"; // Specify the source Azure Blob information static string storageAccount = "<Azure Storage account name>"; static string storageKey = "<Azure Storage account key>"; // confirm that you have the input.txt file placed in th input folder of the adfv2branch container. static string inputBlobPath = "adfv2branch/input"; static string inputBlobName = "input.txt"; static string outputBlobPath = "adfv2branch/output"; static string emailReceiver = "<specify email address of the receiver>"; static string storageLinkedServiceName = "AzureStorageLinkedService"; static string blobSourceDatasetName = "SourceStorageDataset"; static string blobSinkDatasetName = "SinkStorageDataset"; static string pipelineName = "Adfv2TutorialBranchCopy"; static string copyBlobActivity = "CopyBlobtoBlob"; static string sendFailEmailActivity = "SendFailEmailActivity"; static string sendSuccessEmailActivity = "SendSuccessEmailActivity";Dodaj następujący kod do metody
Main: Ten kod tworzy wystąpienieDataFactoryManagementClientklasy. Następnie użyjesz tego obiektu do utworzenia fabryki danych, połączonej usługi, zestawów danych i potoku. Tego obiektu można również użyć do monitorowania szczegółów przebiegu potoku.// Authenticate and create a data factory management client var context = new AuthenticationContext("https://login.windows.net/" + tenantID); ClientCredential cc = new ClientCredential(applicationId, authenticationKey); AuthenticationResult result = context.AcquireTokenAsync("https://management.azure.com/", cc).Result; ServiceClientCredentials cred = new TokenCredentials(result.AccessToken); var client = new DataFactoryManagementClient(cred) { SubscriptionId = subscriptionId };
Tworzenie fabryki danych
Dodaj metodę
CreateOrUpdateDataFactorydo pliku Program.cs :static Factory CreateOrUpdateDataFactory(DataFactoryManagementClient client) { Console.WriteLine("Creating data factory " + dataFactoryName + "..."); Factory resource = new Factory { Location = region }; Console.WriteLine(SafeJsonConvert.SerializeObject(resource, client.SerializationSettings)); Factory response; { response = client.Factories.CreateOrUpdate(resourceGroup, dataFactoryName, resource); } while (client.Factories.Get(resourceGroup, dataFactoryName).ProvisioningState == "PendingCreation") { System.Threading.Thread.Sleep(1000); } return response; }Dodaj następujący wiersz do
Mainmetody, która tworzy fabrykę danych:Factory df = CreateOrUpdateDataFactory(client);
Tworzenie połączonej usługi Azure Storage
Dodaj metodę
StorageLinkedServiceDefinitiondo pliku Program.cs :static LinkedServiceResource StorageLinkedServiceDefinition(DataFactoryManagementClient client) { Console.WriteLine("Creating linked service " + storageLinkedServiceName + "..."); AzureStorageLinkedService storageLinkedService = new AzureStorageLinkedService { ConnectionString = new SecureString("DefaultEndpointsProtocol=https;AccountName=" + storageAccount + ";AccountKey=" + storageKey) }; Console.WriteLine(SafeJsonConvert.SerializeObject(storageLinkedService, client.SerializationSettings)); LinkedServiceResource linkedService = new LinkedServiceResource(storageLinkedService, name:storageLinkedServiceName); return linkedService; }Dodaj następujący wiersz do
Mainmetody, która tworzy połączoną usługę Azure Storage:client.LinkedServices.CreateOrUpdate(resourceGroup, dataFactoryName, storageLinkedServiceName, StorageLinkedServiceDefinition(client));
Aby uzyskać więcej informacji na temat obsługiwanych właściwości i szczegółów, zobacz Właściwości połączonej usługi.
Tworzenie zestawów danych
W tej sekcji utworzysz dwa zestawy danych— jeden dla źródła i jeden dla ujścia.
Tworzenie zestawu danych dla źródłowego obiektu blob platformy Azure
Dodaj metodę, która tworzy zestaw danych obiektów blob platformy Azure. Aby uzyskać więcej informacji na temat obsługiwanych właściwości i szczegółów, zobacz Właściwości zestawu danych obiektów blob platformy Azure.
