Tryb failover i stosowanie poprawek w usłudze Azure Managed Redis (wersja zapoznawcza)
Aby tworzyć odporne i pomyślne aplikacje klienckie, ważne jest zrozumienie trybu failover w usłudze Azure Managed Redis (wersja zapoznawcza). Tryb failover może być częścią planowanych operacji zarządzania lub może być spowodowany przez nieplanowane awarie sprzętu lub sieci. Typowym zastosowaniem trybu failover pamięci podręcznej jest zastosowanie, gdy usługa zarządzania poprawia pliki binarne usługi Azure Managed Redis.
W tym artykule znajdują się następujące informacje:
- Co to jest tryb failover?
- Jak odbywa się tryb failover podczas stosowania poprawek.
- Jak utworzyć odporną aplikację kliencką.
Co to jest tryb failover?
Zacznijmy od omówienia trybu failover dla usługi Azure Managed Redis.
Krótkie podsumowanie architektury pamięci podręcznej
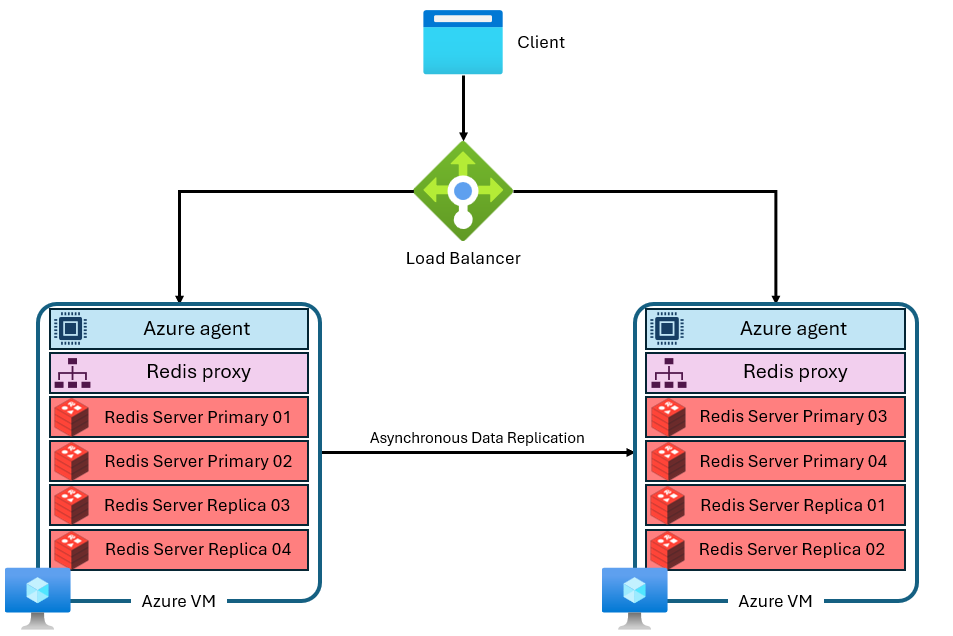
Pamięć podręczna jest tworzona z wielu maszyn wirtualnych z oddzielnymi i prywatnymi adresami IP. Każda maszyna wirtualna (lub "węzeł") uruchamia wiele procesów serwera Redis (nazywanych "fragmentami") równolegle. Wiele fragmentów umożliwia bardziej wydajne wykorzystanie procesorów wirtualnych na każdej maszynie wirtualnej i wyższą wydajność. Nie wszystkie podstawowe fragmenty usługi Redis znajdują się na tej samej maszynie wirtualnej/węźle. Zamiast tego fragmenty podstawowe i repliki są rozproszone w obu węzłach. Ponieważ podstawowe fragmenty korzystają z większej liczby zasobów procesora NIŻ fragmenty repliki, takie podejście umożliwia równoległe uruchamianie większej liczby podstawowych fragmentów. Każdy węzeł ma proces serwera proxy o wysokiej wydajności do zarządzania fragmentami, obsługi zarządzania połączeniami i wyzwalania samonaprawiania. Jeden fragment może być wyłączony, podczas gdy pozostałe pozostają dostępne.
