Zwiększanie odporności dzięki replikowaniu obszaru roboczego usługi Log Analytics między regionami (wersja zapoznawcza)
Replikowanie obszaru roboczego usługi Log Analytics między regionami zwiększa odporność, umożliwiając przejście do zreplikowanego obszaru roboczego i kontynuowanie operacji w przypadku awarii regionalnej. W tym artykule wyjaśniono, jak działa replikacja obszaru roboczego usługi Log Analytics, jak replikować obszar roboczy, jak przełączać się i z powrotem oraz jak zdecydować, kiedy przełączać się między replikowanymi obszarami roboczymi.
Oto film wideo, który zawiera krótkie omówienie sposobu działania replikacji obszaru roboczego usługi Log Analytics:
Ważne
Chociaż czasami używamy terminu tryb failover, na przykład w wywołaniu interfejsu API, tryb failover jest również często używany do opisywania procesu automatycznego. W związku z tym w tym artykule użyto terminu przełączania, aby podkreślić, że przejście do zreplikowanego obszaru roboczego jest akcją wyzwalaną ręcznie.
Jak działa replikacja obszaru roboczego usługi Log Analytics
Oryginalny obszar roboczy i region są określane jako podstawowy. Replikowany obszar roboczy i region alternatywny są określane jako pomocnicze.
Proces replikacji obszaru roboczego tworzy wystąpienie obszaru roboczego w regionie pomocniczym. Proces tworzy pomocniczy obszar roboczy z taką samą konfiguracją jak podstawowy obszar roboczy, a usługa Azure Monitor automatycznie aktualizuje pomocniczy obszar roboczy przy użyciu wszelkich przyszłych zmian w konfiguracji podstawowego obszaru roboczego.
Pomocniczy obszar roboczy jest obszarem roboczym "w tle" tylko do celów odporności. Nie widzisz pomocniczego obszaru roboczego w witrynie Azure Portal i nie możesz zarządzać nim bezpośrednio ani uzyskiwać do niego dostępu.
Po włączeniu replikacji obszaru roboczego usługa Azure Monitor wysyła nowe dzienniki pozyskane do podstawowego obszaru roboczego również do regionu pomocniczego. Dzienniki pozyskiwane do obszaru roboczego przed włączeniem replikacji obszaru roboczego nie są kopiowane.
Jeśli awaria ma wpływ na region podstawowy, możesz przełączyć i przekierować wszystkie żądania pozyskiwania i wysyłania zapytań do regionu pomocniczego. Gdy platforma Azure ograniczy awarię, a podstawowy obszar roboczy będzie w dobrej kondycji ponownie, możesz przełączyć się z powrotem do regionu podstawowego.
Po przełączeniu pomocniczy obszar roboczy staje się aktywny, a podstawowy staje się nieaktywny. Usługa Azure Monitor następnie pozyskuje nowe dane za pośrednictwem potoku pozyskiwania w regionie pomocniczym, a nie w regionie podstawowym. Po przełączeniu do regionu pomocniczego usługa Azure Monitor replikuje wszystkie dane pozyskiwane z regionu pomocniczego do regionu podstawowego. Proces jest asynchroniczny i nie ma wpływu na opóźnienie pozyskiwania.
Uwaga
Po przełączeniu się do regionu pomocniczego, jeśli region podstawowy nie może przetworzyć danych dziennika przychodzącego, usługa Azure Monitor buforuje dane w regionie pomocniczym przez maksymalnie 11 dni. W ciągu pierwszych czterech dni usługa Azure Monitor automatycznie reattempts w celu okresowej replikacji danych.

Ochrona przed utratą danych przesyłanych podczas awarii regionalnej
Usługa Azure Monitor ma kilka mechanizmów zapewniających, że dane przesyłane nie zostaną utracone w przypadku awarii w regionie podstawowym.
Usługa Azure Monitor chroni dane, które docierają do punktu końcowego pozyskiwania danych w regionie podstawowym, gdy potok regionu podstawowego jest niedostępny do przetwarzania danych. Gdy potok stanie się dostępny, nadal przetwarza dane podczas przesyłania, a usługa Azure Monitor pozyskuje i replikuje dane do regionu pomocniczego.
Jeśli punkt końcowy pozyskiwania danych w regionie podstawowym nie jest dostępny, agent usługi Azure Monitor regularnie ponawia próby wysyłania danych dziennika do punktu końcowego. Punkt końcowy pozyskiwania danych w regionie pomocniczym zaczyna odbierać dane od agentów kilka minut po wyzwoleniu przełączania.
Jeśli napiszesz własnego klienta w celu wysyłania danych dziennika do obszaru roboczego usługi Log Analytics, upewnij się, że klient obsługuje nieudane żądania pozyskiwania.
Uwagi dotyczące wdrażania
Replikacja obszarów roboczych usługi Log Analytics połączonych z dedykowanym klastrem nie jest obecnie obsługiwana.
Operacja przeczyszczania, która usuwa rekordy z obszaru roboczego, usuwa odpowiednie rekordy zarówno z podstawowych, jak i pomocniczych obszarów roboczych. Jeśli jedno z wystąpień obszaru roboczego nie jest dostępne, operacja przeczyszczania zakończy się niepowodzeniem.
Usługa Azure Monitor obsługuje wykonywanie zapytań dotyczących nieaktywnego regionu. Alerty oparte na zapytaniach nadal działają, gdy przełączasz się między regionami, chyba że usługa Alerty w aktywnym regionie nie działa prawidłowo lub reguły alertów nie są dostępne. Replikacja reguł alertów między regionami nie jest obecnie obsługiwana.
Po włączeniu replikacji dla obszarów roboczych, które wchodzą w interakcję z usługą Sentinel, może upłynąć do 12 dni, aby w pełni replikować dane listy obserwowanych i analizy zagrożeń do pomocniczego obszaru roboczego.