Dodaj metodę SourceBlobDatasetDefinition do pliku Program.cs :
static DatasetResource SourceBlobDatasetDefinition(DataFactoryManagementClient client)
{
Console.WriteLine("Creating dataset " + blobSourceDatasetName + "...");
AzureBlobDataset blobDataset = new AzureBlobDataset
{
FolderPath = new Expression { Value = "@pipeline().parameters.sourceBlobContainer" },
FileName = inputBlobName,
LinkedServiceName = new LinkedServiceReference
{
ReferenceName = storageLinkedServiceName
}
};
Console.WriteLine(SafeJsonConvert.SerializeObject(blobDataset, client.SerializationSettings));
DatasetResource dataset = new DatasetResource(blobDataset, name:blobSourceDatasetName);
return dataset;
}
Należy zdefiniować zestaw danych reprezentujący źródło danych w obiekcie blob platformy Azure. Ten zestaw danych obiektów blob odnosi się do połączonej usługi Azure Storage obsługiwanej w poprzednim kroku. Zestaw danych obiektów blob opisuje lokalizację obiektu blob do skopiowania z: FolderPath i FileName.
Zwróć uwagę na użycie parametrów dla folderuPath. sourceBlobContainer to nazwa parametru, a wyrażenie jest zastępowane wartościami przekazanymi w przebiegu potoku. Składnia umożliwiająca zdefiniowanie parametrów: @pipeline().parameters.<parameterName>
Tworzenie zestawu danych dla ujścia obiektu blob platformy Azure
Dodaj metodę
SourceBlobDatasetDefinitiondo pliku Program.cs :static DatasetResource SinkBlobDatasetDefinition(DataFactoryManagementClient client) { Console.WriteLine("Creating dataset " + blobSinkDatasetName + "..."); AzureBlobDataset blobDataset = new AzureBlobDataset { FolderPath = new Expression { Value = "@pipeline().parameters.sinkBlobContainer" }, LinkedServiceName = new LinkedServiceReference { ReferenceName = storageLinkedServiceName } }; Console.WriteLine(SafeJsonConvert.SerializeObject(blobDataset, client.SerializationSettings)); DatasetResource dataset = new DatasetResource(blobDataset, name: blobSinkDatasetName); return dataset; }Dodaj następujący kod do
Mainmetody, która tworzy zestawy danych źródła obiektów blob platformy Azure i ujścia.client.Datasets.CreateOrUpdate(resourceGroup, dataFactoryName, blobSourceDatasetName, SourceBlobDatasetDefinition(client)); client.Datasets.CreateOrUpdate(resourceGroup, dataFactoryName, blobSinkDatasetName, SinkBlobDatasetDefinition(client));
Tworzenie klasy języka C#: EmailRequest
W projekcie języka C# utwórz klasę o nazwie EmailRequest. Ta klasa definiuje właściwości, które potok wysyła w żądaniu treści podczas wysyłania wiadomości e-mail. W tym samouczku potok wysyła cztery właściwości z potoku do wiadomości e-mail:
- Wiadomość. Treść wiadomości e-mail. W przypadku pomyślnej kopii ta właściwość zawiera ilość zapisanych danych. W przypadku nieudanej kopii ta właściwość zawiera szczegóły błędu.
- Nazwa fabryki danych. Nazwa fabryki danych.
- Nazwa potoku. Nazwa potoku.
- Odbiornik. Parametr, który przechodzi przez. Ta właściwość określa odbiorcę wiadomości e-mail.
class EmailRequest
{
[Newtonsoft.Json.JsonProperty(PropertyName = "message")]
public string message;
[Newtonsoft.Json.JsonProperty(PropertyName = "dataFactoryName")]
public string dataFactoryName;
[Newtonsoft.Json.JsonProperty(PropertyName = "pipelineName")]
public string pipelineName;
[Newtonsoft.Json.JsonProperty(PropertyName = "receiver")]
public string receiver;
public EmailRequest(string input, string df, string pipeline, string receiverName)
{
message = input;
dataFactoryName = df;
pipelineName = pipeline;
receiver = receiverName;
}
}
Tworzenie punktów końcowych przepływu pracy poczty e-mail
Aby wyzwolić wysyłanie wiadomości e-mail, użyjesz usługi Azure Logic Apps do zdefiniowania przepływu pracy. Aby uzyskać więcej informacji, zobacz Tworzenie przykładowego przepływu pracy aplikacji logiki zużycie.
