Najlepsze rozwiązania dotyczące wdrażania i niezawodności klastra dla usługi Azure Kubernetes Service (AKS)
Ten artykuł zawiera najlepsze rozwiązania dotyczące niezawodności klastra zaimplementowane zarówno na poziomie wdrożenia, jak i klastra dla obciążeń usługi Azure Kubernetes Service (AKS). Ten artykuł jest przeznaczony dla operatorów klastrów i deweloperów, którzy są odpowiedzialni za wdrażanie aplikacji i zarządzanie nimi w usłudze AKS.
Najlepsze rozwiązania opisane w tym artykule są zorganizowane w następujące kategorie:
Najlepsze rozwiązania dotyczące poziomu wdrożenia
Poniższe najlepsze rozwiązania dotyczące poziomu wdrożenia pomagają zapewnić wysoką dostępność i niezawodność obciążeń usługi AKS. Te najlepsze rozwiązania to konfiguracje lokalne, które można zaimplementować w plikach YAML dla zasobników i wdrożeń.
Uwaga
Upewnij się, że te najlepsze rozwiązania są implementne za każdym razem, gdy wdrażasz aktualizację w aplikacji. W przeciwnym razie mogą wystąpić problemy z dostępnością i niezawodnością aplikacji, takie jak niezamierzony przestój aplikacji.
Budżety zakłóceń zasobników (PDB)
Wskazówki dotyczące najlepszych rozwiązań
Użyj budżetów zakłóceń zasobników (PDB), aby upewnić się, że minimalna liczba zasobników pozostaje dostępna podczas dobrowolnych zakłóceń, takich jak operacje uaktualniania lub przypadkowe usunięcie zasobników.
Budżety zakłóceń zasobników (PDB) umożliwiają zdefiniowanie sposobu reagowania wdrożeń lub zestawów replik podczas dobrowolnych zakłóceń, takich jak operacje uaktualniania lub przypadkowe usunięcie zasobników. Za pomocą plików PDB można zdefiniować minimalną lub maksymalną liczbę niedostępnych zasobów. Pliki PDB wpływają tylko na interfejs API eksmisji w przypadku dobrowolnych zakłóceń.
Załóżmy na przykład, że musisz przeprowadzić uaktualnienie klastra i mieć już zdefiniowany plik PDB. Przed przeprowadzeniem uaktualnienia klastra harmonogram Kubernetes gwarantuje, że minimalna liczba zasobników zdefiniowanych w pliku PDB jest dostępna. Jeśli uaktualnienie spowoduje, że liczba dostępnych zasobników spadnie poniżej minimum zdefiniowanego w plikach PDB, harmonogram harmonogramuje dodatkowe zasobniki na innych węzłach przed zezwoleniem na kontynuowanie uaktualniania. Jeśli nie ustawisz pliku PDB, harmonogram nie ma żadnych ograniczeń dotyczących liczby zasobników, które mogą być niedostępne podczas uaktualniania, co może prowadzić do braku zasobów i potencjalnych awarii klastra.
W poniższym przykładowym pliku minAvailable definicji PDB pole ustawia minimalną liczbę zasobników, które muszą pozostać dostępne podczas dobrowolnych zakłóceń. Wartość może być liczbą bezwzględną (na przykład 3) lub procentem żądanej liczby zasobników (na przykład 10%).
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: mypdb
spec:
minAvailable: 3 # Minimum number of pods that must remain available during voluntary disruptions
selector:
matchLabels:
app: myapp
Aby uzyskać więcej informacji, zobacz Planowanie dostępności przy użyciu plików PDB i Określanie budżetu zakłóceń dla aplikacji.
Limity procesora CPU i pamięci zasobnika
Wskazówki dotyczące najlepszych rozwiązań
Ustaw limity procesora i pamięci zasobnika dla wszystkich zasobników, aby upewnić się, że zasobniki nie zużywają wszystkich zasobów w węźle i zapewniają ochronę podczas zagrożeń usługi, takich jak ataki DDoS.