Nie można zainicjować operacji zarządzania obszarem roboczym podczas przełączania, w tym:
- Zmienianie przechowywania obszaru roboczego, warstwy cenowej, dziennego limitu itd.
- Zmienianie ustawień sieci
- Zmienianie schematu za pomocą nowych dzienników niestandardowych lub łączenie dzienników platformy z nowych dostawców zasobów, takich jak wysyłanie dzienników diagnostycznych z nowego typu zasobu
Funkcja określania wartości docelowej rozwiązania starszego agenta usługi Log Analytics nie jest obsługiwana podczas przełączania. Podczas przełączania dane rozwiązania są pozyskiwane ze wszystkich agentów.
Proces trybu failover aktualizuje rekordy systemu nazw domen (DNS) w celu przekierowania wszystkich żądań pozyskiwania do regionu pomocniczego na potrzeby przetwarzania. Niektórzy klienci HTTP mają "lepkie połączenia" i mogą potrwać dłużej, aby pobrać zaktualizowany system DNS DNS. Podczas przełączania ci klienci mogą próbować pozyskiwać dzienniki za pośrednictwem regionu podstawowego przez jakiś czas. Dzienniki mogą być pozyskiwane do podstawowego obszaru roboczego przy użyciu różnych klientów, w tym starszego agenta usługi Log Analytics, agenta usługi Azure Monitor, kodu (przy użyciu interfejsu API pozyskiwania dzienników lub starszego interfejsu API zbierania danych HTTP) i innych usług, takich jak Microsoft Sentinel.
Te funkcje nie są obecnie obsługiwane lub tylko częściowo obsługiwane:
Funkcja Pomoc techniczna Plany tabeli pomocniczej Nieobsługiwane. Usługa Azure Monitor nie replikuje danych w tabelach z planem dziennika pomocniczego do pomocniczego obszaru roboczego. W związku z tym te dane nie są chronione przed utratą danych w przypadku awarii regionalnej i nie są dostępne po przełączeniu się do pomocniczego obszaru roboczego. Zadania wyszukiwania, przywracanie Częściowo obsługiwane — operacje wyszukiwania i przywracania tworzą tabele i wypełniają je wynikami wyszukiwania lub przywróconymi danymi. Po włączeniu replikacji obszaru roboczego nowe tabele utworzone dla tych operacji są replikowane do pomocniczego obszaru roboczego. Tabele wypełnione przed włączeniem replikacji nie są replikowane. Jeśli te operacje są w toku po przełączeniu, wynik jest nieoczekiwany. Może zakończyć się pomyślnie, ale nie jest replikowany lub może zakończyć się niepowodzeniem, w zależności od kondycji obszaru roboczego i dokładnego czasu. Usługa Application Insights w obszarach roboczych usługi Log Analytics Nieobsługiwane Szczegółowe informacje o maszynie wirtualnej Nieobsługiwane Szczegółowe informacje o kontenerze Nieobsługiwane Łącza prywatne Nieobsługiwane podczas pracy w trybie failover
Obsługiwane regiony
Replikacja obszaru roboczego jest obecnie obsługiwana dla obszarów roboczych w ograniczonym zestawie regionów zorganizowanych według grup regionów (grup geograficznie sąsiednich regionów). Po włączeniu replikacji wybierz lokalizację pomocniczą z listy obsługiwanych regionów w tej samej grupie regionów co lokalizacja podstawowa obszaru roboczego. Na przykład obszar roboczy w regionie Europa Zachodnia można replikować w regionie Europa Północna, ale nie w regionie Zachodnie stany USA 2, ponieważ te regiony znajdują się w różnych grupach regionów.
Te grupy regionów i regiony są obecnie obsługiwane:
| Grupa regionów | Regiony | Uwagi | ||
|---|---|---|---|---|
| Ameryka Północna | Wschodnie stany USA | Wschodnie stany USA nie mogą replikować do lub z regionów Wschodnie stany USA 2 i Południowo-środkowe stany USA. | ||
| Wschodnie stany USA 2 | Wschodnie stany USA 2 nie mogą być replikowane do lub z regionów Wschodnie stany USA i Południowo-środkowe stany USA. | |||
| Zachodnie stany USA | ||||
| Zachodnie stany USA 2 | ||||
| Środkowe stany USA | ||||
| South Central US | Południowo-środkowe stany USA nie mogą replikować do lub z regionów Wschodnie stany USA i Wschodnie stany USA 2. | |||
| Kanada Środkowa | ||||
| Europa | West Europe | |||
| Europa Północna | ||||
| Południowe Zjednoczone Królestwo | ||||
| Zachodnie Zjednoczone Królestwo | ||||
| Niemcy Środkowo-Zachodnie | ||||
| Francja Środkowa |
Wymagania dotyczące rezydencji danych
Różni klienci mają różne wymagania dotyczące rezydencji danych, dlatego ważne jest, aby kontrolować miejsce przechowywania danych. Usługa Azure Monitor przetwarza i przechowuje dzienniki w wybranym regionie podstawowym i pomocniczym. Aby uzyskać więcej informacji, zobacz Obsługiwane regiony.
Obsługa usługi Microsoft Sentinel i innych usług
Różne usługi i funkcje korzystające z obszarów roboczych usługi Log Analytics są zgodne z replikacją obszaru roboczego i przełączaniem. Te usługi i funkcje nadal działają po przełączeniu się do pomocniczego obszaru roboczego.
Na przykład problemy z siecią regionalną, które powodują opóźnienie pozyskiwania dzienników, mogą mieć wpływ na klientów usługi Microsoft Sentinel. Klienci korzystający z replikowanych obszarów roboczych mogą przełączyć się do regionu pomocniczego, aby kontynuować pracę z obszarem roboczym usługi Log Analytics i usługą Sentinel. Jeśli jednak problem z siecią ma wpływ na kondycję usługi Sentinel, przełączenie do innego regionu nie spowoduje rozwiązania problemu.