Przepływ pracy wiadomości e-mail z informacją o powodzeniu
W witrynie Azure Portal utwórz przepływ pracy aplikacji logiki o nazwie CopySuccessEmail. Dodaj wyzwalacz Żądania o nazwie Po odebraniu żądania HTTP. W wyzwalaczu Żądanie wypełnij pole schematu JSON Treść żądania następującym kodem JSON:
{
"properties": {
"dataFactoryName": {
"type": "string"
},
"message": {
"type": "string"
},
"pipelineName": {
"type": "string"
},
"receiver": {
"type": "string"
}
},
"type": "object"
}
Przepływ pracy wygląda podobnie do następującego przykładu:
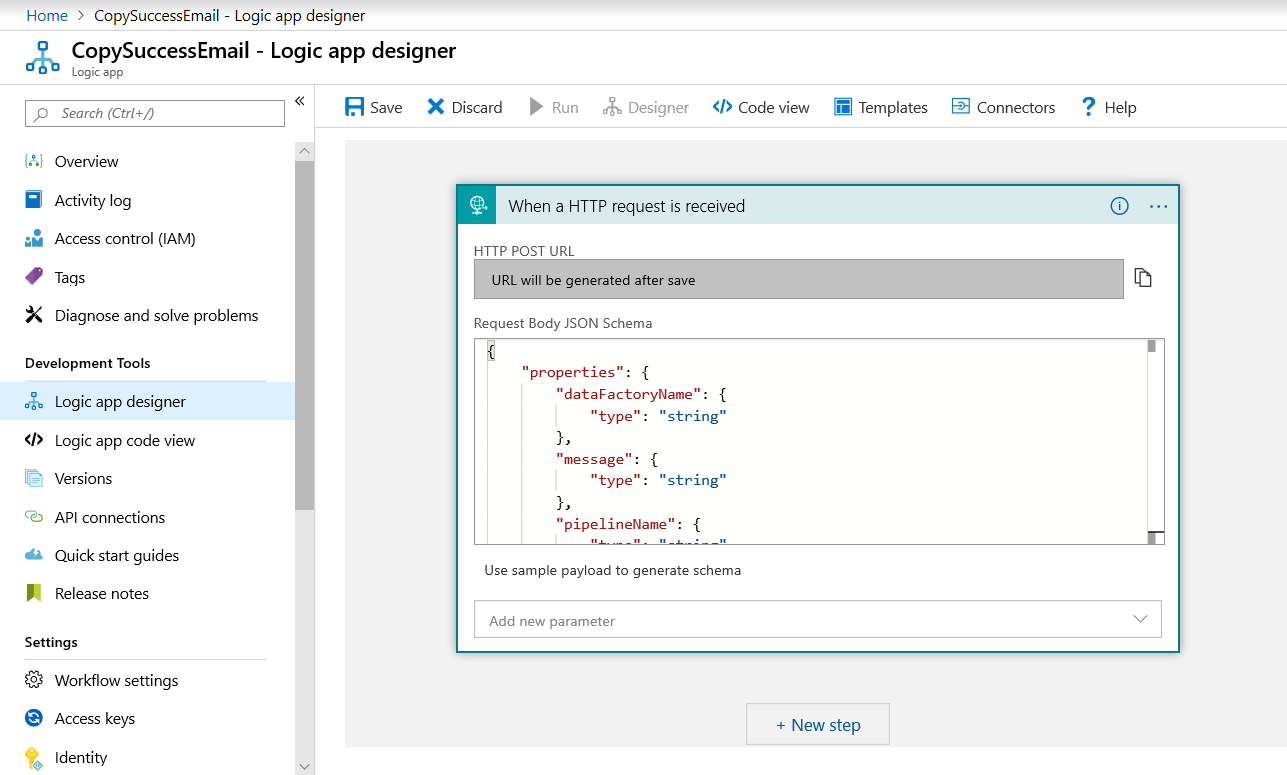
Ta zawartość JSON jest zgodna z klasą EmailRequest utworzoną w poprzedniej sekcji.