Limity procesora CPU i pamięci zasobnika definiują maksymalną ilość procesora CPU i pamięci, z których może korzystać zasobnik. Gdy zasobnik przekroczy zdefiniowane limity, zostanie oznaczony do usunięcia. Aby uzyskać więcej informacji, zobacz Jednostki zasobów procesora CPU w jednostkach zasobów kubernetes i pamięci w rozwiązaniu Kubernetes.
Ustawienie limitów procesora CPU i pamięci pomaga zachować kondycję węzła i zminimalizować wpływ na inne zasobniki w węźle. Unikaj ustawiania limitu zasobnika wyższego niż węzły mogą obsługiwać. Każdy węzeł usługi AKS rezerwuje zestaw zasobów procesora CPU i pamięci dla podstawowych składników platformy Kubernetes. Jeśli ustawisz limit zasobnika wyższy niż węzeł może obsługiwać, aplikacja może próbować zużywać zbyt wiele zasobów i negatywnie wpływać na inne zasobniki w węźle. Administratorzy klastra muszą ustawić limity przydziału zasobów w przestrzeni nazw, która wymaga ustawienia żądań zasobów i limitów. Aby uzyskać więcej informacji, zobacz Wymuszanie przydziałów zasobów w usłudze AKS.
W poniższym przykładowym pliku resources definicji zasobnika sekcja ustawia limity procesora CPU i pamięci dla zasobnika:
kind: Pod
apiVersion: v1
metadata:
name: mypod
spec:
containers:
- name: mypod
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256Mi
Napiwek
Możesz użyć kubectl describe node polecenia , aby wyświetlić pojemność procesora i pamięci węzłów, jak pokazano w poniższym przykładzie:
kubectl describe node <node-name>
# Example output
Capacity:
cpu: 8
ephemeral-storage: 129886128Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32863116Ki
pods: 110
Allocatable:
cpu: 7820m
ephemeral-storage: 119703055367
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 28362636Ki
pods: 110
Aby uzyskać więcej informacji, zobacz Przypisywanie zasobów procesora CPU do kontenerów i zasobników oraz Przypisywanie zasobów pamięci do kontenerów i zasobników.
Zaczepy przed zatrzymaniem
Wskazówki dotyczące najlepszych rozwiązań
Jeśli ma to zastosowanie, użyj wstępnie zatrzymanych punktów zaczepienia, aby zapewnić bezproblemowe zakończenie kontenera.
Punkt PreStop zaczepienia jest wywoływany bezpośrednio przed zakończeniem kontenera z powodu żądania interfejsu API lub zdarzenia zarządzania, takiego jak wywłaszczanie, rywalizacja o zasoby lub niepowodzenie sondy liveness/startup. Wywołanie elementu zaczepienia PreStop kończy się niepowodzeniem, jeśli kontener jest już w stanie zakończonym lub ukończonym, a punkt zaczepienia musi zostać zakończony przed wysłaniem sygnału TERM, aby zatrzymać kontener. Odliczanie okresu prolongaty zakończenia zasobnika rozpoczyna się przed wykonaniem haka PreStop , więc kontener ostatecznie kończy się w okresie prolongaty zakończenia.
Poniższy przykładowy plik definicji zasobnika pokazuje, jak używać haka PreStop w celu zapewnienia bezproblemowego zakończenia kontenera:
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done"]
Aby uzyskać więcej informacji, zobacz Punkt zaczepienia cyklu życia kontenera i Kończenie kończenia zasobników.
maxUnavailable
Wskazówki dotyczące najlepszych rozwiązań
Zdefiniuj maksymalną liczbę zasobników, które mogą być niedostępne podczas aktualizacji stopniowej przy użyciu
maxUnavailablepola we wdrożeniu, aby upewnić się, że minimalna liczba zasobników pozostanie dostępna podczas uaktualniania.
Pole maxUnavailable określa maksymalną liczbę zasobników, które mogą być niedostępne podczas procesu aktualizacji. Wartość może być liczbą bezwzględną (na przykład 3) lub procentem żądanej liczby zasobników (na przykład 10%). maxUnavailable odnosi się do interfejsu API usuwania, który jest używany podczas aktualizacji stopniowej.