Niektóre środowiska usługi Azure Monitor, w tym usługi Application Insights i VM Insights, są obecnie tylko częściowo zgodne z replikacją obszaru roboczego i przełączaniem. Aby uzyskać pełną listę, zobacz Zagadnienia dotyczące wdrażania.
Model cen
Po włączeniu replikacji obszaru roboczego opłaty są naliczane za replikację wszystkich danych pozyskanych do obszaru roboczego.
Ważne
Jeśli wysyłasz dane do obszaru roboczego przy użyciu agenta usługi Azure Monitor, interfejsu API pozyskiwania dzienników, usługi Azure Event Hubs lub innych źródeł danych korzystających z reguł zbierania danych, upewnij się, że skojarzysz reguły zbierania danych z punktem końcowym zbierania danych obszaru roboczego. To skojarzenie gwarantuje, że pozyskane dane są replikowane do pomocniczego obszaru roboczego. Jeśli nie skojarzysz reguł zbierania danych z punktem końcowym zbierania danych obszaru roboczego, nadal są naliczane opłaty za wszystkie pozyskane dane do obszaru roboczego, mimo że dane nie są replikowane.
Wymagane uprawnienia
| Akcja | Wymagane uprawnienia |
|---|---|
| Włączanie replikacji obszaru roboczego |
Microsoft.OperationalInsights/workspaces/writei Microsoft.Insights/dataCollectionEndpoints/write uprawnienia, zgodnie z wbudowaną rolą Współautor monitorowania, na przykład |
| Przełączanie i przełączanie z powrotem (wyzwalanie trybu failover i powrót po awarii) |
Microsoft.OperationalInsights/locations/workspaces/failover, , Microsoft.Insights/dataCollectionEndpoints/triggerFailover/actionMicrosoft.OperationalInsights/workspaces/failbacki Microsoft.Insights/dataCollectionEndpoints/triggerFailback/action uprawnienia udostępniane przez wbudowaną rolę Współautor monitorowania, na przykład |
| Sprawdzanie stanu obszaru roboczego |
Microsoft.OperationalInsights/workspaces/read uprawnienia do obszaru roboczego usługi Log Analytics udostępnione przez wbudowaną rolę Współautor monitorowania, na przykład |
Włączanie i wyłączanie replikacji obszaru roboczego
Replikację obszaru roboczego można włączyć i wyłączyć za pomocą polecenia REST. Polecenie wyzwala długotrwałą operację, co oznacza, że zastosowanie nowych ustawień może potrwać kilka minut. Po włączeniu replikacji może upłynąć do jednej godziny, zanim wszystkie tabele (typy danych) rozpoczną replikację, a niektóre typy danych mogą rozpocząć replikację przed innymi. Zmiany wprowadzone w schematach tabel po włączeniu replikacji obszaru roboczego — na przykład nowych niestandardowych tabel dzienników lub tworzonych pól niestandardowych lub dzienników diagnostycznych skonfigurowanych dla nowych typów zasobów — może upłynąć do jednej godziny, aby rozpocząć replikację.
Włączanie replikacji obszaru roboczego
Aby włączyć replikację w obszarze roboczym usługi Log Analytics, użyj następującego PUT polecenia:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}
Gdzie:
-
<subscription_id>: identyfikator subskrypcji powiązany z obszarem roboczym. -
<resourcegroup_name>: grupa zasobów zawierająca zasób obszaru roboczego usługi Log Analytics. -
<workspace_name>: nazwa obszaru roboczego. -
<primary_region>: region podstawowy dla obszaru roboczego usługi Log Analytics. -
<secondary_region>: region, w którym usługa Azure Monitor tworzy pomocniczy obszar roboczy.
Aby uzyskać obsługiwane location wartości, zobacz Obsługiwane regiony.
Polecenie PUT jest długotrwałą operacją, która może zająć trochę czasu. Pomyślne wywołanie zwraca 200 kod stanu. Stan aprowizacji żądania można śledzić zgodnie z opisem w temacie Sprawdzanie stanu aprowizacji żądania.
Sprawdzanie stanu aprowizacji żądania
Aby sprawdzić stan aprowizacji żądania, uruchom następujące GET polecenie:
GET
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
Gdzie:
-
<subscription_id>: identyfikator subskrypcji powiązany z obszarem roboczym. -
<resourcegroup_name>: grupa zasobów zawierająca zasób obszaru roboczego usługi Log Analytics. -
<workspace_name>: nazwa obszaru roboczego usługi Log Analytics.
GET Użyj polecenia , aby sprawdzić, czy stan aprowizacji obszaru roboczego zmienia się z na Succeeded, a region pomocniczy jest ustawiony zgodnie z Updating oczekiwaniami.
Uwaga
Po włączeniu replikacji dla obszarów roboczych, które wchodzą w interakcję z usługą Sentinel, może upłynąć do 12 dni, aby w pełni replikować dane listy obserwowanych i analizy zagrożeń do pomocniczego obszaru roboczego.
Kojarzenie reguł zbierania danych z punktem końcowym zbierania danych obszaru roboczego
Agent usługi Azure Monitor, interfejs API pozyskiwania dzienników i usługa Azure Event Hubs zbierają dane i wysyłają je do określonego miejsca docelowego na podstawie sposobu konfigurowania reguł zbierania danych (DCR).
