Opcje konfiguracji: Usługa Azure Monitor Application Insights dla języka Java
W tym artykule pokazano, jak skonfigurować usługę Azure Monitor Application Insights dla języka Java.
Aby uzyskać więcej informacji, zobacz Wprowadzenie do biblioteki OpenTelemetry , która zawiera przykładowe aplikacje.
Parametry połączenia i nazwa roli
Parametry połączenia i nazwa roli są najbardziej typowymi ustawieniami, które należy rozpocząć:
{
"connectionString": "...",
"role": {
"name": "my cloud role name"
}
}
Parametry połączenia są wymagane. Nazwa roli jest ważna w dowolnym momencie wysyłania danych z różnych aplikacji do tego samego zasobu usługi Application Insights.
Więcej informacji i opcji konfiguracji znajduje się w poniższych sekcjach.
Konfiguracja JSON
Konfiguracja domyślna
Domyślnie środowisko Java 3 usługi Application Insights oczekuje, że plik konfiguracji będzie mieć nazwę applicationinsights.json i znajduje się w tym samym katalogu co applicationinsights-agent-3.6.2.jar.
Konfiguracje alternatywne
Niestandardowy plik konfiguracji
Możesz określić niestandardowy plik konfiguracji za pomocą polecenia
- APPLICATIONINSIGHTS_CONFIGURATION_FILE zmiennej środowiskowej lub
- właściwość systemowa applicationinsights.configuration.file
Jeśli podasz ścieżkę względną, zostanie rozpoznana względem katalogu, w którym znajduje się applicationinsights-agent-3.6.0.jar.
Konfiguracja JSON
Zamiast używać pliku konfiguracji, można ustawić całą konfigurację JSON za pomocą polecenia:
- zmiennej środowiskowej APPLICATIONINSIGHTS_CONFIGURATION_CONTENT lub
- właściwość systemowa applicationinsights.configuration.content
Connection string
Parametry połączenia są wymagane. Parametry połączenia można znaleźć w zasobie usługi Application Insights.
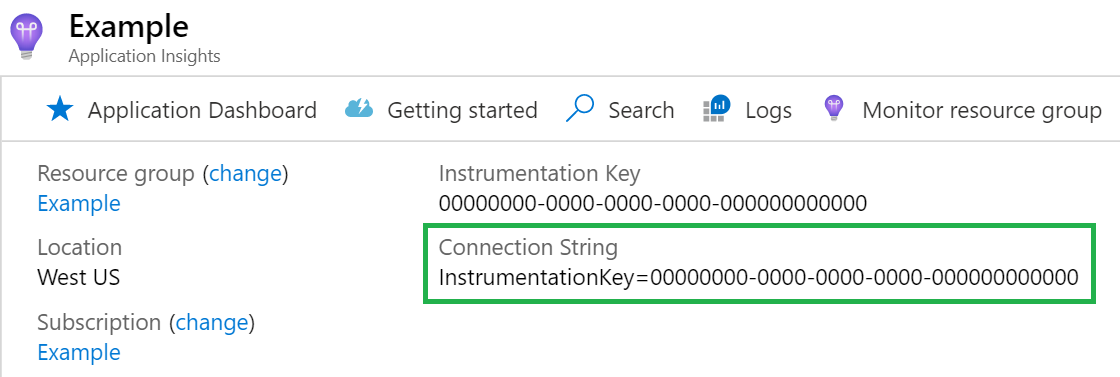
{
"connectionString": "..."
}
Można również ustawić parametry połączenia przy użyciu zmiennej środowiskowej APPLICATIONINSIGHTS_CONNECTION_STRING. Następnie pierwszeństwo przed parametry połączenia określonym w konfiguracji JSON.
Możesz też ustawić parametry połączenia za pomocą właściwości applicationinsights.connection.stringsystemu Java . Ma również pierwszeństwo przed parametry połączenia określonym w konfiguracji JSON.
Można również ustawić parametry połączenia, określając plik do załadowania parametry połączenia.
Jeśli określisz ścieżkę względną, zostanie rozpoznana względem katalogu, w którym applicationinsights-agent-3.6.2.jar się znajduje.
{
"connectionString": "${file:connection-string-file.txt}"
}
Plik powinien zawierać tylko parametry połączenia i nic innego.
Nie ustawia parametry połączenia wyłącza agenta Java.
Jeśli masz wiele aplikacji wdrożonych na tej samej maszynie wirtualnej Java (JVM) i chcesz, aby wysyłały dane telemetryczne do różnych parametry połączenia, zobacz Przesłonięcia parametrów połączenia (wersja zapoznawcza).
