Wydajność bazy danych Oracle na pojedynczych woluminach usługi Azure NetApp Files
W tym artykule omówiono następujące tematy dotyczące programu Oracle w chmurze. Te tematy mogą być szczególnie interesujące dla administratora bazy danych, architekta chmury lub architekta magazynu:
- W przypadku obciążenia przetwarzania transakcji online (OLTP) (głównie losowego we/wy) lub obciążenia przetwarzania analitycznego online (OLAP) (głównie sekwencyjne operacje we/wy), jak wygląda wydajność?
- Jaka jest różnica w wydajności między zwykłym klientem systemu Linux jądra NFS (kNFS) i własnym klientem systemu plików NFS firmy Oracle?
- Jeśli chodzi o przepustowość, czy wydajność pojedynczego woluminu usługi Azure NetApp Files wystarczy?
Ważne
Aby uzyskać poprawne i optymalne wdrożenie systemu plików Oracle dNFS, postępuj zgodnie z wytycznymi dotyczącymi stosowania poprawek opisanymi tutaj.
Środowisko i składniki testowania
Na poniższym diagramie przedstawiono środowisko używane do testowania. W celu zapewnienia spójności i prostoty podręczniki rozwiązania Ansible zostały użyte do wdrożenia wszystkich elementów łóżka testowego.
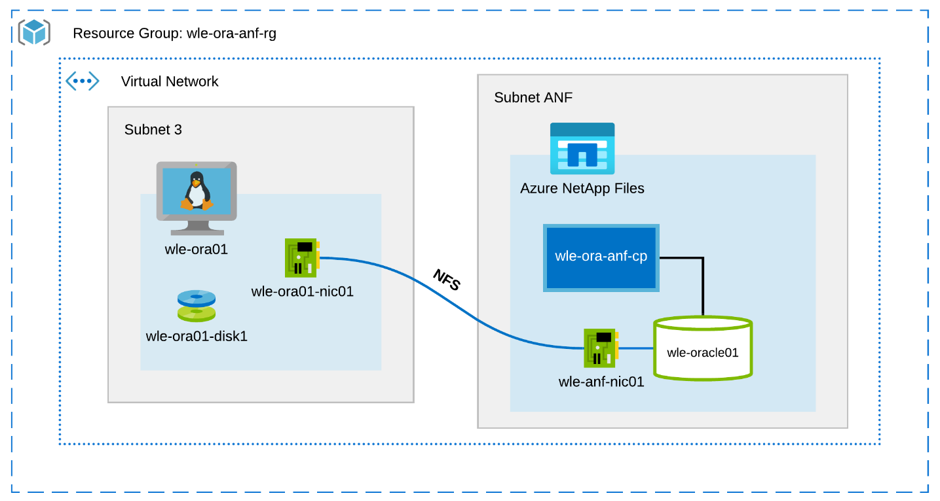
Konfiguracja maszyny wirtualnej
Testy używały następującej konfiguracji dla maszyny wirtualnej:
- System operacyjny:
RedHat Enterprise Linux 7.8 (wle-ora01) - Typy wystąpień:
Dwa modele były używane podczas testowania — D32s_v3 i D64s_v3 - Liczba interfejsów sieciowych:
Jedna (1) umieszczona w podsieci 3 - Dysków:
Pliki binarne i system operacyjny Oracle zostały umieszczone na jednym dysku w warstwie Premium
Konfiguracja usługi Azure NetApp Files
Testy używały następującej konfiguracji usługi Azure NetApp Files:
- Rozmiar puli pojemności:
Skonfigurowano różne rozmiary puli: 4 TiB, 8 TiB, 16 TiB, 32 TiB - Poziom usługi:
Ultra (128 MiB/s przepustowości na 1 TiB przydzielonej pojemności woluminu) - Woluminów:
Jeden i dwa testy zbiorcze zostały ocenione
Generator obciążeń
Testy używały obciążenia wygenerowanego przez sloB 2.5.4.2. SLOB (Silly Little Oracle Benchmark) to dobrze znany generator obciążeń w przestrzeni Oracle zaprojektowany pod kątem przeciążeń i testowania podsystemu we/wy z obciążeniem we/wy z buforem SGA.