Jeśli masz reguły zbierania danych, które wysyłają dane do podstawowego obszaru roboczego, musisz skojarzyć reguły z punktem końcowym zbierania danych systemu (DCE), który usługa Azure Monitor tworzy podczas włączania replikacji obszaru roboczego. Nazwa punktu końcowego zbierania danych obszaru roboczego jest identyczna z identyfikatorem obszaru roboczego. Tylko reguły zbierania danych skojarzone z punktem końcowym zbierania danych obszaru roboczego umożliwiają replikację i przełączanie. To zachowanie umożliwia określenie zestawu strumieni dzienników do replikacji, co pomaga kontrolować koszty replikacji.
Aby replikować dane zbierane przy użyciu reguł zbierania danych, skojarz reguły zbierania danych z punktem końcowym zbierania danych obszaru roboczego:
W witrynie Azure Portal wybierz pozycję Reguły zbierania danych.
Na ekranie Reguły zbierania danych wybierz regułę zbierania danych, która wysyła dane do podstawowego obszaru roboczego usługi Log Analytics.
Na stronie Przegląd reguły zbierania danych wybierz pozycję Konfiguruj kontroler domeny i wybierz punkt końcowy zbierania danych obszaru roboczego z dostępnej listy:
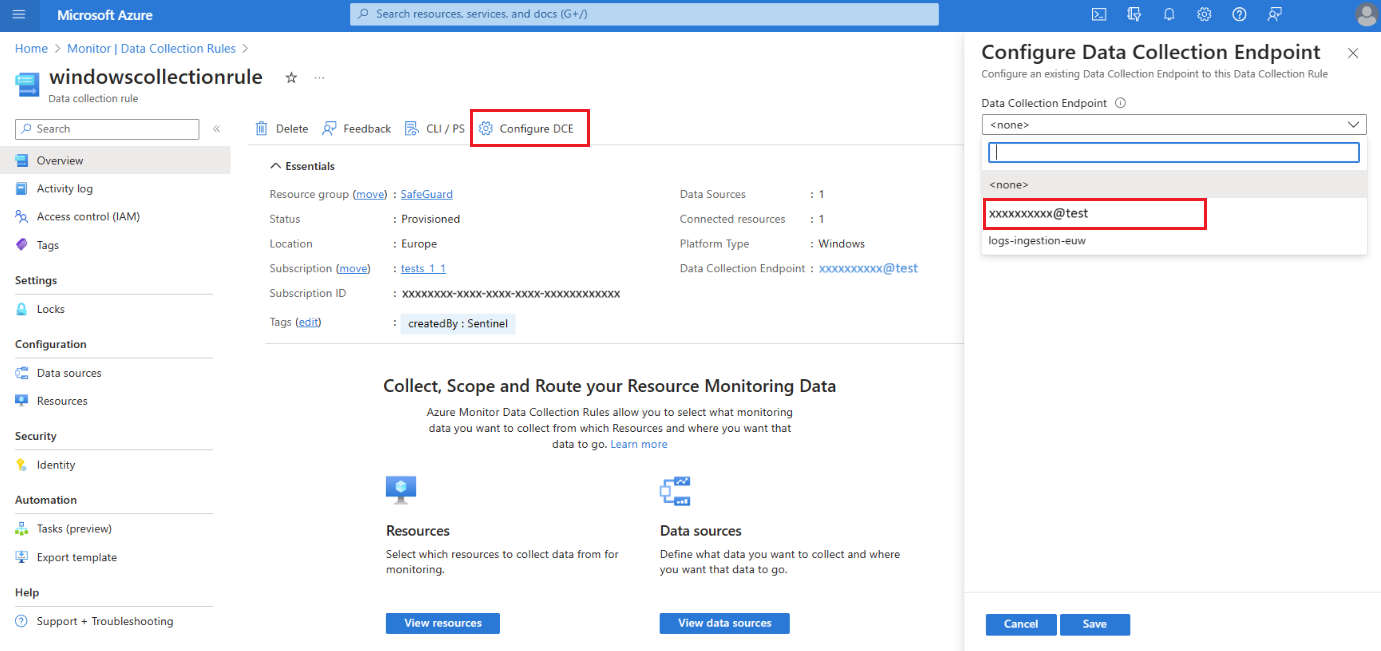 Aby uzyskać szczegółowe informacje na temat systemu DCE, sprawdź właściwości obiektu obszaru roboczego.
Aby uzyskać szczegółowe informacje na temat systemu DCE, sprawdź właściwości obiektu obszaru roboczego.

Ważne
Reguły zbierania danych połączone z punktem końcowym zbierania danych obszaru roboczego mogą być przeznaczone tylko dla tego konkretnego obszaru roboczego. Reguły zbierania danych nie mogą być przeznaczone dla innych miejsc docelowych, takich jak inne obszary robocze lub konta usługi Azure Storage.
Wyłączanie replikacji obszaru roboczego
Aby wyłączyć replikację dla obszaru roboczego, użyj następującego PUT polecenia:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": false
}
},
"location": "<primary_region>"
}
Gdzie:
-
<subscription_id>: identyfikator subskrypcji powiązany z obszarem roboczym. -
<resourcegroup_name>: grupa zasobów zawierająca zasób obszaru roboczego. -
<workspace_name>: nazwa obszaru roboczego. -
<primary_region>: region podstawowy dla obszaru roboczego.
Polecenie PUT jest długotrwałą operacją, która może zająć trochę czasu. Pomyślne wywołanie zwraca 200 kod stanu. Stan aprowizacji żądania można śledzić zgodnie z opisem w temacie Sprawdzanie stanu aprowizacji żądania.
Monitorowanie obszaru roboczego i kondycji usługi
Opóźnienia pozyskiwania lub błędy zapytań to przykłady problemów, które mogą być często obsługiwane przez przełączenie w tryb failover do regionu pomocniczego. Takie problemy można wykryć przy użyciu powiadomień usługi Service Health i zapytań dziennika.