Nazwa roli chmury
Nazwa roli chmury jest używana do oznaczania składnika na mapie aplikacji.
Jeśli chcesz ustawić nazwę roli w chmurze:
{
"role": {
"name": "my cloud role name"
}
}
Jeśli nazwa roli w chmurze nie jest ustawiona, nazwa zasobu usługi Application Insights jest używana do oznaczania składnika na mapie aplikacji.
Nazwę roli chmury można również ustawić przy użyciu zmiennej środowiskowej APPLICATIONINSIGHTS_ROLE_NAME. Następnie ma pierwszeństwo przed nazwą roli chmury określoną w konfiguracji JSON.
Możesz też ustawić nazwę roli chmury przy użyciu właściwości applicationinsights.role.namesystemu Java . Ma również pierwszeństwo przed nazwą roli chmury określoną w konfiguracji JSON.
Jeśli masz wiele aplikacji wdrożonych w tej samej maszynie JVM i chcesz, aby wysyłały dane telemetryczne do różnych nazw ról w chmurze, zobacz Przesłonięcia nazw ról w chmurze (wersja zapoznawcza).
Wystąpienie roli w chmurze
Wystąpienie roli w chmurze domyślnie określa nazwę maszyny.
Jeśli chcesz ustawić wystąpienie roli w chmurze na coś innego niż nazwa maszyny:
{
"role": {
"name": "my cloud role name",
"instance": "my cloud role instance"
}
}
Możesz również ustawić wystąpienie roli w chmurze przy użyciu zmiennej środowiskowej APPLICATIONINSIGHTS_ROLE_INSTANCE. Następnie ma pierwszeństwo przed wystąpieniem roli chmury określonym w konfiguracji JSON.
Możesz też ustawić wystąpienie roli w chmurze przy użyciu właściwości applicationinsights.role.instancesystemu Java .
Ma również pierwszeństwo przed wystąpieniem roli chmury określonym w konfiguracji JSON.
Próbkowanie
Uwaga
Próbkowanie może być doskonałym sposobem na zmniejszenie kosztów usługi Application Insights. Upewnij się, że skonfigurować konfigurację próbkowania odpowiednio dla danego przypadku użycia.
Próbkowanie jest oparte na żądaniu, co oznacza, że jeśli żądanie zostanie przechwycone (próbkowane), więc są to jego zależności, dzienniki i wyjątki.
Próbkowanie jest również oparte na identyfikatorze śledzenia, aby zapewnić spójne decyzje dotyczące próbkowania w różnych usługach.
Próbkowanie dotyczy tylko dzienników wewnątrz żądania. Dzienniki, które nie znajdują się wewnątrz żądania (na przykład dzienniki uruchamiania), są zawsze zbierane domyślnie. Jeśli chcesz próbkować te dzienniki, możesz użyć przesłonięć próbkowania.
Próbkowanie z ograniczoną szybkością
Począwszy od wersji 3.4.0, próbkowanie z ograniczoną szybkością jest dostępne i jest teraz domyślne.
Jeśli nie skonfigurowano próbkowania, wartość domyślna to teraz próbkowanie z ograniczoną szybkością skonfigurowane do przechwytywania maksymalnie (około) pięciu żądań na sekundę, a także wszystkich zależności i dzienników dotyczących tych żądań.
Ta konfiguracja zastępuje poprzednią wartość domyślną, która polegała na przechwyceniu wszystkich żądań. Jeśli nadal chcesz przechwycić wszystkie żądania, użyj próbkowania o stałym procentzie i ustaw wartość procentową próbkowania na 100.
Uwaga
Próbkowanie ograniczone do szybkości jest przybliżone, ponieważ wewnętrznie musi dostosować "stały" procent próbkowania w czasie, aby emitować dokładne liczby elementów dla każdego rekordu telemetrii. Wewnętrznie próbkowanie z ograniczoną szybkością jest dostosowywane do szybkiego dostosowywania (0,1 sekundy) do nowych obciążeń aplikacji. Z tego powodu nie powinno być widoczne przekroczenie skonfigurowanej szybkości o wiele lub przez bardzo długi czas.
W tym przykładzie pokazano, jak ustawić próbkowanie w celu przechwycenia co najwyżej jednego żądania (w przybliżeniu) na sekundę:
{
"sampling": {
"requestsPerSecond": 1.0
}
}
Może requestsPerSecond to być liczba dziesiętna, dzięki czemu można ją skonfigurować tak, aby przechwycić mniej niż jedno żądanie na sekundę, jeśli chcesz. Na przykład wartość 0.5 średnich przechwytuje co najwyżej jedno żądanie co 2 sekundy.