Poniższy przykładowy manifest wdrożenia używa maxAvailable pola , aby ustawić maksymalną liczbę zasobników, które mogą być niedostępne podczas procesu aktualizacji:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 # Maximum number of pods that can be unavailable during the upgrade
Aby uzyskać więcej informacji, zobacz Max Unavailable (Maksymalna niedostępna).
Ograniczenia rozprzestrzeniania się topologii zasobnika
Wskazówki dotyczące najlepszych rozwiązań
Użyj ograniczeń rozprzestrzeniania się topologii zasobników, aby upewnić się, że zasobniki są rozmieszczone w różnych węzłach lub strefach w celu zwiększenia dostępności i niezawodności.
Za pomocą ograniczeń rozprzestrzeniania topologii zasobników można kontrolować rozmieszczenie zasobników w klastrze w oparciu o topologię węzłów i rozmieszczać zasobniki w różnych węzłach lub strefach w celu zwiększenia dostępności i niezawodności.
Poniższy przykładowy plik definicji zasobnika pokazuje, jak używać topologySpreadConstraints pola do rozmieszczania zasobników w różnych węzłach:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# Configure a topology spread constraint
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # optional
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # optional
nodeAffinityPolicy: [Honor|Ignore] # optional
nodeTaintsPolicy: [Honor|Ignore] # optional
Aby uzyskać więcej informacji, zobacz Ograniczenia spreadu topologii zasobnika.
Gotowość, żywość i sondy uruchamiania
Wskazówki dotyczące najlepszych rozwiązań
Skonfiguruj gotowość, dostępność i sondy uruchamiania, jeśli ma to zastosowanie, aby zwiększyć odporność na duże obciążenia i niższe ponowne uruchomienia kontenera.
Sondy gotowości
Na platformie Kubernetes narzędzie kubelet używa sond gotowości, aby wiedzieć, kiedy kontener jest gotowy do rozpoczęcia akceptowania ruchu. Zasobnik jest uważany za gotowy , gdy wszystkie jego kontenery są gotowe. Gdy zasobnik nie jest gotowy, zostanie usunięty z modułów równoważenia obciążenia usługi. Aby uzyskać więcej informacji, zobacz Readiness Probes in Kubernetes (Sondy gotowości na platformie Kubernetes).
Poniższy przykładowy plik definicji zasobnika przedstawia konfigurację sondy gotowości:
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
Aby uzyskać więcej informacji, zobacz Konfigurowanie sond gotowości.
Sondy liveness
Na platformie Kubernetes narzędzie kubelet używa sond liveness, aby wiedzieć, kiedy ponownie uruchomić kontener. Jeśli kontener ulegnie awarii sondy aktualności, kontener zostanie uruchomiony ponownie. Aby uzyskać więcej informacji, zobacz Liveness Probes in Kubernetes (Sondy na żywo na platformie Kubernetes).
Poniższy przykładowy plik definicji zasobnika przedstawia konfigurację sondy liveness:
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
Inny rodzaj sondy liveness używa żądania HTTP GET. Poniższy przykładowy plik definicji zasobnika przedstawia konfigurację sondy liveness żądania HTTP GET:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
Aby uzyskać więcej informacji, zobacz Configure liveness probes and Define a liveness HTTP request (Konfigurowanie sond na żywo) i Define a liveness HTTP request (Definiowanie żądania HTTP dotyczące żywości).
Sondy uruchamiania
Na platformie Kubernetes narzędzie kubelet używa sond startowych, aby wiedzieć, kiedy aplikacja kontenera została uruchomiona. Podczas konfigurowania sondy uruchamiania gotowość i sondy aktywności nie są uruchamiane, dopóki sonda uruchamiania nie powiedzie się, upewniając się, że sondy gotowości i aktywności nie zakłócają uruchamiania aplikacji. Aby uzyskać więcej informacji, zobacz Sondy uruchamiania na platformie Kubernetes.