Dodaj akcję usługi Office 365 Outlook o nazwie Wyślij wiadomość e-mail. W przypadku tej akcji dostosuj sposób formatowania wiadomości e-mail przy użyciu właściwości przekazanych w schemacie JSON treści żądania. Oto przykład:
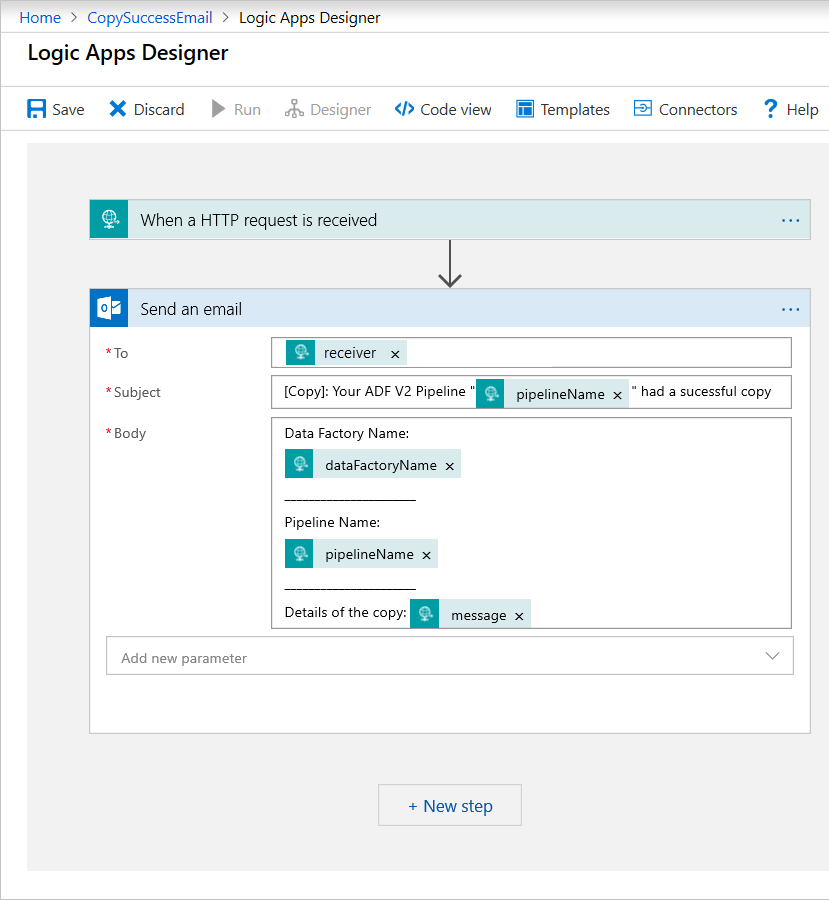
Po zapisaniu przepływu pracy skopiuj i zapisz wartość adresu URL HTTP POST z wyzwalacza.
Przepływ pracy wiadomości e-mail z informacją o niepowodzeniu
Sklonuj CopySuccessEmail przepływ pracy aplikacji logiki do nowego przepływu pracy o nazwie CopyFailEmail. W wyzwalaczu Żądanie schemat JSON treści żądania jest taki sam. Zmień format wiadomości e-mail, na przykład element Subject, aby przekształcić wiadomość e-mail w wiadomość z informacją o niepowodzeniu. Oto przykład:
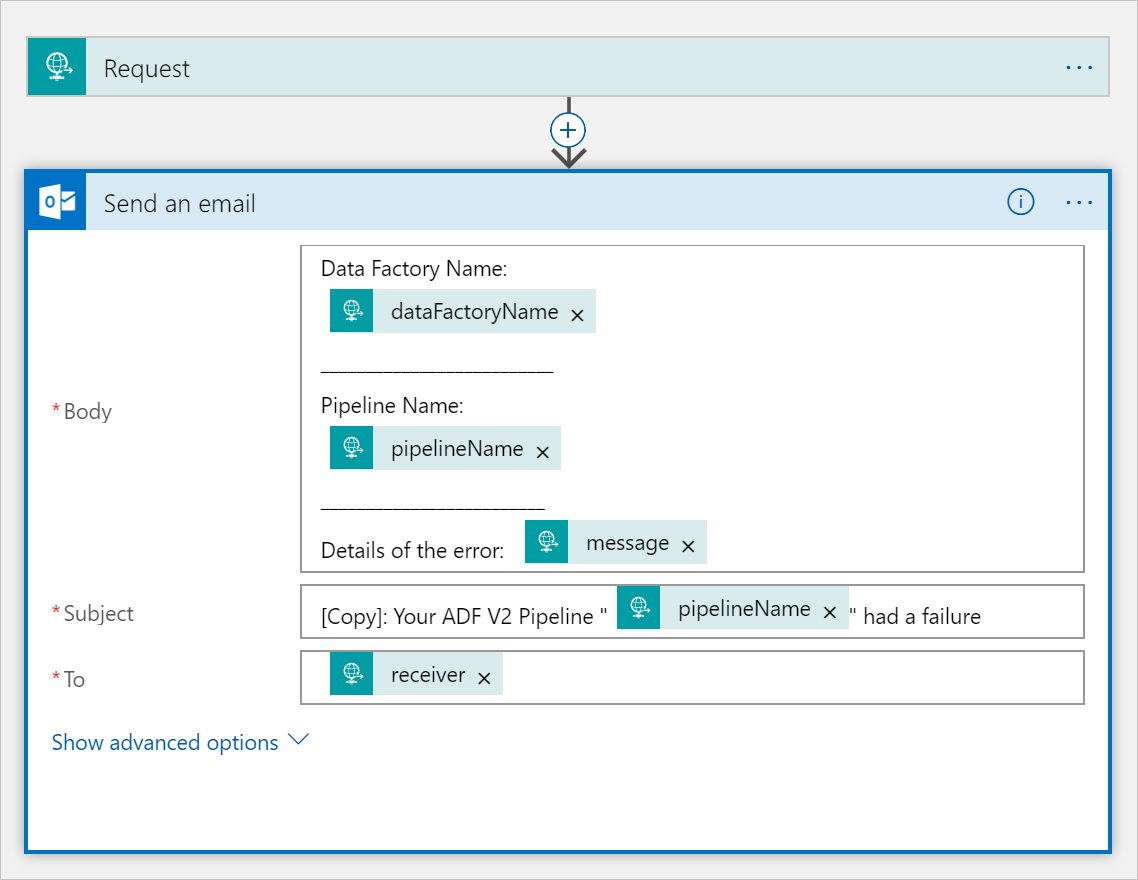
Po zapisaniu przepływu pracy skopiuj i zapisz wartość adresu URL HTTP POST z wyzwalacza.
Teraz powinny istnieć dwa adresy URL przepływu pracy, takie jak następujące przykłady:
//Success Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
//Fail Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Tworzenie potoku
Wróć do projektu w programie Visual Studio. Teraz dodamy kod, który tworzy potok z działaniem kopiowania i DependsOn właściwością. W tym samouczku potok zawiera jedno działanie, działanie kopiowania, które przyjmuje zestaw danych obiektów blob jako źródło i inny zestaw danych obiektów blob jako ujście. Jeśli działanie kopiowania zakończy się pomyślnie lub zakończy się niepowodzeniem, wywołuje różne zadania poczty e-mail.
W tym potoku użyto następujących funkcji:
- Parametry
- Działanie w sieci Web
- Zależność działania
- Używanie danych wyjściowych z działania jako danych wejściowych do innego działania
Dodaj tę metodę do projektu. Poniższe sekcje zawierają bardziej szczegółowe informacje.