Możesz również ustawić wartość procentową próbkowania przy użyciu zmiennej środowiskowej APPLICATIONINSIGHTS_SAMPLING_REQUESTS_PER_SECOND. Następnie ma pierwszeństwo przed limitem szybkości określonym w konfiguracji JSON.
Próbkowanie o stałej wartości procentowej
W tym przykładzie pokazano, jak ustawić próbkowanie w celu przechwycenia około jednej trzeciej wszystkich żądań:
{
"sampling": {
"percentage": 33.333
}
}
Możesz również ustawić wartość procentową próbkowania przy użyciu zmiennej środowiskowej APPLICATIONINSIGHTS_SAMPLING_PERCENTAGE. Następnie ma pierwszeństwo przed wartością procentową próbkowania określoną w konfiguracji JSON.
Uwaga
Dla wartości procentowej próbkowania wybierz wartość procentową zbliżoną do 100/N, gdzie N jest liczbą całkowitą. Obecnie próbkowanie nie obsługuje innych wartości.
Przesłonięcia próbkowania
Przesłonięcia próbkowania umożliwiają zastąpienie domyślnej wartości procentowej próbkowania. Można na przykład:
- Ustaw wartość procentową próbkowania na 0 lub niewielką wartość dla hałaśliwych testów kondycji.
- Ustaw wartość procentową próbkowania na 0 lub niewielką wartość dla hałaśliwych wywołań zależności.
- Ustaw wartość procentową próbkowania na 100 dla ważnego typu żądania. Możesz na przykład użyć
/loginpolecenia , nawet jeśli masz domyślne próbkowanie skonfigurowane do czegoś niższego.
Aby uzyskać więcej informacji, zobacz dokumentację Przesłonięcia próbkowania.
Metryki rozszerzeń zarządzania Java
Jeśli chcesz zebrać inne metryki rozszerzeń zarządzania Java (JMX):
{
"jmxMetrics": [
{
"name": "JVM uptime (millis)",
"objectName": "java.lang:type=Runtime",
"attribute": "Uptime"
},
{
"name": "MetaSpace Used",
"objectName": "java.lang:type=MemoryPool,name=Metaspace",
"attribute": "Usage.used"
}
]
}
W poprzednim przykładzie konfiguracji:
nameto nazwa metryki przypisana do tej metryki JMX (może to być dowolny element).objectNameto nazwaJMX MBeanobiektu, który chcesz zebrać. Symbol wieloznaczny gwiazdka (*) jest obsługiwany.attributeto nazwa atrybutuJMX MBeanwewnątrz obiektu, który chcesz zebrać.
Obsługiwane są wartości metryki liczbowe i logiczne JMX. Metryki logiczne JMX są mapowane na 0 wartość false i 1 true.
Aby uzyskać więcej informacji, zobacz dokumentację metryk JMX.
Wymiary niestandardowe
Jeśli chcesz dodać wymiary niestandardowe do wszystkich danych telemetrycznych:
{
"customDimensions": {
"mytag": "my value",
"anothertag": "${ANOTHER_VALUE}"
}
}
Możesz użyć ${...} polecenia , aby odczytać wartość z określonej zmiennej środowiskowej podczas uruchamiania.
Uwaga
Począwszy od wersji 3.0.2, jeśli dodasz wymiar niestandardowy o nazwie service.version, wartość jest przechowywana w application_Version kolumnie w tabeli Dzienniki usługi Application Insights zamiast jako wymiar niestandardowy.
Atrybut dziedziczony (wersja zapoznawcza)
Począwszy od wersji 3.2.0, można programowo ustawić niestandardowy wymiar na telemetrii żądania. Zapewnia dziedziczenie według zależności i telemetrii dziennika. Wszystkie są przechwytywane w kontekście tego żądania.
{
"preview": {
"inheritedAttributes": [
{
"key": "mycustomer",
"type": "string"
}
]
}
}
Następnie na początku każdego żądania wywołaj następujące wywołanie:
Span.current().setAttribute("mycustomer", "xyz");
Zobacz również: Dodawanie właściwości niestandardowej do zakresu.
Przesłonięcia parametrów połączenia (wersja zapoznawcza)
Ta funkcja jest dostępna w wersji zapoznawczej, począwszy od wersji 3.4.0.