Poniższy przykładowy plik definicji zasobnika przedstawia konfigurację sondy uruchamiania:
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 10
Aplikacje z wieloma replikami
Wskazówki dotyczące najlepszych rozwiązań
Wdróż co najmniej dwie repliki aplikacji, aby zapewnić wysoką dostępność i odporność w scenariuszach z węzłem w dół.
Na platformie Kubernetes możesz użyć pola we wdrożeniu replicas , aby określić liczbę zasobników, które chcesz uruchomić. Uruchamianie wielu wystąpień aplikacji pomaga zapewnić wysoką dostępność i odporność w scenariuszach z węzłem w dół. Jeśli masz włączone strefy dostępności, możesz użyć replicas pola , aby określić liczbę zasobników, które mają być uruchamiane w wielu strefach dostępności.
Poniższy przykładowy plik definicji zasobnika pokazuje, jak za pomocą replicas pola określić liczbę zasobników, które chcesz uruchomić:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Aby uzyskać więcej informacji, zobacz Zalecane rozwiązanie o wysokiej dostępności aktywne-aktywne — omówienie usługi AKS i replik w specyfikacjach wdrażania.
Najlepsze rozwiązania dotyczące poziomu puli klastrów i węzłów
Poniższe najlepsze rozwiązania dotyczące poziomu klastra i puli węzłów pomagają zapewnić wysoką dostępność i niezawodność klastrów usługi AKS. Te najlepsze rozwiązania można zaimplementować podczas tworzenia lub aktualizowania klastrów usługi AKS.
Strefy dostępności
Wskazówki dotyczące najlepszych rozwiązań
Użyj wielu stref dostępności podczas tworzenia klastra usługi AKS, aby zapewnić wysoką dostępność w scenariuszach dół strefy. Pamiętaj, że nie można zmienić konfiguracji strefy dostępności po utworzeniu klastra.
Strefy dostępności są oddzielnymi grupami centrów danych w obrębie regionu. Te strefy są wystarczająco blisko, aby mieć ze sobą połączenia o małych opóźnieniach, ale wystarczająco daleko od siebie, aby zmniejszyć prawdopodobieństwo, że więcej niż jedna strefa ma wpływ na lokalne awarie lub pogodę. Korzystanie ze stref dostępności ułatwia synchronizowanie danych i ich dostępność w scenariuszach dół strefy. Aby uzyskać więcej informacji, zobacz Uruchamianie w wielu strefach.
Skalowanie automatyczne klastra
Wskazówki dotyczące najlepszych rozwiązań
Użyj skalowania automatycznego klastra, aby upewnić się, że klaster może obsłużyć zwiększone obciążenie i zmniejszyć koszty podczas niskiego obciążenia.
Aby nadążyć za wymaganiami aplikacji w usłudze AKS, może być konieczne dostosowanie liczby węzłów, które uruchamiają obciążenia. Składnik automatycznego skalowania klastra obserwuje zasobniki w klastrze, których nie można zaplanować z powodu ograniczeń zasobów. Gdy narzędzie do automatycznego skalowania klastra wykryje problemy, skaluje w górę liczbę węzłów w puli węzłów, aby zaspokoić zapotrzebowanie aplikacji. Regularnie sprawdza również węzły pod kątem braku uruchomionych zasobników i skaluje w dół liczbę węzłów zgodnie z potrzebami. Aby uzyskać więcej informacji, zobacz Skalowanie automatyczne klastra w usłudze AKS.
Parametru --enable-cluster-autoscaler można użyć podczas tworzenia klastra usługi AKS w celu włączenia narzędzia do automatycznego skalowania klastra, jak pokazano w poniższym przykładzie:
az aks create \
--resource-group myResourceGroup \
--name myAKSCluster \
--node-count 2 \
--vm-set-type VirtualMachineScaleSets \
--load-balancer-sku standard \
--enable-cluster-autoscaler \
--min-count 1 \
--max-count 3 \
--generate-ssh-keys
Możesz również włączyć narzędzie do automatycznego skalowania klastra w istniejącej puli węzłów i skonfigurować bardziej szczegółowe szczegóły autoskalatora klastra, zmieniając wartości domyślne w profilu automatycznego skalowania w całym klastrze.