static PipelineResource PipelineDefinition(DataFactoryManagementClient client) { Console.WriteLine("Creating pipeline " + pipelineName + "..."); PipelineResource resource = new PipelineResource { Parameters = new Dictionary<string, ParameterSpecification> { { "sourceBlobContainer", new ParameterSpecification { Type = ParameterType.String } }, { "sinkBlobContainer", new ParameterSpecification { Type = ParameterType.String } }, { "receiver", new ParameterSpecification { Type = ParameterType.String } } }, Activities = new List<Activity> { new CopyActivity { Name = copyBlobActivity, Inputs = new List<DatasetReference> { new DatasetReference { ReferenceName = blobSourceDatasetName } }, Outputs = new List<DatasetReference> { new DatasetReference { ReferenceName = blobSinkDatasetName } }, Source = new BlobSource { }, Sink = new BlobSink { } }, new WebActivity { Name = sendSuccessEmailActivity, Method = WebActivityMethod.POST, Url = "https://prodxxx.eastus.logic.azure.com:443/workflows/00000000000000000000000000000000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=0000000000000000000000000000000000000000000000", Body = new EmailRequest("@{activity('CopyBlobtoBlob').output.dataWritten}", "@{pipeline().DataFactory}", "@{pipeline().Pipeline}", "@pipeline().parameters.receiver"), DependsOn = new List<ActivityDependency> { new ActivityDependency { Activity = copyBlobActivity, DependencyConditions = new List<String> { "Succeeded" } } } }, new WebActivity { Name = sendFailEmailActivity, Method =WebActivityMethod.POST, Url = "https://prodxxx.eastus.logic.azure.com:443/workflows/000000000000000000000000000000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=0000000000000000000000000000000000000000000", Body = new EmailRequest("@{activity('CopyBlobtoBlob').error.message}", "@{pipeline().DataFactory}", "@{pipeline().Pipeline}", "@pipeline().parameters.receiver"), DependsOn = new List<ActivityDependency> { new ActivityDependency { Activity = copyBlobActivity, DependencyConditions = new List<String> { "Failed" } } } } } }; Console.WriteLine(SafeJsonConvert.SerializeObject(resource, client.SerializationSettings)); return resource; }Dodaj następujący wiersz do
Mainmetody, która tworzy potok:client.Pipelines.CreateOrUpdate(resourceGroup, dataFactoryName, pipelineName, PipelineDefinition(client));
Parametry
Pierwsza sekcja kodu potoku definiuje parametry.
sourceBlobContainer. Źródłowy zestaw danych obiektów blob używa tego parametru w potoku.sinkBlobContainer. Zestaw danych obiektów blob ujścia używa tego parametru w potoku.receiver. Dwa działania sieci Web w potoku, które wysyłają wiadomości e-mail o powodzeniu lub niepowodzeniu do odbiorcy, używają tego parametru.
Parameters = new Dictionary<string, ParameterSpecification>
{
{ "sourceBlobContainer", new ParameterSpecification { Type = ParameterType.String } },
{ "sinkBlobContainer", new ParameterSpecification { Type = ParameterType.String } },
{ "receiver", new ParameterSpecification { Type = ParameterType.String } }
},
Działanie w sieci Web
Działanie internetowe umożliwia wywołanie dowolnego punktu końcowego REST. Aby uzyskać więcej informacji na temat działania, zobacz Działanie internetowe w usłudze Azure Data Factory. Ten potok używa działania internetowego do wywoływania przepływu pracy poczty e-mail usługi Logic Apps. Utworzysz dwa działania internetowe: jedno, które wywołuje CopySuccessEmail przepływ pracy i jedno, które wywołuje element CopyFailWorkFlow.
new WebActivity
{
Name = sendCopyEmailActivity,
Method = WebActivityMethod.POST,
Url = "https://prodxxx.eastus.logic.azure.com:443/workflows/12345",
Body = new EmailRequest("@{activity('CopyBlobtoBlob').output.dataWritten}", "@{pipeline().DataFactory}", "@{pipeline().Pipeline}", "@pipeline().parameters.receiver"),
DependsOn = new List<ActivityDependency>
{
new ActivityDependency
{
Activity = copyBlobActivity,
DependencyConditions = new List<String> { "Succeeded" }
}
}
}
Url W właściwości wklej punkty końcowe adresu URL HTTP POST z przepływów pracy usługi Logic Apps. Body We właściwości przekaż wystąpienie EmailRequest klasy . Żądanie wiadomości e-mail zawiera następujące właściwości:
- Wiadomość. Przekazuje wartość
@{activity('CopyBlobtoBlob').output.dataWritten. Uzyskuje dostęp do właściwości poprzedniego działania kopiowania i przekazuje wartośćdataWritten. W przypadku wiadomości dotyczącej niepowodzenia przekaż dane wyjściowe błędu zamiast elementu@{activity('CopyBlobtoBlob').error.message. - Nazwa fabryki danych. Przekazuje wartość Tej zmiennej
@{pipeline().DataFactory}systemowej umożliwia dostęp do odpowiedniej nazwy fabryki danych. Aby uzyskać listę zmiennych systemowych, zobacz Zmienne systemowe. - Nazwa potoku. Przekazuje wartość
@{pipeline().Pipeline}. Ta zmienna systemowa umożliwia dostęp do odpowiedniej nazwy potoku. - Odbiornik. Przekazuje wartość
"@pipeline().parameters.receiver". Uzyskuje dostęp do parametrów potoku.