SloB 2.5.4.2 nie obsługuje wtyczki bazy danych (PDB). W związku z tym dodano zmianę do setup.sh skryptów i runit.sh w celu dodania do niej obsługi plików PDB.
Zmienne SLOB używane w testach opisano w poniższych sekcjach.
Obciążenie 80% SELECT, 20% AKTUALIZACJA | Losowe we/wy — slob.conf zmienne
UPDATE_PCT=20
SCAN_PCT=0
RUN_TIME=600
WORK_LOOP=0
SCALE=75G
SCAN_TABLE_SZ=50G
WORK_UNIT=64
REDO_STRESS=LITE
LOAD_PARALLEL_DEGREE=12
Wybór obciążenia 100% | Sekwencyjne we/wy — slob.conf zmienne
UPDATE_PCT=0
SCAN_PCT=100
RUN_TIME=600
WORK_LOOP=0
SCALE=75G
SCAN_TABLE_SZ=50G
WORK_UNIT=64
REDO_STRESS=LITE
LOAD_PARALLEL_DEGREE=12
baza danych
Wersja Oracle używana do testów to Oracle Database Enterprise Edition 19.3.0.0.
Parametry Oracle są następujące:
-
sga_max_size: 4096 M -
sga_target: 4096 -
db_writer_processes: 12 -
awr_pdb_autoflush_enabled:prawdziwy -
filesystemio_options: SETALL -
log_buffer: 134217728
Plik PDB został utworzony dla bazy danych SLOB.
Na poniższym diagramie przedstawiono przestrzeń tabel o nazwie PERFIO o rozmiarze 600 GB (20 plików danych, 30 GB każdy) utworzonych do hostowania czterech schematów użytkowników SLOB. Każdy schemat użytkownika miał rozmiar 125 GB.
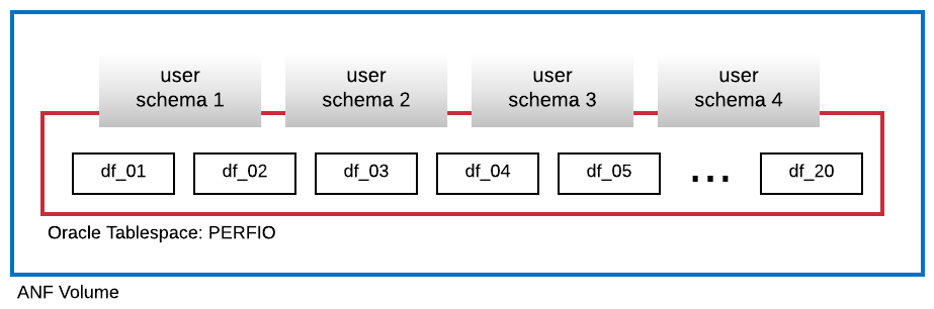
Performance metrics (Metryki wydajności)
Celem było raportowanie wydajności operacji we/wy zgodnie z doświadczeniem aplikacji. W związku z tym wszystkie diagramy w tym artykule używają metryk zgłaszanych przez bazę danych Oracle za pośrednictwem raportów automatycznego repozytorium obciążeń (AWR). Metryki używane na diagramach są następujące:
-
Średnie żądania we/wy na sekundę
Odpowiada sumie średnich żądań we/wy odczytu/s i średniej liczby żądań we/wy zapisu na sekundę z sekcji profilu obciążenia -
Średnia liczba mb/s we/wy
Odpowiada sumie średniej operacji we/wy odczytu MB/s i średniej operacji we/wy zapisu mb/s z sekcji profilu obciążenia -
Średnie opóźnienie odczytu
Odpowiada średniemu opóźnieniu zdarzenia oczekiwania Oracle "odczyt sekwencyjny pliku db" w mikrosekundach -
Liczba wątków/schematu
Odpowiada liczbie wątków SLOB na schemat użytkownika
Wyniki pomiaru wydajności
W tej sekcji opisano wyniki pomiaru wydajności.