Aby uzyskać więcej informacji, zobacz Używanie narzędzia do automatycznego skalowania klastra w usłudze AKS.
Usługa Load Balancer w warstwie Standardowa
Wskazówki dotyczące najlepszych rozwiązań
Użyj usługa Load Balancer w warstwie Standardowa, aby zapewnić większą niezawodność i zasoby, obsługę wielu stref dostępności, sond HTTP i funkcji w wielu centrach danych.
Na platformie Azure jednostka SKU usługa Load Balancer w warstwie Standardowa została zaprojektowana tak, aby była wyposażona w równoważenie obciążenia ruchu w warstwie sieciowej, gdy jest wymagana wysoka wydajność i małe opóźnienia. Usługa Load Balancer w warstwie Standardowa kieruje ruch w różnych regionach i do stref dostępności w celu zapewnienia wysokiej odporności. Jednostka SKU w warstwie Standardowa to zalecana i domyślna jednostka SKU używana podczas tworzenia klastra usługi AKS.
Ważne
30 września 2025 r. usługa Load Balancer w warstwie Podstawowa zostanie wycofana. Więcej informacji znajdziesz w oficjalnym ogłoszeniu. Zalecamy użycie usługa Load Balancer w warstwie Standardowa dla nowych wdrożeń i uaktualnienie istniejących wdrożeń do usługa Load Balancer w warstwie Standardowa. Aby uzyskać więcej informacji, zobacz Uaktualnianie z podstawowego modułu równoważenia obciążenia.
W poniższym przykładzie pokazano LoadBalancer manifest usługi, który używa usługa Load Balancer w warstwie Standardowa:
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/azure-load-balancer-ipv4 # Service annotation for an IPv4 address
name: azure-load-balancer
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: azure-load-balancer
Aby uzyskać więcej informacji, zobacz Używanie standardowego modułu równoważenia obciążenia w usłudze AKS.
Napiwek
Można również użyć kontrolera ruchu przychodzącego lub siatki usług do zarządzania ruchem sieciowym, z każdą opcją zapewniającą różne funkcje i możliwości.
Pule węzłów systemu
Korzystanie z dedykowanych pul węzłów systemowych
Wskazówki dotyczące najlepszych rozwiązań
Użyj pul węzłów systemowych, aby upewnić się, że żadne inne aplikacje użytkownika nie działają w tych samych węzłach, co może powodować niedobór zasobów i wpływać na zasobniki systemowe.
Użyj dedykowanych pul węzłów systemowych, aby upewnić się, że żadna inna aplikacja użytkownika nie działa w tych samych węzłach, co może powodować niedobór zasobów i potencjalne awarie klastra z powodu warunków wyścigu. Aby użyć dedykowanej puli węzłów systemowych, można użyć defektu CriticalAddonsOnly w puli węzłów systemowych. Aby uzyskać więcej informacji, zobacz Używanie pul węzłów systemowych w usłudze AKS.
Skalowanie automatyczne dla pul węzłów systemowych
Wskazówki dotyczące najlepszych rozwiązań
Skonfiguruj narzędzie do automatycznego skalowania dla pul węzłów systemowych, aby ustawić minimalne i maksymalne limity skalowania dla puli węzłów.
Użyj narzędzia do automatycznego skalowania w pulach węzłów, aby skonfigurować minimalne i maksymalne limity skalowania dla puli węzłów. Pula węzłów systemowych powinna zawsze mieć możliwość skalowania w celu spełnienia wymagań zasobników systemowych. Jeśli pula węzłów systemowych nie może skalować, w klastrze zabraknie zasobów, aby ułatwić zarządzanie planowaniem, skalowaniem i równoważeniem obciążenia, co może prowadzić do braku odpowiedzi klastra.
Aby uzyskać więcej informacji, zobacz Używanie narzędzia do automatycznego skalowania klastra w pulach węzłów.