Powiadomienia usługi Service Health są przydatne w przypadku problemów związanych z usługą. Aby zidentyfikować problemy wpływające na określony obszar roboczy (i prawdopodobnie nie całą usługę), możesz użyć innych miar:
- Tworzenie alertów na podstawie kondycji zasobów obszaru roboczego
- Ustawianie własnych progów dla metryk kondycji obszaru roboczego
- Utwórz własne zapytania monitorowania, aby służyć jako niestandardowe wskaźniki kondycji dla obszaru roboczego, zgodnie z opisem w temacie Monitorowanie wydajności obszaru roboczego przy użyciu zapytań, w celu:
- Mierzenie opóźnienia pozyskiwania na tabelę
- Określanie, czy źródłem opóźnienia są agenci kolekcji, czy potok pozyskiwania
- Monitorowanie anomalii woluminu pozyskiwania na tabelę i zasób
- Monitorowanie współczynnika powodzenia zapytań na tabelę, użytkownika lub zasób
- Tworzenie alertów na podstawie zapytań
Uwaga
Możesz również użyć zapytań dziennika do monitorowania pomocniczego obszaru roboczego, ale pamiętaj, że replikacja dzienników odbywa się w operacjach wsadowych. Zmierzone opóźnienie może się wahać i nie wskazuje żadnego problemu z kondycją pomocniczego obszaru roboczego. Aby uzyskać więcej informacji, zobacz Inspekcja nieaktywnego obszaru roboczego.
Przełączanie do pomocniczego obszaru roboczego
Podczas przełączania większość operacji działa tak samo jak w przypadku korzystania z podstawowego obszaru roboczego i regionu. Jednak niektóre operacje mają nieco inne zachowanie lub są blokowane. Aby uzyskać więcej informacji, zobacz Zagadnienia dotyczące wdrażania.
Kiedy należy przełączyć się?
Decydujesz, kiedy przełączyć się do pomocniczego obszaru roboczego i przełączyć się z powrotem do podstawowego obszaru roboczego w oparciu o ciągłą wydajność i monitorowanie kondycji oraz standardy i wymagania systemowe.
Istnieje kilka kwestii, które należy wziąć pod uwagę w planie przełączania, zgodnie z opisem w poniższych podsekcjach.
Typ problemu i zakres
Proces przełączania kieruje żądania pozyskiwania i wysyłania zapytań do regionu pomocniczego, co zwykle pomija wszelkie uszkodzone składniki powodujące opóźnienia lub awarie w regionie podstawowym. W związku z tym przełączanie nie może pomóc, jeśli:
- Występuje problem między regionami związany z bazowym zasobem. Jeśli na przykład te same typy zasobów kończą się niepowodzeniem zarówno w regionach podstawowym, jak i pomocniczym.
- Występuje problem związany z zarządzaniem obszarem roboczym, takim jak zmiana przechowywania obszaru roboczego. Operacje zarządzania obszarami roboczymi są zawsze obsługiwane w regionie podstawowym. Podczas przełączania operacje zarządzania obszarami roboczymi są blokowane.
Czas trwania problemu
Przełączanie nie jest natychmiastowe. Proces przekierowywania żądań opiera się na aktualizacjach DNS, które niektórzy klienci odbierają w ciągu kilku minut, podczas gdy inni mogą zająć więcej czasu. Dlatego warto zrozumieć, czy problem można rozwiązać w ciągu kilku minut. Jeśli zaobserwowany problem jest spójny lub ciągły, nie czekaj, aby przełączyć się. Oto kilka przykładów:
Pozyskiwanie: problemy z potokiem pozyskiwania w regionie podstawowym mogą mieć wpływ na replikację danych do pomocniczego obszaru roboczego. Podczas przełączania dzienniki są zamiast tego wysyłane do potoku pozyskiwania w regionie pomocniczym.
Zapytanie: jeśli zapytania w podstawowym obszarze roboczym kończą się niepowodzeniem lub przekroczeniem limitu czasu, alerty wyszukiwania w dziennikach mogą mieć wpływ. W tym scenariuszu przełącz się do pomocniczego obszaru roboczego, aby upewnić się, że wszystkie alerty są wyzwalane poprawnie.
Pomocnicze dane obszaru roboczego
Dzienniki pozyskane do podstawowego obszaru roboczego przed włączeniem replikacji nie są kopiowane do pomocniczego obszaru roboczego. Jeśli włączono replikację obszaru roboczego trzy godziny temu i teraz przełączysz się do pomocniczego obszaru roboczego, zapytania mogą zwracać dane tylko z ostatnich trzech godzin.
Zanim przełączysz regiony podczas przełączania, pomocniczy obszar roboczy musi zawierać przydatną ilość dzienników. Zalecamy oczekiwanie co najmniej tydzień po włączeniu replikacji przed wyzwoleniem przełączania. Siedem dni pozwala na udostępnienie wystarczającej ilości danych w regionie pomocniczym.
Przełączanie wyzwalacza
Przed przełączeniem upewnij się, że operacja replikacji obszaru roboczego zakończyła się pomyślnie. Przełączanie kończy się powodzeniem tylko wtedy, gdy pomocniczy obszar roboczy jest poprawnie skonfigurowany.
Aby przełączyć się do pomocniczego obszaru roboczego, użyj następującego POST polecenia:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/locations/<secondary_region>/workspaces/<workspace_name>/failover?api-version=2023-01-01-preview
Gdzie:
-
<subscription_id>: identyfikator subskrypcji powiązany z obszarem roboczym. -
<resourcegroup_name>: grupa zasobów zawierająca zasób obszaru roboczego. -
<secondary_region>: region, do który ma się przełączyć podczas przełączania. -
<workspace_name>: nazwa obszaru roboczego, na który ma się przełączyć podczas przełączania.
Polecenie POST jest długotrwałą operacją, która może zająć trochę czasu. Pomyślne wywołanie zwraca 202 kod stanu. Stan aprowizacji żądania można śledzić zgodnie z opisem w temacie Sprawdzanie stanu aprowizacji żądania.