Linux kNFS Client vs Oracle Direct NFS
Ten scenariusz był uruchamiany na maszynie wirtualnej platformy Azure Standard_D32s_v3 (Intel E5-2673 v4 @ 2,30 GHz). Obciążenie to 75% SELECT i 25% UPDATE, głównie losowe operacje we/wy, a bufor bazy danych osiąga około 7,5%.
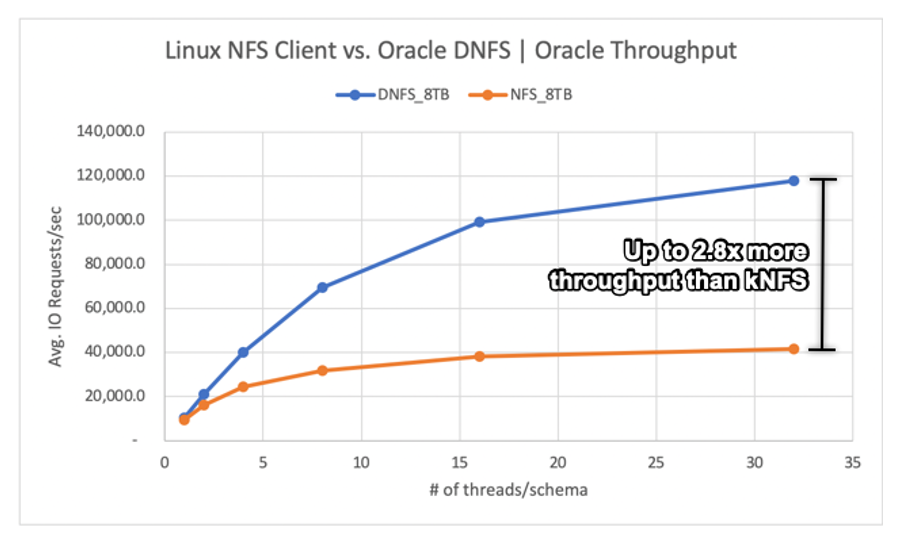
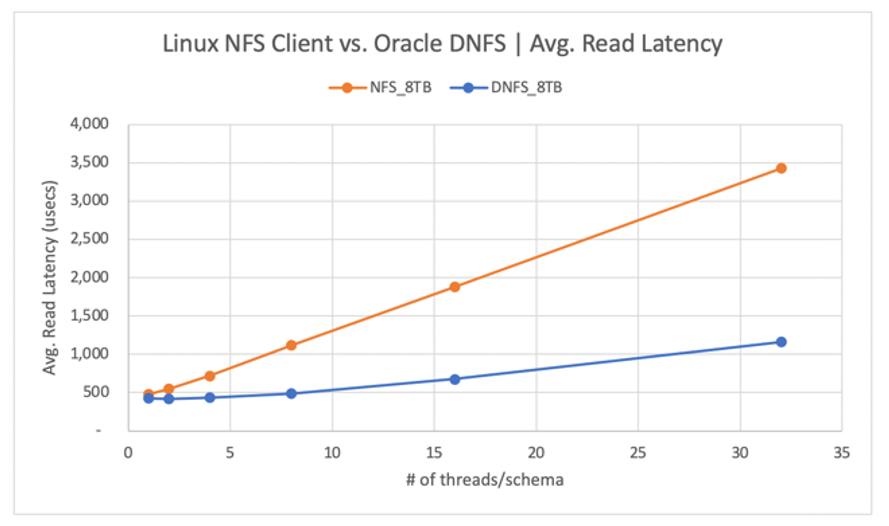
Jak pokazano na poniższym diagramie, klient Oracle DNFS dostarczał do 2,8x większą przepływność niż zwykły klient systemu plików kNFS systemu Linux:
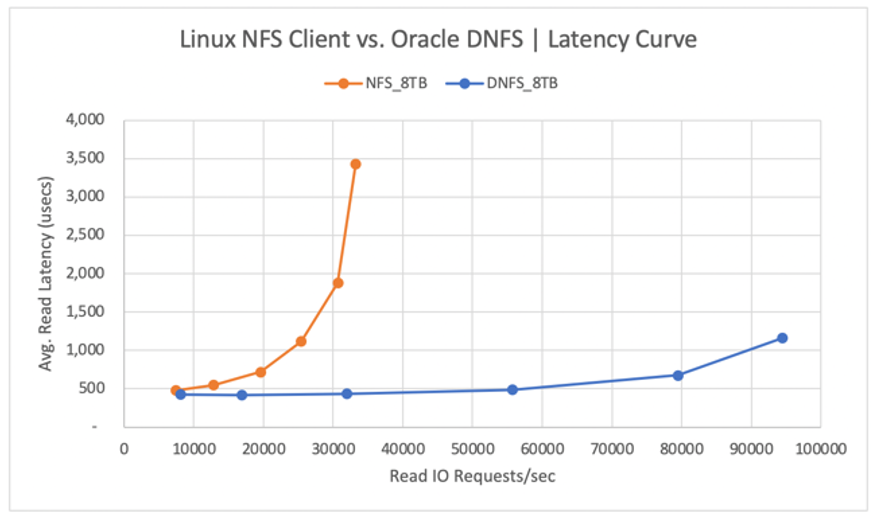
Na poniższym diagramie przedstawiono krzywą opóźnienia dla operacji odczytu. W tym kontekście wąskim gardłem dla klienta kNFS jest pojedyncze połączenie gniazda TCP systemu plików NFS ustanowione między klientem a serwerem NFS (wolumin usługi Azure NetApp Files).
Klient DNFS mógł wypchnąć więcej żądań we/wy na sekundę ze względu na możliwość tworzenia setek połączeń gniazd TCP, w związku z czym korzysta z równoległości. Zgodnie z opisem w konfiguracji usługi Azure NetApp Files każdy dodatkowy tiB przydzielonej pojemności