Ten kod tworzy nową zależność działania, która zależy od poprzedniego działania kopiowania.
Tworzenie uruchomienia potoku
Dodaj następujący kod do Main metody, która wyzwala uruchomienie potoku.
// Create a pipeline run
Console.WriteLine("Creating pipeline run...");
Dictionary<string, object> arguments = new Dictionary<string, object>
{
{ "sourceBlobContainer", inputBlobPath },
{ "sinkBlobContainer", outputBlobPath },
{ "receiver", emailReceiver }
};
CreateRunResponse runResponse = client.Pipelines.CreateRunWithHttpMessagesAsync(resourceGroup, dataFactoryName, pipelineName, arguments).Result.Body;
Console.WriteLine("Pipeline run ID: " + runResponse.RunId);
Klasa metody Main
Main Ostateczna metoda powinna wyglądać następująco.
// Authenticate and create a data factory management client
var context = new AuthenticationContext("https://login.windows.net/" + tenantID);
ClientCredential cc = new ClientCredential(applicationId, authenticationKey);
AuthenticationResult result = context.AcquireTokenAsync("https://management.azure.com/", cc).Result;
ServiceClientCredentials cred = new TokenCredentials(result.AccessToken);
var client = new DataFactoryManagementClient(cred) { SubscriptionId = subscriptionId };
Factory df = CreateOrUpdateDataFactory(client);
client.LinkedServices.CreateOrUpdate(resourceGroup, dataFactoryName, storageLinkedServiceName, StorageLinkedServiceDefinition(client));
client.Datasets.CreateOrUpdate(resourceGroup, dataFactoryName, blobSourceDatasetName, SourceBlobDatasetDefinition(client));
client.Datasets.CreateOrUpdate(resourceGroup, dataFactoryName, blobSinkDatasetName, SinkBlobDatasetDefinition(client));
client.Pipelines.CreateOrUpdate(resourceGroup, dataFactoryName, pipelineName, PipelineDefinition(client));
Console.WriteLine("Creating pipeline run...");
Dictionary<string, object> arguments = new Dictionary<string, object>
{
{ "sourceBlobContainer", inputBlobPath },
{ "sinkBlobContainer", outputBlobPath },
{ "receiver", emailReceiver }
};
CreateRunResponse runResponse = client.Pipelines.CreateRunWithHttpMessagesAsync(resourceGroup, dataFactoryName, pipelineName, arguments).Result.Body;
Console.WriteLine("Pipeline run ID: " + runResponse.RunId);
Skompiluj i uruchom program, aby wyzwolić uruchomienie potoku.
Monitorowanie uruchomienia potoku
Dodaj do metody
Mainnastępujący kod:// Monitor the pipeline run Console.WriteLine("Checking pipeline run status..."); PipelineRun pipelineRun; while (true) { pipelineRun = client.PipelineRuns.Get(resourceGroup, dataFactoryName, runResponse.RunId); Console.WriteLine("Status: " + pipelineRun.Status); if (pipelineRun.Status == "InProgress") System.Threading.Thread.Sleep(15000); else break; }Ten kod stale sprawdza stan przebiegu do momentu zakończenia kopiowania danych.
Dodaj następujący kod do
Mainmetody, która pobiera szczegóły przebiegu działania kopiowania, na przykład rozmiar odczyt/zapis danych:// Check the copy activity run details Console.WriteLine("Checking copy activity run details..."); List<ActivityRun> activityRuns = client.ActivityRuns.ListByPipelineRun( resourceGroup, dataFactoryName, runResponse.RunId, DateTime.UtcNow.AddMinutes(-10), DateTime.UtcNow.AddMinutes(10)).ToList(); if (pipelineRun.Status == "Succeeded") { Console.WriteLine(activityRuns.First().Output); //SaveToJson(SafeJsonConvert.SerializeObject(activityRuns.First().Output, client.SerializationSettings), "ActivityRunResult.json", folderForJsons); } else Console.WriteLine(activityRuns.First().Error); Console.WriteLine("\nPress any key to exit..."); Console.ReadKey();
Uruchamianie kodu
Skompiluj i uruchom aplikację, a następnie zweryfikuj wykonywanie potoku.