Co najmniej trzy węzły na pulę węzłów systemowych
Wskazówki dotyczące najlepszych rozwiązań
Upewnij się, że pule węzłów systemowych mają co najmniej trzy węzły, aby zapewnić odporność na scenariusze blokowania/uaktualniania, co może prowadzić do ponownego uruchomienia lub zamknięcia węzłów.
Pule węzłów systemowych służą do uruchamiania zasobników systemowych, takich jak kube-proxy, coredns i wtyczka azure CNI. Zalecamy upewnienie się , że pule węzłów systemowych mają co najmniej trzy węzły , aby zapewnić odporność na scenariusze blokowania/uaktualniania, co może prowadzić do ponownego uruchomienia lub zamknięcia węzłów. Aby uzyskać więcej informacji, zobacz Zarządzanie pulami węzłów systemowych w usłudze AKS.
Accelerated Networking
Wskazówki dotyczące najlepszych rozwiązań
Użyj przyspieszonej sieci, aby zapewnić mniejsze opóźnienia, mniejsze zakłócenia i mniejsze wykorzystanie procesora CPU na maszynach wirtualnych.
Przyspieszona sieć umożliwia wirtualizację we/wy pojedynczego katalogu głównego (SR-IOV) w obsługiwanych typach maszyn wirtualnych, co znacznie poprawia wydajność sieci.
Na poniższym diagramie pokazano, jak dwie maszyny wirtualne komunikują się z przyspieszoną siecią i bez:
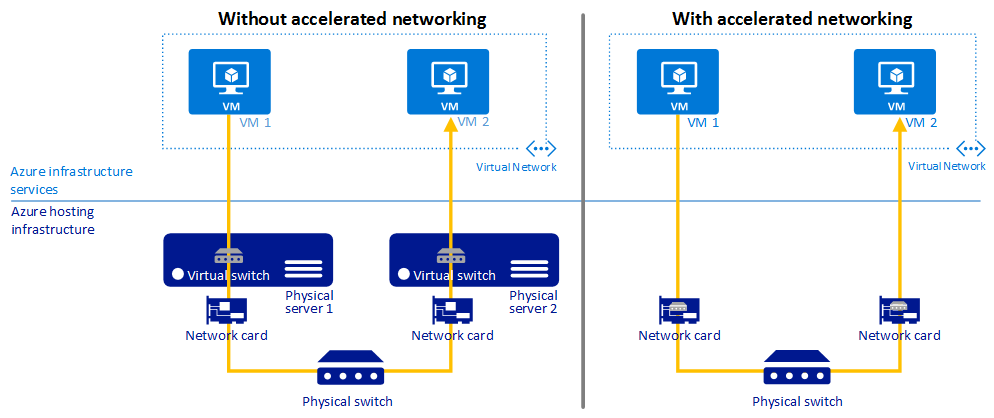
Aby uzyskać więcej informacji, zobacz Omówienie przyspieszonej sieci.
Wersje obrazów
Wskazówki dotyczące najlepszych rozwiązań
Obrazy nie powinny używać tagu
latest.
Tagi obrazu kontenera
Użycie tagu latest dla obrazów kontenerów może prowadzić do nieprzewidywalnego zachowania i utrudnia śledzenie wersji obrazu uruchomionej w klastrze. Te zagrożenia można zminimalizować, integrując i uruchamiając narzędzia do skanowania i korygowania w kontenerach w środowisku kompilacji i środowiska uruchomieniowego. Aby uzyskać więcej informacji, zobacz Najlepsze rozwiązania dotyczące zarządzania obrazami kontenerów w usłudze AKS.
Uaktualnienia obrazu węzła
Usługa AKS udostępnia wiele kanałów automatycznego uaktualniania dla uaktualnień obrazów systemu operacyjnego węzła. Tych kanałów można użyć do kontrolowania chronometrażu uaktualnień. Zalecamy dołączenie tych kanałów automatycznego uaktualniania, aby upewnić się, że węzły korzystają z najnowszych poprawek zabezpieczeń i aktualizacji. Aby uzyskać więcej informacji, zobacz Automatyczne uaktualnianie obrazów systemu operacyjnego węzła w usłudze AKS.