Przesłonięcia parametrów połączenia umożliwiają zastąpienie domyślnej parametry połączenia. Można na przykład:
- Ustaw jeden parametry połączenia dla jednego prefiksu ścieżki
/myapp1HTTP. - Ustaw inny parametry połączenia dla innego prefiksu ścieżki
/myapp2/HTTP .
{
"preview": {
"connectionStringOverrides": [
{
"httpPathPrefix": "/myapp1",
"connectionString": "..."
},
{
"httpPathPrefix": "/myapp2",
"connectionString": "..."
}
]
}
}
Przesłonięcia nazw ról w chmurze (wersja zapoznawcza)
Ta funkcja jest dostępna w wersji zapoznawczej, począwszy od wersji 3.3.0.
Przesłonięcia nazw ról w chmurze umożliwiają zastąpienie domyślnej nazwy roli chmury. Można na przykład:
- Ustaw jedną nazwę roli w chmurze dla jednego prefiksu ścieżki
/myapp1HTTP. - Ustaw inną nazwę roli w chmurze dla innego prefiksu ścieżki
/myapp2/HTTP.
{
"preview": {
"roleNameOverrides": [
{
"httpPathPrefix": "/myapp1",
"roleName": "Role A"
},
{
"httpPathPrefix": "/myapp2",
"roleName": "Role B"
}
]
}
}
Parametry połączenia skonfigurowane w czasie wykonywania
Począwszy od wersji 3.4.8, jeśli potrzebujesz możliwości skonfigurowania parametry połączenia w czasie wykonywania, dodaj tę właściwość do konfiguracji json:
{
"connectionStringConfiguredAtRuntime": true
}
Dodaj applicationinsights-core do aplikacji:
<dependency>
<groupId>com.microsoft.azure</groupId>
<artifactId>applicationinsights-core</artifactId>
<version></version>
</dependency>
Użyj metody statycznej configure(String) w klasie com.microsoft.applicationinsights.connectionstring.ConnectionString.
Uwaga
Wszelkie dane telemetryczne przechwycone przed skonfigurowaniem parametry połączenia zostaną porzucone, dlatego najlepiej skonfigurować je tak szybko, jak to możliwe podczas uruchamiania aplikacji.
Zależności Autokolekt InProc (wersja zapoznawcza)
Począwszy od wersji 3.2.0, jeśli chcesz przechwycić zależności kontrolera "InProc", użyj następującej konfiguracji:
{
"preview": {
"captureControllerSpans": true
}
}
Moduł ładujący zestawu SDK przeglądarki (wersja zapoznawcza)
Ta funkcja automatycznie wprowadza moduł ładujący zestawu SDK przeglądarki do stron HTML aplikacji, w tym konfigurowanie odpowiednich parametrów połączenia.
Na przykład gdy aplikacja Java zwraca odpowiedź, na przykład:
<!DOCTYPE html>
<html lang="en">
<head>
<title>Title</title>
</head>
<body>
</body>
</html>
Spowoduje to automatyczne zmodyfikowanie w celu zwrócenia:
<!DOCTYPE html>
<html lang="en">
<head>
<script type="text/javascript">
!function(v,y,T){var S=v.location,k="script"
<!-- Removed for brevity -->
connectionString: "YOUR_CONNECTION_STRING"
<!-- Removed for brevity --> }});
</script>
<title>Title</title>
</head>
<body>
</body>
</html>
Skrypt ma na celu ułatwienie klientom śledzenia danych użytkownika internetowego i wysyłanie danych telemetrycznych po stronie serwera z powrotem do witryny Azure Portal użytkowników. Szczegóły można znaleźć w artykule ApplicationInsights-JS.
Jeśli chcesz włączyć tę funkcję, dodaj poniższą opcję konfiguracji:
{
"preview": {
"browserSdkLoader": {
"enabled": true
}
}
}
Procesory telemetryczne (wersja zapoznawcza)
Za pomocą procesorów telemetrii można skonfigurować reguły stosowane do telemetrii żądań, zależności i śledzenia danych telemetrycznych. Można na przykład:
- Maskuj poufne dane.
- Warunkowe dodawanie wymiarów niestandardowych.
- Zaktualizuj nazwę zakresu, która jest używana do agregowania podobnych danych telemetrycznych w witrynie Azure Portal.
- Porzucanie określonych atrybutów zakresu w celu kontrolowania kosztów pozyskiwania.
Aby uzyskać więcej informacji, zobacz dokumentację procesora telemetrii.
Uwaga
Jeśli chcesz usunąć określone (całe) zakresy na potrzeby kontrolowania kosztów pozyskiwania, zobacz Przesłonięcia próbkowania.