Szczegółowe informacje na temat architektury usługi Azure Managed Redis można znaleźć tutaj.
Wyjaśnienie przełączania awaryjnego
Przełączanie awaryjne występuje, gdy co najmniej jeden fragment repliki podwyższa swój poziom, aby stać się podstawowym fragmentem, a stare fragmenty podstawowe zamykają istniejące połączenia. Przejście w tryb failover może być planowane lub nieplanowane.
Planowane przejście w tryb failover odbywa się w dwóch różnych okresach:
- Aktualizacje systemu, w tym poprawki usługi Redis lub systemu operacyjnego.
- Operacje zarządzania, takie jak skalowanie i ponowne uruchamianie.
Ponieważ węzły otrzymują powiadomienie o aktualizacji z wyprzedzeniem, mogą wspólnie zamieniać role i szybko aktualizować Load Balancer zmiany. Planowane przełączanie awaryjne zwykle kończy się w mniej niż 1 sekundę.
Nieplanowane przejście w tryb failover może wystąpić z powodu awarii sprzętu, awarii sieci lub innych nieoczekiwanych awarii co najmniej jednego węzła w klastrze. Fragmenty repliki w pozostałych węzłach będą podwyższać poziom do podstawowego w celu zachowania dostępności, ale proces trwa dłużej. Fragment repliki musi najpierw wykryć, że jego podstawowy fragment nie jest dostępny, zanim będzie mógł rozpocząć proces przełączania awaryjnego. Fragment repliki musi również sprawdzić, czy ten nieplanowany błąd nie jest przejściowy ani lokalny, aby uniknąć niepotrzebnego przełączania awaryjnego. To opóźnienie w wykrywaniu oznacza, że nieplanowane przełączanie awaryjne zwykle kończy się w ciągu od 10 do 15 sekund.
Jak występuje stosowanie poprawek?
Usługa Azure Managed Redis regularnie aktualizuje pamięć podręczną za pomocą najnowszych funkcji i poprawek platformy. Aby zastosować poprawkę pamięci podręcznej, usługa wykonuje następujące kroki:
- Usługa tworzy nowe aktualne maszyny wirtualne, aby zastąpić wszystkie poprawki maszyn wirtualnych.
- Następnie promuje jedną z nowych maszyn wirtualnych jako lidera klastra.
- Jeden po drugim, wszystkie węzły, które są poprawiane, są usuwane z klastra. Wszystkie fragmenty tych maszyn wirtualnych zostaną zdegradowane i zmigrowane do jednej z nowych maszyn wirtualnych.
- Na koniec wszystkie zastąpione maszyny wirtualne zostaną usunięte.
Każdy fragment klastrowanej pamięci podręcznej jest poprawiany oddzielnie i nie zamyka połączeń z innym fragmentem.
Wiele pamięci podręcznych w tej samej grupie zasobów i regionie jest również poprawianych pojedynczo. Pamięci podręczne, które znajdują się w różnych grupach zasobów lub w różnych regionach, mogą być poprawiane jednocześnie.
Ponieważ pełna synchronizacja danych odbywa się przed powtórzeniu procesu, utrata danych jest mało prawdopodobna dla pamięci podręcznej. Możesz dodatkowo chronić przed utratą danych, eksportując dane i włączając trwałość.
Dodatkowe ładowanie pamięci podręcznej
Za każdym razem, gdy nastąpi przełączanie awaryjne, pamięci podręczne muszą replikować dane z jednego węzła do drugiego. Ta replikacja powoduje wzrost obciążenia zarówno pamięci serwera, jak i procesora CPU. Jeśli wystąpienie pamięci podręcznej jest już mocno obciążone, aplikacje klienckie mogą mieć zwiększone opóźnienie. W skrajnych przypadkach aplikacje klienckie mogą otrzymywać wyjątki dotyczące limitu czasu.
Jak tryb failover wpływa na moją aplikację kliencką?