Warstwa Standardowa dla obciążeń produkcyjnych
Wskazówki dotyczące najlepszych rozwiązań
Użyj warstwy Standardowa dla obciążeń produktu, aby uzyskać większą niezawodność i zasoby klastra, obsługę maksymalnie 5000 węzłów w klastrze i domyślnie włączono umowę SLA czasu działania. Jeśli potrzebujesz ltS, rozważ użycie warstwy Premium.
Warstwa Standardowa dla usługi Azure Kubernetes Service (AKS) zapewnia wsparcie finansowe na poziomie 99,9% czasu pracy (SLA) dla obciążeń produkcyjnych. Warstwa Standardowa zapewnia również większą niezawodność i zasoby klastra, obsługę maksymalnie 5000 węzłów w klastrze i domyślnie włączono umowę SLA czasu pracy. Aby uzyskać więcej informacji, zobacz Warstwy cenowe do zarządzania klastrem usługi AKS.
Azure CNI na potrzeby dynamicznej alokacji adresów IP
Wskazówki dotyczące najlepszych rozwiązań
Konfigurowanie sieci CNI platformy Azure na potrzeby dynamicznej alokacji adresów IP w celu lepszego wykorzystania adresów IP i zapobiegania wyczerpaniu adresów IP dla klastrów usługi AKS.
Funkcja dynamicznej alokacji adresów IP w usłudze Azure CNI przydziela adresy IP zasobników z podsieci niezależnie od podsieci hostowania klastra usługi AKS i oferuje następujące korzyści:
- Lepsze wykorzystanie adresów IP: adresy IP są dynamicznie przydzielane do zasobników klastra z podsieci Zasobnika. Prowadzi to do lepszego wykorzystania adresów IP w klastrze w porównaniu z tradycyjnym rozwiązaniem CNI, które wykonuje statyczną alokację adresów IP dla każdego węzła.
- Skalowalne i elastyczne: podsieci węzłów i zasobników można skalować niezależnie. Pojedyncza podsieć zasobnika może być współużytkowana w wielu pulach węzłów klastra lub w wielu klastrach usługi AKS wdrożonych w tej samej sieci wirtualnej. Można również skonfigurować oddzielną podsieć zasobnika dla puli węzłów.
- Wysoka wydajność: ponieważ zasobnik ma przypisane adresy IP sieci wirtualnej, mają bezpośrednią łączność z innym zasobnikem klastra i zasobami w sieci wirtualnej. Rozwiązanie obsługuje bardzo duże klastry bez spadku wydajności.
- Oddzielne zasady sieci wirtualnej dla zasobników: ponieważ zasobniki mają oddzielną podsieć, można skonfigurować oddzielne zasady sieci wirtualnej dla nich, które różnią się od zasad węzłów. Umożliwia to wiele przydatnych scenariuszy, takich jak zezwolenie na łączność z Internetem tylko dla zasobników, a nie dla węzłów, naprawianie źródłowego adresu IP zasobnika w puli węzłów przy użyciu bramy translatora adresów sieciowych platformy Azure oraz filtrowanie ruchu między pulami węzłów za pomocą sieciowych grup zabezpieczeń.
- Zasady sieciowe platformy Kubernetes: zarówno zasady sieci platformy Azure, jak i Calico współpracują z tym rozwiązaniem.
Aby uzyskać więcej informacji, zobacz Konfigurowanie sieci CNI platformy Azure na potrzeby dynamicznej alokacji adresów IP i rozszerzonej obsługi podsieci.
Maszyny wirtualne jednostki SKU w wersji 5
Wskazówki dotyczące najlepszych rozwiązań
Użyj jednostek SKU maszyn wirtualnych w wersji 5 w celu zwiększenia wydajności podczas aktualizacji i po nich, mniejszego ogólnego wpływu i bardziej niezawodnego połączenia dla aplikacji.