Instrumentacja niestandardowa (wersja zapoznawcza)
Począwszy od wersji 3.3.1, można przechwytywać zakresy dla metody w aplikacji:
{
"preview": {
"customInstrumentation": [
{
"className": "my.package.MyClass",
"methodName": "myMethod"
}
]
}
}
Lokalne wyłączanie próbkowania pozyskiwania (wersja zapoznawcza)
Domyślnie, gdy efektywna wartość procentowa próbkowania w agencie Java wynosi 100%, a próbkowanie pozyskiwania zostało skonfigurowane w zasobie usługi Application Insights, zostanie zastosowana wartość procentowa próbkowania pozyskiwania.
Należy pamiętać, że to zachowanie dotyczy zarówno próbkowania o stałej szybkości wynoszącej 100%, jak i ma zastosowanie do próbkowania z ograniczoną szybkością, gdy szybkość żądania nie przekracza limitu szybkości (efektywnie przechwytując 100% w ciągłym przesuwaniu przedziału czasu).
Począwszy od wersji 3.5.3, można wyłączyć to zachowanie (i zachować 100% danych telemetrycznych nawet wtedy, gdy próbkowanie pozyskiwania zostało skonfigurowane w zasobie usługi Application Insights):
{
"preview": {
"sampling": {
"ingestionSamplingEnabled": false
}
}
}
Automatyczne rejestrowanie
Log4j, Logback, JBoss Logging i java.util.logging są automatycznie tworzone. Rejestrowanie wykonywane za pośrednictwem tych struktur rejestrowania jest automatycznie generowane.
Rejestrowanie jest przechwytywane tylko wtedy, gdy:
- Spełnia skonfigurowany poziom dla platformy rejestrowania.
- Spełnia również skonfigurowany poziom usługi Application Insights.
Jeśli na przykład struktura rejestrowania jest skonfigurowana do rejestrowania WARN (i skonfigurowano ją zgodnie z wcześniejszym opisem) z pakietu com.example, a usługa Application Insights jest skonfigurowana do przechwytywania INFO (i skonfigurowana zgodnie z opisem), usługa Application Insights przechwytuje WARN tylko (i poważniejsze) z pakietu com.example.
Domyślnym poziomem skonfigurowanym dla usługi Application Insights jest INFO. Jeśli chcesz zmienić ten poziom:
{
"instrumentation": {
"logging": {
"level": "WARN"
}
}
}
Poziom można również ustawić przy użyciu zmiennej środowiskowej APPLICATIONINSIGHTS_INSTRUMENTATION_LOGGING_LEVEL. Następnie ma pierwszeństwo przed poziomem określonym w konfiguracji JSON.
Możesz użyć tych prawidłowych level wartości do określenia w applicationinsights.json pliku. W tabeli przedstawiono sposób, w jaki odpowiadają poziomom rejestrowania w różnych strukturach rejestrowania.
| Poziom | Log4j | Rejestrowanie zwrotne | JBoss | LIP |
|---|---|---|---|---|
| WYŁ. | WYŁ. | WYŁ. | WYŁ. | WYŁ. |
| ŚMIERTELNY | ŚMIERTELNY | BŁĄD | ŚMIERTELNY | SILNY |
| BŁĄD (lub POWAŻNY) | BŁĄD | BŁĄD | BŁĄD | SILNY |
| OSTRZEGAJ (lub OSTRZEŻENIE) | OSTRZEGAĆ | OSTRZEGAĆ | OSTRZEGAĆ | OSTRZEŻENIE |
| INFO | INFO | INFO | INFO | INFO |
| Konfiguracja | DEBUG | DEBUG | DEBUG | Konfiguracja |
| DEBUGOWANIE (lub GRZYWNA) | DEBUG | DEBUG | DEBUG | GRZYWNA |
| DROBNIEJSZE | DEBUG | DEBUG | DEBUG | DROBNIEJSZE |
| TRACE (lub FINEST) | TRACE | TRACE | TRACE | NAJLEPSZYCH |
| ALL | ALL | ALL | ALL | ALL |
Uwaga
Jeśli obiekt wyjątku zostanie przekazany do rejestratora, komunikat dziennika (i szczegóły obiektu wyjątku) pojawi się w witrynie Azure Portal w exceptions tabeli zamiast traces tabeli. Jeśli chcesz wyświetlić komunikaty dzienników w tabelach iexceptions, traces możesz napisać zapytanie Dzienniki (Kusto) w celu połączenia między nimi. Na przykład:
union traces, (exceptions | extend message = outerMessage)
| project timestamp, message, itemType
Znaczniki dziennika (wersja zapoznawcza)
Począwszy od wersji 3.4.2, można przechwycić znaczniki dziennika dla logback i Log4j 2:
{
"preview": {
"captureLogbackMarker": true,
"captureLog4jMarker": true
}
}
Inne atrybuty dziennika logback (wersja zapoznawcza)
Począwszy od wersji 3.4.3, można przechwytywać FileNamewartości , ClassName, MethodNamei LineNumber, dla usługi Logback:
{
"preview": {
"captureLogbackCodeAttributes": true
}
}
Ostrzeżenie
Przechwytywanie atrybutów kodu może zwiększyć obciążenie związane z wydajnością.