Przełącz się z powrotem do podstawowego obszaru roboczego
Proces przełączania zwrotnego anuluje przekierowanie zapytań i żądania pozyskiwania dzienników do pomocniczego obszaru roboczego. Po przełączeniu z powrotem usługa Azure Monitor wraca do routingu zapytań i rejestrowania żądań pozyskiwania danych do podstawowego obszaru roboczego.
Po przełączeniu do regionu pomocniczego usługa Azure Monitor replikuje dzienniki z pomocniczego obszaru roboczego do podstawowego obszaru roboczego. Jeśli awaria ma wpływ na proces pozyskiwania dzienników w regionie podstawowym, ukończenie pozyskiwania zreplikowanych dzienników do podstawowego obszaru roboczego może zająć trochę czasu.
Kiedy należy przełączyć się z powrotem?
Istnieje kilka kwestii, które należy wziąć pod uwagę w planie przełączania zwrotnego zgodnie z opisem w poniższych podsekcjach.
Stan replikacji dziennika
Przed przełączeniem z powrotem sprawdź, czy usługa Azure Monitor zakończyła replikowanie wszystkich dzienników pozyskanych podczas przełączania do regionu podstawowego. Jeśli przełączysz się z powrotem przed replikacją wszystkich dzienników do podstawowego obszaru roboczego, zapytania mogą zwracać częściowe wyniki do momentu zakończenia pozyskiwania dzienników.
Możesz wykonać zapytanie dotyczące podstawowego obszaru roboczego w witrynie Azure Portal dla nieaktywnego regionu, zgodnie z opisem w temacie Inspekcja nieaktywnego obszaru roboczego.
Kondycja podstawowego obszaru roboczego
Istnieją dwa ważne elementy kondycji, które należy sprawdzić w ramach przygotowania do przełączenia do podstawowego obszaru roboczego:
- Upewnij się, że nie ma zaległych powiadomień usługi Service Health dla podstawowego obszaru roboczego i regionu.
- Upewnij się, że podstawowy obszar roboczy pozyskuje dzienniki i przetwarza zapytania zgodnie z oczekiwaniami.
Aby zapoznać się z przykładami wykonywania zapytań względem podstawowego obszaru roboczego, gdy pomocniczy obszar roboczy jest aktywny, i pomijać przekierowywanie żądań do pomocniczego obszaru roboczego, zobacz Inspekcja nieaktywnego obszaru roboczego.
Przełączanie zwrotne wyzwalacza
Przed przełączeniem potwierdź kondycję podstawowego obszaru roboczego i zakończ replikację dzienników.
Proces przełączania zwrotnego aktualizuje rekordy DNS. Po zaktualizowaniu rekordów DNS może upłynąć trochę czasu, aby wszyscy klienci otrzymywali zaktualizowane ustawienia DNS i wznawiali routing do podstawowego obszaru roboczego.
Aby wrócić do podstawowego obszaru roboczego, użyj następującego POST polecenia:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>/failback?api-version=2023-01-01-preview
Gdzie:
-
<subscription_id>: identyfikator subskrypcji powiązany z obszarem roboczym. -
<resourcegroup_name>: grupa zasobów zawierająca zasób obszaru roboczego. -
<workspace_name>: nazwa obszaru roboczego, na który ma się przełączyć podczas przełączania zwrotnego.
Polecenie POST jest długotrwałą operacją, która może zająć trochę czasu. Pomyślne wywołanie zwraca 202 kod stanu. Stan aprowizacji żądania można śledzić zgodnie z opisem w temacie Sprawdzanie stanu aprowizacji żądania.
Inspekcja nieaktywnego obszaru roboczego
Domyślnie aktywny region obszaru roboczego to region, w którym tworzysz obszar roboczy, a nieaktywny region to region pomocniczy, w którym usługa Azure Monitor tworzy zreplikowany obszar roboczy.
Po wyzwoleniu trybu failover to przełączenia — region pomocniczy jest aktywowany, a region podstawowy staje się nieaktywny. Mówimy, że jest to nieaktywne, ponieważ nie jest to bezpośredni element docelowy pozyskiwania dzienników i żądań zapytań.
Warto wykonać zapytanie dotyczące nieaktywnego regionu przed przełączeniem się między regionami, aby sprawdzić, czy obszar roboczy w nieaktywnym regionie zawiera oczekiwane dzienniki.
Wykonywanie zapytań względem nieaktywnego regionu
Aby wykonywać zapytania dotyczące danych dziennika w nieaktywnym regionie, użyj następującego polecenia GET:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=<query>×pan=<timespan-in-ISO8601-format>&overrideWorkspaceRegion=<primary|secondary>
Aby na przykład uruchomić proste zapytanie, takie jak Perf | count w ciągu ostatniego dnia w regionie pomocniczym, użyj:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=Perf%20|%20count×pan=P1D&overrideWorkspaceRegion=secondary
Możesz potwierdzić, że usługa Azure Monitor uruchamia zapytanie w zamierzonym regionie, sprawdzając te pola w LAQueryLogs tabeli, które są tworzone podczas włączania inspekcji zapytań w obszarze roboczym usługi Log Analytics:
-
isWorkspaceInFailover: wskazuje, czy obszar roboczy był w trybie przełączania podczas wykonywania zapytania. Typ danych to Wartość logiczna (Prawda, Fałsz). -
workspaceRegion: region obszaru roboczego objętego zapytaniem. Typ danych to Ciąg.
Monitorowanie wydajności obszaru roboczego przy użyciu zapytań
Zalecamy użycie zapytań w tej sekcji w celu utworzenia reguł alertów, które powiadamiają o możliwych problemach z kondycją lub wydajnością obszaru roboczego. Jednak decyzja o przełączeniu wymaga starannego rozważenia i nie powinna być wykonywana automatycznie.