W przypadku pul węzłów w usłudze AKS użyj maszyn wirtualnych jednostki SKU w wersji 5 z efemerycznych dysków systemu operacyjnego, aby zapewnić wystarczające zasoby obliczeniowe dla zasobników kube-system. Aby uzyskać więcej informacji, zobacz Najlepsze rozwiązania dotyczące wydajności i skalowania dużych obciążeń w usłudze AKS.
Nie używaj maszyn wirtualnych serii B
Wskazówki dotyczące najlepszych rozwiązań
Nie używaj maszyn wirtualnych serii B dla klastrów usługi AKS, ponieważ są one niskie i nie działają dobrze z usługą AKS.
Maszyny wirtualne serii B mają niską wydajność i nie działają dobrze z usługą AKS. Zamiast tego zalecamy używanie maszyn wirtualnych jednostki SKU w wersji 5.
Dyski w wersji Premium
Wskazówki dotyczące najlepszych rozwiązań
Użyj dysków w warstwie Premium, aby uzyskać dostępność na 99,9% na jednej maszynie wirtualnej.
Usługa Azure Premium Disks oferuje spójne opóźnienie dysku w milisekundach i duże operacje we/wy na sekundę oraz całe. Dyski w warstwie Premium zostały zaprojektowane w celu zapewnienia małych opóźnień, wysokiej wydajności i spójnej wydajności dysków dla maszyn wirtualnych.
Poniższy przykładowy manifest YAML przedstawia definicję klasy magazynu dla dysku w warstwie Premium:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: premium2-disk-sc
parameters:
cachingMode: None
skuName: PremiumV2_LRS
DiskIOPSReadWrite: "4000"
DiskMBpsReadWrite: "1000"
provisioner: disk.csi.azure.com
reclaimPolicy: Delete
volumeBindingMode: Immediate
allowVolumeExpansion: true
Aby uzyskać więcej informacji, zobacz Use Azure Premium SSD v2 disks on AKS (Używanie dysków SSD w warstwie Premium platformy Azure w wersji 2 w usłudze AKS).
Szczegółowe informacje o kontenerze
Wskazówki dotyczące najlepszych rozwiązań
Włącz usługę Container Insights, aby monitorować i diagnozować wydajność aplikacji konteneryzowanych.
Container Insights to funkcja usługi Azure Monitor, która zbiera i analizuje dzienniki kontenerów z usługi AKS. Zebrane dane można analizować przy użyciu kolekcji widoków i wstępnie utworzonych skoroszytów.
Monitorowanie usługi Container Insights w klastrze usługi AKS można włączyć przy użyciu różnych metod. W poniższym przykładzie pokazano, jak włączyć monitorowanie usługi Container Insights w istniejącym klastrze przy użyciu interfejsu wiersza polecenia platformy Azure:
az aks enable-addons -a monitoring --name myAKSCluster --resource-group myResourceGroup
Aby uzyskać więcej informacji, zobacz Włączanie monitorowania dla klastrów Kubernetes.
Azure Policy
Wskazówki dotyczące najlepszych rozwiązań
Stosowanie i wymuszanie wymagań dotyczących zabezpieczeń i zgodności dla klastrów usługi AKS przy użyciu usługi Azure Policy.
Za pomocą usługi Azure Policy można zastosować i wymusić wbudowane zasady zabezpieczeń w klastrach usługi AKS. Usługa Azure Policy pomaga wymuszać standardy organizacyjne i oceniać zgodność na dużą skalę. Po zainstalowaniu dodatku usługi Azure Policy dla usługi AKS można zastosować poszczególne definicje zasad lub grupy definicji zasad nazywanych inicjatywami do klastrów.
Aby uzyskać więcej informacji, zobacz Zabezpieczanie klastrów usługi AKS za pomocą usługi Azure Policy.
Następne kroki
Ten artykuł koncentruje się na najlepszych rozwiązaniach dotyczących wdrażania i niezawodności klastra dla klastrów usługi Azure Kubernetes Service (AKS). Aby uzyskać więcej najlepszych rozwiązań, zobacz następujące artykuły:

Azure Kubernetes Service