Poziom rejestrowania jako wymiar niestandardowy
Począwszy od wersji 3.3.0, nie jest przechwytywany domyślnie jako część niestandardowego wymiaru Traces, LoggingLevel ponieważ te dane są już przechwytywane w SeverityLevel polu.
W razie potrzeby możesz tymczasowo ponownie włączyć poprzednie zachowanie:
{
"preview": {
"captureLoggingLevelAsCustomDimension": true
}
}
Metryki mikrometrów autokolektowanych (w tym metryki siłownika Spring Boot)
Jeśli aplikacja używa mikrometru, metryki wysyłane do rejestru globalnego mikrometrów są automatycznie tworzone.
Ponadto jeśli aplikacja używa siłownika Spring Boot, metryki skonfigurowane przez siłownik Spring Boot również są automatycznie tworzone.
Aby wysłać metryki niestandardowe przy użyciu mikrometru:
Dodaj mikrometr do aplikacji, jak pokazano w poniższym przykładzie.
<dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-core</artifactId> <version>1.6.1</version> </dependency>Użyj rejestru globalnego mikrometru, aby utworzyć miernik, jak pokazano w poniższym przykładzie.
static final Counter counter = Metrics.counter("test.counter");Użyj licznika, aby zarejestrować metryki przy użyciu następującego polecenia.
counter.increment();Metryki są pozyskiwane do tabeli customMetrics z tagami przechwytywanymi w kolumnie
customDimensions. Metryki można również wyświetlić w Eksploratorze metryk wLog-based metricsobszarze przestrzeni nazw metryki.Uwaga
Język Java usługi Application Insights zastępuje wszystkie znaki inne niż alfanumeryczne (z wyjątkiem kreski) w nazwie metryki Micrometer podkreśleniami. W związku z tym poprzednia
test.countermetryka będzie wyświetlana jakotest_counter.
Aby wyłączyć automatyczne tworzenie kolekcji metryk mikrometrów i metryk siłownika Spring Boot:
Uwaga
Metryki niestandardowe są rozliczane oddzielnie i mogą generować dodatkowe koszty. Pamiętaj, aby sprawdzić informacje o cenach. Aby wyłączyć metryki mikrometru i siłownika Spring Boot, dodaj następującą konfigurację do pliku konfiguracji.
{
"instrumentation": {
"micrometer": {
"enabled": false
}
}
}
Maskowanie zapytań dotyczących łączności z bazą danych Java
Wartości literałów w zapytaniach JDBC (Java Database Connectivity) są domyślnie maskowane, aby uniknąć przypadkowego przechwytywania poufnych danych.
Począwszy od wersji 3.4.0, to zachowanie można wyłączyć. Na przykład:
{
"instrumentation": {
"jdbc": {
"masking": {
"enabled": false
}
}
}
}
Maskowanie zapytań Mongo
Wartości literałów w zapytaniach Mongo są domyślnie maskowane, aby uniknąć przypadkowego przechwytywania poufnych danych.
Począwszy od wersji 3.4.0, to zachowanie można wyłączyć. Na przykład:
{
"instrumentation": {
"mongo": {
"masking": {
"enabled": false
}
}
}
}
Nagłówki HTTP
Począwszy od wersji 3.3.0, można przechwytywać nagłówki żądań i odpowiedzi na serwerze (żądanie) telemetrii:
{
"preview": {
"captureHttpServerHeaders": {
"requestHeaders": [
"My-Header-A"
],
"responseHeaders": [
"My-Header-B"
]
}
}
}
Nazwy nagłówków są niewrażliwe na wielkość liter.
Powyższe przykłady są przechwytywane pod nazwami http.request.header.my_header_a właściwości i http.response.header.my_header_b.