umożliwia dodatkowe 128MiB/s przepustowości. System DNFS został zwieńczony na poziomie 1 GiB/s przepływności, co jest limitem nałożonym przez wybór pojemności 8 TiB. Biorąc pod uwagę większą pojemność, większa przepływność byłaby sterowana.
Przepływność jest tylko jedną z kwestii. Innym zagadnieniem jest opóźnienie, które ma podstawowy wpływ na środowisko użytkownika. Jak pokazano na poniższym diagramie, wzrost opóźnienia może być znacznie szybszy w przypadku systemu plików kNFS niż w przypadku systemu plików DNFS.
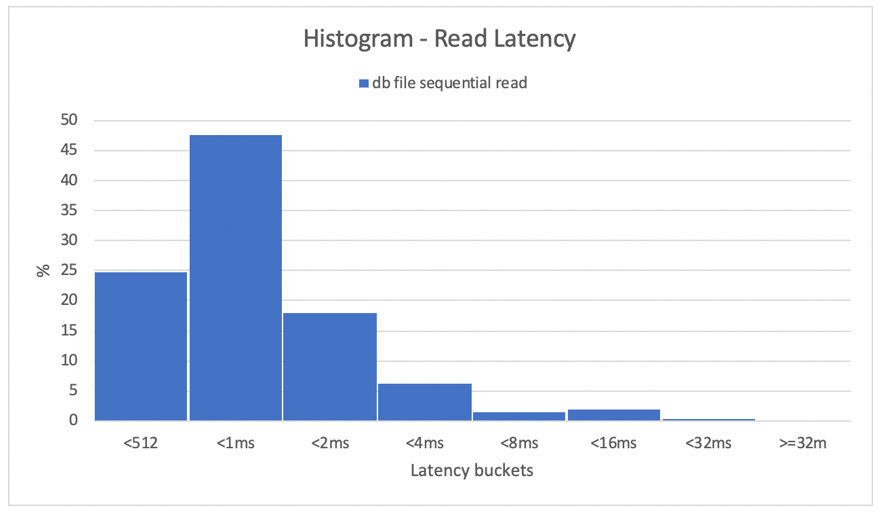
Histogramy zapewniają doskonały wgląd w opóźnienia bazy danych. Na poniższym diagramie przedstawiono pełny widok z perspektywy zarejestrowanego "odczytu sekwencyjnego pliku bazy danych", przy użyciu systemu DNFS w najwyższym punkcie danych współbieżności (32 wątki/schemat). Jak pokazano na poniższym diagramie, 47% wszystkich operacji odczytu zostało uhonorowanych między 512 mikrosekundami a 1000 mikrosekundami, podczas gdy 90% wszystkich operacji odczytu zostało obsłużonych z opóźnieniem poniżej 2 ms.