Aplikacje klienckie mogą otrzymywać błędy z wystąpienia usługi Azure Managed Redis. Liczba błędów widocznych w aplikacji klienckiej zależy od liczby operacji oczekujących na to połączenie w czasie przełączania awaryjnego. Każde połączenie kierowane przez węzeł, który zamknął połączenie, będzie powodować błędy.
Wiele bibliotek klienckich może zgłaszać różne typy błędów w przypadku przerwania połączeń, w tym:
- Wyjątki dotyczące limitu czasu
- Wyjątki połączeń
- Wyjątki gniazd
Liczba i typ wyjątków zależą od tego, gdzie żądanie znajduje się w ścieżce kodu, gdy pamięć podręczna zamyka jego połączenia. Na przykład operacja, która wysyła żądanie, ale nie otrzymała odpowiedzi, gdy nastąpi przełączanie awaryjne, może uzyskać wyjątek dotyczący limitu czasu. Nowe żądania w obiekcie zamkniętego połączenia odbierają wyjątki połączeń do momentu pomyślnego ponownego nawiązania połączenia.
Większość bibliotek klienckich próbuje ponownie nawiązać połączenie z pamięcią podręczną, jeśli są one skonfigurowane w ten sposób. Jednak nieprzewidziane usterki mogą czasami sprawić, że nie będzie można odzyskać obiektów biblioteki. Jeśli błędy będą się powtarzać przez dłuższy niż wstępnie skonfigurowany czas, obiekt połączenia powinien zostać ponownie utworzony. W Microsoft.NET i innych językach ukierunkowanych na obiekt ponowne tworzenie połączenia bez ponownego uruchamiania aplikacji można wykonać przy użyciu wzorca ForceReconnect.
Jakie aktualizacje są objęte konserwacją?
Konserwacja obejmuje następujące aktualizacje:
- Aktualizacje serwera Redis: każda aktualizacja lub poprawka plików binarnych serwera Redis.
- Aktualizacje maszyny wirtualnej: wszystkie aktualizacje maszyny wirtualnej hostująca usługę Redis. Aktualizacje maszyn wirtualnych obejmują stosowanie poprawek składników oprogramowania w środowisku hostingu w celu uaktualniania składników sieciowych lub likwidowania.
Czy konserwacja jest wyświetlana w kondycji usługi w witrynie Azure Portal przed poprawką?
Nie, konserwacja nie jest wyświetlana w obszarze kondycji usługi w portalu ani w żadnym innym miejscu.
Zmiany sieci/konfiguracji klienckiej
Niektóre zmiany konfiguracji sieci po stronie klienta mogą wyzwalać brak dostępnych błędów połączenia. Takie zmiany mogą obejmować:
- Zamiana wirtualnego adresu IP aplikacji klienckiej między miejscami przejściowymi i produkcyjnymi.
- Skalowanie rozmiaru lub liczby wystąpień aplikacji.
Takie zmiany mogą powodować problem z łącznością, który zwykle trwa krócej niż minutę. Aplikacja kliencka prawdopodobnie utraci połączenie z innymi zasobami sieci zewnętrznej, ale także z usługą Azure Managed Redis.
Tworzenie odporności
Nie można całkowicie uniknąć przełączania awaryjnego. Zamiast tego napisz aplikacje klienckie tak, aby były odporne na przerwy połączeń i żądania, które zakończyły się niepowodzeniem. Większość bibliotek klienckich automatycznie łączy się ponownie z punktem końcowym pamięci podręcznej, ale niewiele z nich próbuje ponowić nieudane żądania. W zależności od scenariusza aplikacji warto użyć logiki ponawiania prób z odczekiwaniem.
Jak sprawić, aby aplikacja była odporna?
Zapoznaj się z tymi wzorcami projektowania, aby otrzymać odporność, zwłaszcza jeśli chodzi o wyłącznik i wzorce ponawiania prób:
- Wzorce niezawodności — wzorce projektowe chmury
- Wskazówki dotyczące ponawiania prób dla usług platformy Azure — najlepsze rozwiązania dotyczące aplikacji w chmurze
- Implementowanie ponownych prób przy użyciu wycofywania wykładniczego