Podobnie można przechwytywać nagłówki żądań i odpowiedzi na telemetrię klienta (zależności):
{
"preview": {
"captureHttpClientHeaders": {
"requestHeaders": [
"My-Header-C"
],
"responseHeaders": [
"My-Header-D"
]
}
}
}
Ponownie nazwy nagłówków są niewrażliwe na wielkość liter. Powyższe przykłady są przechwytywane pod nazwami http.request.header.my_header_c właściwości i http.response.header.my_header_d.
Kody odpowiedzi serwera HTTP 4xx
Domyślnie żądania serwera HTTP, które powodują kod odpowiedzi 4xx, są przechwytywane jako błędy.
Począwszy od wersji 3.3.0, można zmienić to zachowanie, aby przechwycić je jako pomyślne:
{
"preview": {
"captureHttpServer4xxAsError": false
}
}
Pomijanie określonych telemetrii autokolektowanych
Począwszy od wersji 3.0.3, określone dane telemetryczne autokolektowane mogą być pomijane przy użyciu następujących opcji konfiguracji:
{
"instrumentation": {
"azureSdk": {
"enabled": false
},
"cassandra": {
"enabled": false
},
"jdbc": {
"enabled": false
},
"jms": {
"enabled": false
},
"kafka": {
"enabled": false
},
"logging": {
"enabled": false
},
"micrometer": {
"enabled": false
},
"mongo": {
"enabled": false
},
"quartz": {
"enabled": false
},
"rabbitmq": {
"enabled": false
},
"redis": {
"enabled": false
},
"springScheduling": {
"enabled": false
}
}
}
Możesz również pominąć te instrumentacje, ustawiając następujące zmienne środowiskowe na false:
APPLICATIONINSIGHTS_INSTRUMENTATION_AZURE_SDK_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_CASSANDRA_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_JDBC_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_JMS_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_KAFKA_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_LOGGING_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_MICROMETER_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_MONGO_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_RABBITMQ_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_REDIS_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_SPRING_SCHEDULING_ENABLED
Te zmienne mają następnie pierwszeństwo przed włączonymi zmiennymi określonymi w konfiguracji JSON.
Uwaga
Jeśli szukasz bardziej szczegółowej kontrolki, na przykład, aby pominąć niektóre wywołania usługi Redis, ale nie wszystkie wywołania usługi Redis, zobacz Próbkowanie przesłonięcia.
Instrumentacje w wersji zapoznawczej
Począwszy od wersji 3.2.0, można włączyć następujące instrumentacje w wersji zapoznawczej:
{
"preview": {
"instrumentation": {
"akka": {
"enabled": true
},
"apacheCamel": {
"enabled": true
},
"grizzly": {
"enabled": true
},
"ktor": {
"enabled": true
},
"play": {
"enabled": true
},
"r2dbc": {
"enabled": true
},
"springIntegration": {
"enabled": true
},
"vertx": {
"enabled": true
}
}
}
}
Uwaga
Instrumentacja Akka jest dostępna od wersji 3.2.2. Instrumentacja biblioteki HTTP Vertx jest dostępna od wersji 3.3.0.
Interwał metryk
Domyślnie metryki są przechwytywane co 60 sekund.
Począwszy od wersji 3.0.3, można zmienić ten interwał:
{
"metricIntervalSeconds": 300
}
Począwszy od wersji 3.4.9 OGÓLNIE, można również ustawić metricIntervalSeconds zmienną środowiskową przy użyciu zmiennej środowiskowej APPLICATIONINSIGHTS_METRIC_INTERVAL_SECONDS. Następnie ma pierwszeństwo przed metricIntervalSeconds określonym w konfiguracji JSON.
Ustawienie dotyczy następujących metryk:
- Domyślne liczniki wydajności: na przykład procesor CPU i pamięć
- Domyślne metryki niestandardowe: na przykład chronometraż odzyskiwania pamięci
- Skonfigurowane metryki JMX: zobacz sekcję metryki JMX
- Metryki mikrometrów: zobacz sekcję Autokolektowane metryki mikrometrów
Puls
Domyślnie usługa Application Insights Java 3.x wysyła metrykę pulsu co 15 minut. Jeśli używasz metryki pulsu do wyzwalania alertów, możesz zwiększyć częstotliwość tego pulsu:
{
"heartbeat": {
"intervalSeconds": 60
}
}
Uwaga
Nie można zwiększyć interwału do dłuższego niż 15 minut, ponieważ dane pulsu są również używane do śledzenia użycia usługi Application Insights.
Uwierzytelnianie
Uwaga
Funkcja uwierzytelniania jest ogólnie dostępna od wersji 3.4.17.