W regule zapytania można zdefiniować warunek przełączania się do pomocniczego obszaru roboczego po określonej liczbie naruszeń. Aby uzyskać więcej informacji, zobacz Tworzenie lub edytowanie reguły alertu przeszukiwania dzienników.
Dwa znaczące pomiary wydajności obszaru roboczego obejmują opóźnienie pozyskiwania i ilość pozyskiwania. W poniższych sekcjach opisano te opcje monitorowania.
Monitorowanie całkowitego opóźnienia pozyskiwania
Opóźnienie pozyskiwania mierzy czas potrzebny na pozyskanie dzienników do obszaru roboczego. Pomiar czasu rozpoczyna się po wystąpieniu początkowego zarejestrowanego zdarzenia i kończy się, gdy dziennik jest przechowywany w obszarze roboczym. Całkowite opóźnienie pozyskiwania składa się z dwóch części:
- Opóźnienie agenta: czas wymagany przez agenta do zgłaszania zdarzenia.
- Opóźnienie potoku pozyskiwania (zaplecza): czas wymagany do przetworzenia dzienników przez potok pozyskiwania i zapis ich w obszarze roboczym.
Różne typy danych mają różne opóźnienia pozyskiwania. Możesz mierzyć pozyskiwanie dla każdego typu danych oddzielnie lub utworzyć ogólne zapytanie dla wszystkich typów oraz bardziej szczegółowe zapytanie dla określonych typów, które mają większe znaczenie. Sugerujemy zmierzenie 90. percentyla opóźnienia pozyskiwania, co jest bardziej wrażliwe na zmianę niż średnia lub 50. percentyl (mediana).
W poniższych sekcjach pokazano, jak używać zapytań do sprawdzania opóźnienia pozyskiwania dla obszaru roboczego.
Ocena opóźnienia pozyskiwania według planu bazowego określonych tabel
Zacznij od określenia opóźnienia linii bazowej określonych tabel w ciągu kilku dni.
To przykładowe zapytanie tworzy wykres 90. percentyla opóźnienia pozyskiwania w tabeli Wydajności:
// Assess the ingestion latency baseline for a specific data type
Perf
| where TimeGenerated > ago(3d)
| project TimeGenerated,
IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize LatencyIngestion90Percentile=percentile(IngestionDurationSeconds, 90) by bin(TimeGenerated, 1h)
| render timechart
Po uruchomieniu zapytania przejrzyj wyniki i renderowany wykres, aby określić oczekiwane opóźnienie dla tej tabeli.
Monitorowanie i alert dotyczący bieżącego opóźnienia pozyskiwania
Po ustanowieniu opóźnienia pozyskiwania punktu odniesienia dla określonej tabeli utwórz regułę alertu wyszukiwania dzienników dla tabeli na podstawie zmian opóźnienia w krótkim czasie.
To zapytanie oblicza opóźnienie pozyskiwania w ciągu ostatnich 20 minut:
// Track the recent ingestion latency (in seconds) of a specific table
Perf
| where TimeGenerated > ago(20m)
| extend IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize Ingestion90Percent_seconds=percentile(IngestionDurationSeconds, 90)
Ponieważ można oczekiwać pewnych wahań, utwórz warunek reguły alertu, aby sprawdzić, czy zapytanie zwraca wartość znacznie większą niż punkt odniesienia.
Określanie źródła opóźnienia pozyskiwania
Gdy zauważysz, że łączne opóźnienie pozyskiwania rośnie, możesz użyć zapytań, aby określić, czy źródłem opóźnienia są agenci, czy potok pozyskiwania.
To zapytanie generuje wykres 90. percentyla opóźnienia agentów i potoku, oddzielnie:
// Assess agent and pipeline (backend) latency
Perf
| where TimeGenerated > ago(1h)
| extend AgentLatencySeconds = (_TimeReceived-TimeGenerated)/1s,
PipelineLatencySeconds=(ingestion_time()-_TimeReceived)/1s
| summarize percentile(AgentLatencySeconds,90), percentile(PipelineLatencySeconds,90) by bin(TimeGenerated,5m)
| render columnchart
Uwaga
Chociaż wykres wyświetla 90. percentyl danych jako skumulowane kolumny, suma danych na dwóch wykresach nie jest równa całkowitemu pozyskiwaniu 90. percentylu.
Monitorowanie woluminu pozyskiwania
Pomiary ilości pozyskiwania mogą pomóc w zidentyfikowaniu nieoczekiwanych zmian w woluminie pozyskiwania danych specyficznych dla tabeli lub całkowitej dla obszaru roboczego. Pomiary woluminów zapytań mogą pomóc w zidentyfikowaniu problemów z wydajnością podczas pozyskiwania dzienników. Oto kilka przydatnych pomiarów woluminów:
- Łączna ilość pozyskiwania na tabelę
- Wolumin ciągłego pozyskiwania (wstrzymanie)
- Anomalie pozyskiwania — skoki i spadki ilości pozyskiwania
W poniższych sekcjach pokazano, jak używać zapytań do sprawdzania woluminu pozyskiwania dla obszaru roboczego.
Monitorowanie całkowitego woluminu pozyskiwania na tabelę
Możesz zdefiniować zapytanie do monitorowania woluminu pozyskiwania na tabelę w obszarze roboczym. Zapytanie może zawierać alert sprawdzający nieoczekiwane zmiany w woluminach całkowitych lub specyficznych dla tabeli.