Aplikacja wyświetla postęp tworzenia fabryki danych, połączonej usługi, zestawów danych, potoku i uruchomienia potoku. Następnie sprawdza stan uruchomienia potoku. Poczekaj na wyświetlenie szczegółów uruchomienia działania kopiowania z rozmiarem odczytanych/zapisanych danych. Następnie użyj narzędzi, takich jak Eksplorator usługi Azure Storage, aby sprawdzić, czy obiekt blob został skopiowany do parametru outputBlobPath z parametru inputBlobPath, jak określono w zmiennych.
Dane wyjściowe powinny przypominać następujący przykład:
Creating data factory DFTutorialTest...
{
"location": "East US"
}
Creating linked service AzureStorageLinkedService...
{
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=***;AccountKey=***"
}
}
Creating dataset SourceStorageDataset...
{
"type": "AzureBlob",
"typeProperties": {
"folderPath": {
"type": "Expression",
"value": "@pipeline().parameters.sourceBlobContainer"
},
"fileName": "input.txt"
},
"linkedServiceName": {
"type": "LinkedServiceReference",
"referenceName": "AzureStorageLinkedService"
}
}
Creating dataset SinkStorageDataset...
{
"type": "AzureBlob",
"typeProperties": {
"folderPath": {
"type": "Expression",
"value": "@pipeline().parameters.sinkBlobContainer"
}
},
"linkedServiceName": {
"type": "LinkedServiceReference",
"referenceName": "AzureStorageLinkedService"
}
}
Creating pipeline Adfv2TutorialBranchCopy...
{
"properties": {
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink"
}
},
"inputs": [
{
"type": "DatasetReference",
"referenceName": "SourceStorageDataset"
}
],
"outputs": [
{
"type": "DatasetReference",
"referenceName": "SinkStorageDataset"
}
],
"name": "CopyBlobtoBlob"
},
{
"type": "WebActivity",
"typeProperties": {
"method": "POST",
"url": "https://xxxx.eastus.logic.azure.com:443/workflows/... ",
"body": {
"message": "@{activity('CopyBlobtoBlob').output.dataWritten}",
"dataFactoryName": "@{pipeline().DataFactory}",
"pipelineName": "@{pipeline().Pipeline}",
"receiver": "@pipeline().parameters.receiver"
}
},
"name": "SendSuccessEmailActivity",
"dependsOn": [
{
"activity": "CopyBlobtoBlob",
"dependencyConditions": [
"Succeeded"
]
}
]
},
{
"type": "WebActivity",
"typeProperties": {
"method": "POST",
"url": "https://xxx.eastus.logic.azure.com:443/workflows/... ",
"body": {
"message": "@{activity('CopyBlobtoBlob').error.message}",
"dataFactoryName": "@{pipeline().DataFactory}",
"pipelineName": "@{pipeline().Pipeline}",
"receiver": "@pipeline().parameters.receiver"
}
},
"name": "SendFailEmailActivity",
"dependsOn": [
{
"activity": "CopyBlobtoBlob",
"dependencyConditions": [
"Failed"
]
}
]
}
],
"parameters": {
"sourceBlobContainer": {
"type": "String"
},
"sinkBlobContainer": {
"type": "String"
},
"receiver": {
"type": "String"
}
}
}
}
Creating pipeline run...
Pipeline run ID: 00000000-0000-0000-0000-0000000000000
Checking pipeline run status...
Status: InProgress
Status: InProgress
Status: Succeeded
Checking copy activity run details...
{
"dataRead": 20,
"dataWritten": 20,
"copyDuration": 4,
"throughput": 0.01,
"errors": [],
"effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US)"
}
{}
Press any key to exit...
Powiązana zawartość
W tym samouczku wykonaliśmy następujące zadania:
- Tworzenie fabryki danych
- Tworzenie połączonej usługi Azure Storage
- Tworzenie zestawu danych obiektów blob platformy Azure
- Tworzenie potoku zawierającego działanie kopiowania i działanie internetowe
- Wysyłanie danych wyjściowych działań do kolejnych działań
- Używanie przekazywania parametrów i zmiennych systemowych
- Uruchamianie potoku
- Monitorowanie uruchomień działań i potoku
Teraz możesz przejść do sekcji Pojęcia, aby uzyskać więcej informacji na temat usługi Azure Data Factory.