Podsumowując, jest jasne, że system DNFS jest koniecznością, jeśli chodzi o poprawę wydajności wystąpienia bazy danych Oracle w systemie plików NFS.
Limity wydajności pojedynczego woluminu
W tej sekcji opisano limity wydajności pojedynczego woluminu z losowymi we/wy i sekwencyjnymi we/wy.
Losowe we/wy
System DNFS może zużywać znacznie większą przepustowość niż to, co zapewnia limit wydajności usługi Azure NetApp Files o pojemności 8 TB. Zwiększając pojemność woluminu usługi Azure NetApp Files do 16 TiB, co jest natychmiastową zmianą, ilość przepustowości woluminu wzrosła z 1024 MiB/s do 2X do 2048 MiB/s.
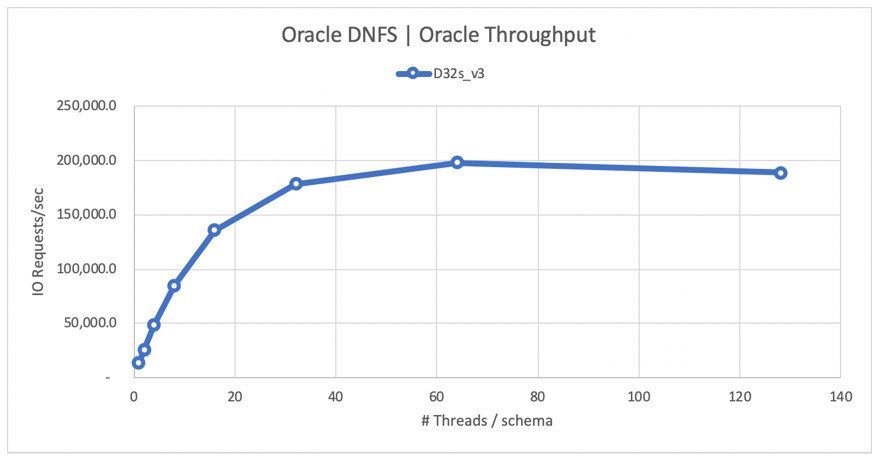
Na poniższym diagramie przedstawiono konfigurację 80% wybranego obciążenia i 20% aktualizacji oraz współczynnik trafień buforu bazy danych wynoszący 8%. SloB był w stanie obsycić pojedynczy wolumin do 200 000 żądań we/wy NFS na sekundę. Biorąc pod uwagę, że każda operacja ma rozmiar 8-KiB, system testowy był w stanie dostarczyć ok. 200 000 żądań we/wy na sekundę lub 1600 MiB/s.