Uwierzytelnianie służy do konfigurowania agenta do generowania poświadczeń tokenu wymaganych do uwierzytelniania firmy Microsoft Entra. Aby uzyskać więcej informacji, zobacz dokumentację uwierzytelniania .
Serwer proxy HTTP
Jeśli aplikacja znajduje się za zaporą i nie może połączyć się bezpośrednio z usługą Application Insights, zapoznaj się z adresami IP używanymi przez usługę Application Insights.
Aby obejść ten problem, możesz skonfigurować środowisko Java 3.x usługi Application Insights do korzystania z serwera proxy HTTP.
{
"proxy": {
"host": "myproxy",
"port": 8080
}
}
Serwer proxy http można również ustawić przy użyciu zmiennej środowiskowej APPLICATIONINSIGHTS_PROXY, która przyjmuje format https://<host>:<port>. Następnie pierwszeństwo przed serwerem proxy określonym w konfiguracji JSON.
Możesz podać użytkownikowi i hasło serwera proxy ze zmienną APPLICATIONINSIGHTS_PROXY środowiskową: https://<user>:<password>@<host>:<port>.
Język Java 3.x usługi Application Insights uwzględnia również właściwości globalne https.proxyHost i https.proxyPort systemowe, jeśli są ustawione, i http.nonProxyHosts, jeśli to konieczne.
Odzyskiwanie po niepowodzeniach pozyskiwania
W przypadku niepowodzenia wysyłania danych telemetrycznych do usługi Application Insights usługa Application Insights Java 3.x przechowuje dane telemetryczne na dysku i kontynuuje ponawianie próby z dysku.
Domyślny limit trwałości dysku wynosi 50 Mb. Jeśli masz dużą ilość danych telemetrycznych lub chcesz mieć możliwość odzyskania sprawności po dłuższych awariach sieci lub usługi pozyskiwania, możesz zwiększyć ten limit, począwszy od wersji 3.3.0:
{
"preview": {
"diskPersistenceMaxSizeMb": 50
}
}
Samodzielna diagnostyka
"Samodzielna diagnostyka" odnosi się do wewnętrznego rejestrowania z poziomu środowiska Java 3.x usługi Application Insights. Ta funkcja może być przydatna do wykrywania i diagnozowania problemów z samą usługą Application Insights.
Domyślnie dzienniki java 3.x usługi Application Insights na poziomie INFO zarówno do pliku applicationinsights.log , jak i konsoli, odpowiadające tej konfiguracji:
{
"selfDiagnostics": {
"destination": "file+console",
"level": "INFO",
"file": {
"path": "applicationinsights.log",
"maxSizeMb": 5,
"maxHistory": 1
}
}
}
W poprzednim przykładzie konfiguracji:
levelmoże być jednym zOFFelementów ,ERROR,INFOWARN, ,DEBUGlubTRACE.pathmoże być ścieżką bezwzględną lub względną. Ścieżki względne są rozpoznawane względem katalogu, w którymapplicationinsights-agent-3.6.2.jarsię znajduje.
Począwszy od wersji 3.0.2, można również ustawić samodzielną diagnostykę level przy użyciu zmiennej środowiskowej APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_LEVEL. Następnie ma pierwszeństwo przed poziomem samodzielnej diagnostyki określonym w konfiguracji JSON.
Począwszy od wersji 3.0.3, można również ustawić lokalizację pliku samodzielnej diagnostyki przy użyciu zmiennej środowiskowej APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_FILE_PATH. Następnie pierwszeństwo ma ścieżka pliku samodzielnej diagnostyki określona w konfiguracji JSON.
Korelacja telemetrii
Korelacja telemetrii jest domyślnie włączona, ale można ją wyłączyć w konfiguracji.
{
"preview": {
"disablePropagation": true
}
}
Przykład
W tym przykładzie pokazano, jak wygląda plik konfiguracji z wieloma składnikami. Skonfiguruj określone opcje na podstawie Twoich potrzeb.
{
"connectionString": "...",
"role": {
"name": "my cloud role name"
},
"sampling": {
"percentage": 100
},
"jmxMetrics": [
],
"customDimensions": {
},
"instrumentation": {
"logging": {
"level": "INFO"
},
"micrometer": {
"enabled": true
}
},
"proxy": {
},
"preview": {
"processors": [
]
},
"selfDiagnostics": {
"destination": "file+console",
"level": "INFO",
"file": {
"path": "applicationinsights.log",
"maxSizeMb": 5,
"maxHistory": 1
}
}
}