To zapytanie oblicza łączną ilość pozyskiwania danych w ciągu ostatniej godziny na tabelę w megabajtach na sekundę (MB):
// Calculate total ingestion volume over the past hour per table
Usage
| where TimeGenerated > ago(1h)
| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated,1h), DataType
Sprawdzanie wstrzymania pozyskiwania
Jeśli pozyskujesz dzienniki za pośrednictwem agentów, możesz użyć pulsu agenta do wykrywania łączności. Nadal puls może ujawnić zatrzymanie pozyskiwania dzienników w obszarze roboczym. Gdy dane zapytania ujawniają wstrzymanie pozyskiwania, można zdefiniować warunek wyzwalający żądaną odpowiedź.
Następujące zapytanie sprawdza puls agenta w celu wykrycia problemów z łącznością:
// Count agent heartbeats in the last ten minutes
Heartbeat
| where TimeGenerated>ago(10m)
| count
Monitorowanie anomalii pozyskiwania
Możesz zidentyfikować skoki i spadki w danych woluminu pozyskiwania obszaru roboczego na różne sposoby. Funkcja series_decompose_anomalies() umożliwia wyodrębnianie anomalii z woluminów pozyskiwania monitora w obszarze roboczym lub tworzenie własnego narzędzia do wykrywania anomalii w celu obsługi unikatowych scenariuszy obszaru roboczego.
Identyfikowanie anomalii przy użyciu series_decompose_anomalies
Funkcja series_decompose_anomalies() identyfikuje anomalie w serii wartości danych. To zapytanie oblicza liczbę godzinową pozyskiwania każdej tabeli w obszarze roboczym usługi Log Analytics i używa ich series_decompose_anomalies() do identyfikowania anomalii:
// Calculate hourly ingestion volume per table and identify anomalies
Usage
| where TimeGenerated > ago(24h)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| summarize
Timestamp=make_list(TimeGenerated),
IngestionVolumeMB=make_list(IngestionVolumeMB)
by DataType
| extend series_decompose_anomalies(IngestionVolumeMB)
| mv-expand
Timestamp,
IngestionVolumeMB,
series_decompose_anomalies_IngestionVolumeMB_ad_flag,
series_decompose_anomalies_IngestionVolumeMB_ad_score,
series_decompose_anomalies_IngestionVolumeMB_baseline
| where series_decompose_anomalies_IngestionVolumeMB_ad_flag != 0
Aby uzyskać więcej informacji na temat sposobu wykrywania series_decompose_anomalies() anomalii w danych dziennika, zobacz Wykrywanie i analizowanie anomalii przy użyciu funkcji uczenia maszynowego KQL w usłudze Azure Monitor.
Tworzenie własnego detektora anomalii
Możesz utworzyć niestandardowy detektor anomalii, aby obsługiwać wymagania scenariusza konfiguracji obszaru roboczego. Ta sekcja zawiera przykład, aby zademonstrować proces.
Następujące zapytanie oblicza:
- Oczekiwany wolumin pozyskiwania: na godzinę, według tabeli (na podstawie mediany median, ale można dostosować logikę)
- Rzeczywisty wolumin pozyskiwania: na godzinę według tabeli
Aby odfiltrować nieistotne różnice między oczekiwanym i rzeczywistym woluminem pozyskiwania, zapytanie stosuje dwa filtry:
- Współczynnik zmian: ponad 150% lub poniżej 66% oczekiwanego woluminu na tabelę
- Ilość zmian: wskazuje, czy wolumin zwiększony lub zmniejszony wynosi ponad 0,1% miesięcznej woluminu tej tabeli
// Calculate expected vs actual hourly ingestion per table
let TimeRange=24h;
let MonthlyIngestionByType=
Usage
| where TimeGenerated > ago(30d)
| summarize MonthlyIngestionMB=sum(Quantity) by DataType;
// Calculate the expected ingestion volume by median of hourly medians
let ExpectedIngestionVolumeByType=
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionMedian=percentile(Quantity, 50) by bin(TimeGenerated, 1h), DataType
| summarize ExpectedIngestionVolumeMB=percentile(IngestionMedian, 50) by DataType;
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| join kind=inner (ExpectedIngestionVolumeByType) on DataType
| extend GapVolumeMB = round(IngestionVolumeMB-ExpectedIngestionVolumeMB,2)
| where GapVolumeMB != 0
| extend Trend=iff(GapVolumeMB > 0, "Up", "Down")
| extend IngestedVsExpectedAsPercent = round(IngestionVolumeMB * 100 / ExpectedIngestionVolumeMB, 2)
| join kind=inner (MonthlyIngestionByType) on DataType
| extend GapAsPercentOfMonthlyIngestion = round(abs(GapVolumeMB) * 100 / MonthlyIngestionMB, 2)
| project-away DataType1, DataType2
// Determine whether the spike/deep is substantial: over 150% or under 66% of the expected volume for this data type
| where IngestedVsExpectedAsPercent > 150 or IngestedVsExpectedAsPercent < 66
// Determine whether the gap volume is significant: over 0.1% of the total monthly ingestion volume to this workspace
| where GapAsPercentOfMonthlyIngestion > 0.1
| project
Timestamp=format_datetime(todatetime(TimeGenerated), 'yyyy-MM-dd HH:mm:ss'),
Trend,
IngestionVolumeMB,
ExpectedIngestionVolumeMB,
IngestedVsExpectedAsPercent,
GapAsPercentOfMonthlyIngestion
Monitorowanie powodzenia i niepowodzenia zapytania
Każde zapytanie zwraca kod odpowiedzi, który wskazuje powodzenie lub niepowodzenie. Gdy zapytanie zakończy się niepowodzeniem, odpowiedź zawiera również typy błędów. Wysoki wzrost błędów może wskazywać na problem z dostępnością obszaru roboczego lub wydajnością usługi.
To zapytanie zlicza liczbę zapytań, które zwróciły kod błędu serwera:
// Count query errors
LAQueryLogs
| where ResponseCode>=500 and ResponseCode<600
| count