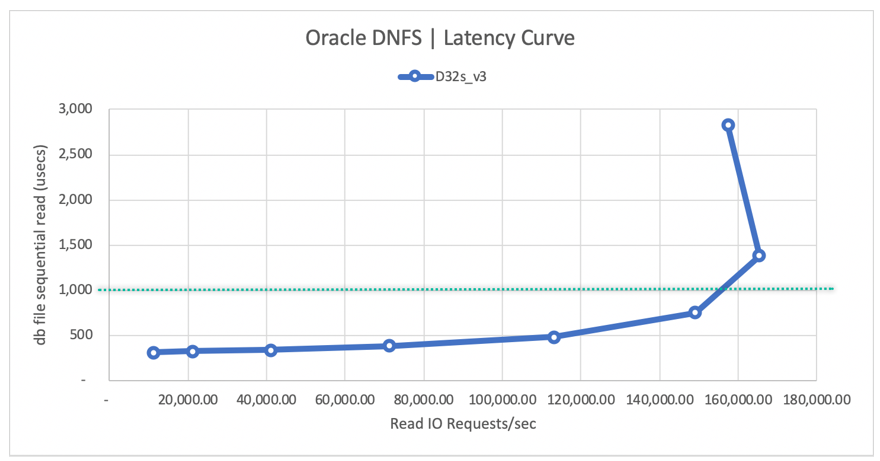
Na poniższym diagramie krzywej opóźnienia odczytu pokazano, że wraz ze wzrostem przepływności odczytu opóźnienie zwiększa się płynnie poniżej linii 1 ms i osiąga kolano krzywej przy ok. 165 000 średnich żądań we/wy odczytu na sekundę przy średnim opóźnieniu odczytu ok. 1,3 ms. Ta wartość jest niesamowitą wartością opóźnienia dla współczynnika we/wy, który jest nieosiągalny z niemal każdą inną technologią w chmurze platformy Azure.
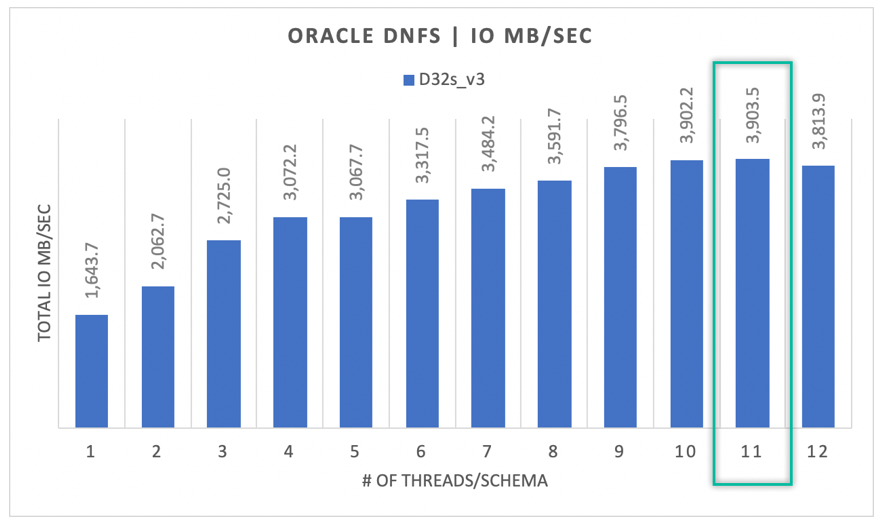
Sekwencyjne we/wy
Jak pokazano na poniższym diagramie, nie wszystkie operacje we/wy są losowe, biorąc pod uwagę kopię zapasową RMAN lub pełne skanowanie tabeli, na przykład jako obciążenia wymagające jak najwięcej przepustowości, jaką mogą uzyskać. Korzystając z tej samej konfiguracji, co opisano wcześniej, ale z rozmiarem woluminu do 32 TiB, na poniższym diagramie pokazano, że pojedyncze wystąpienie bazy danych Oracle DB może prowadzić do góry 3900 MB/s przepływności, bardzo blisko limitu wydajności woluminu usługi Azure NetApp Files wynoszącym 32 TB (128 MB/s * 32 = 4096 MB/s).
Podsumowując, usługa Azure NetApp Files ułatwia przejście baz danych Oracle do chmury. Zapewnia ona wydajność, gdy baza danych tego wymaga. W dowolnym momencie możesz dynamicznie i nie zakłócać zmiany limitu przydziału woluminu.