Problemen met trage SQL Server-prestaties oplossen die worden veroorzaakt door I/O-problemen
Van toepassing op: SQL Server
Dit artikel bevat richtlijnen voor wat I/O-problemen leiden tot trage SQL Server-prestaties en hoe u de problemen kunt oplossen.
Trage I/O-prestaties definiëren
Prestatiemeteritems worden gebruikt om trage I/O-prestaties te bepalen. Deze tellers meten hoe snel de I/O-subsysteemservices elke I/O-aanvraag gemiddeld in termen van kloktijd. De specifieke prestatiemeteritems die I/O-latentie in Windows meten, zijn Avg Disk sec/ Read, Avg. Disk sec/Writeen Avg. Disk sec/Transfer (cumulatief van zowel lees- als schrijfbewerkingen).
In SQL Server werken dingen op dezelfde manier. Doorgaans kijkt u of SQL Server eventuele I/O-knelpunten rapporteert die zijn gemeten in de kloktijd (milliseconden). SQL Server doet I/O-aanvragen naar het besturingssysteem door de Win32-functies zoals WriteFile(), ReadFile(), WriteFileGather()en ReadFileScatter(). Wanneer er een I/O-aanvraag wordt geplaatst, wordt de aanvraag door SQL Server keert en wordt de duur van de aanvraag gerapporteerd met behulp van wachttypen. SQL Server gebruikt wachttypen om I/O-wachttijden op verschillende plaatsen in het product aan te geven. De I/O-gerelateerde wachttijden zijn:
Als deze wachttijden consistent langer zijn dan 10-15 milliseconden, wordt I/O beschouwd als een knelpunt.
Notitie
Om context en perspectief te bieden, heeft Microsoft CSS in de wereld van het oplossen van problemen met SQL Server gevallen waargenomen waarbij een I/O-aanvraag één seconde duurde en zo hoog als 15 seconden per overdracht dergelijke I/O-systemen optimalisatie nodig heeft. Daarentegen heeft Microsoft CSS systemen gezien waarbij de doorvoer lager is dan één milliseconde/overdracht. Met de huidige SSD/NVMe-technologie, geadverteerde doorvoersnelheden variëren in tientallen microseconden per overdracht. Daarom is de afbeelding van 10-15 milliseconden/overdracht een zeer geschatte drempelwaarde die we hebben geselecteerd op basis van collectieve ervaring tussen Windows- en SQL Server-technici in de loop der jaren. Wanneer getallen deze geschatte drempelwaarde overschrijden, zien SQL Server-gebruikers meestal latentie in hun workloads en rapporteren ze. Uiteindelijk wordt de verwachte doorvoer van een I/O-subsysteem gedefinieerd door de fabrikant, het model, de configuratie, de workload en mogelijk meerdere andere factoren.
Methodologie
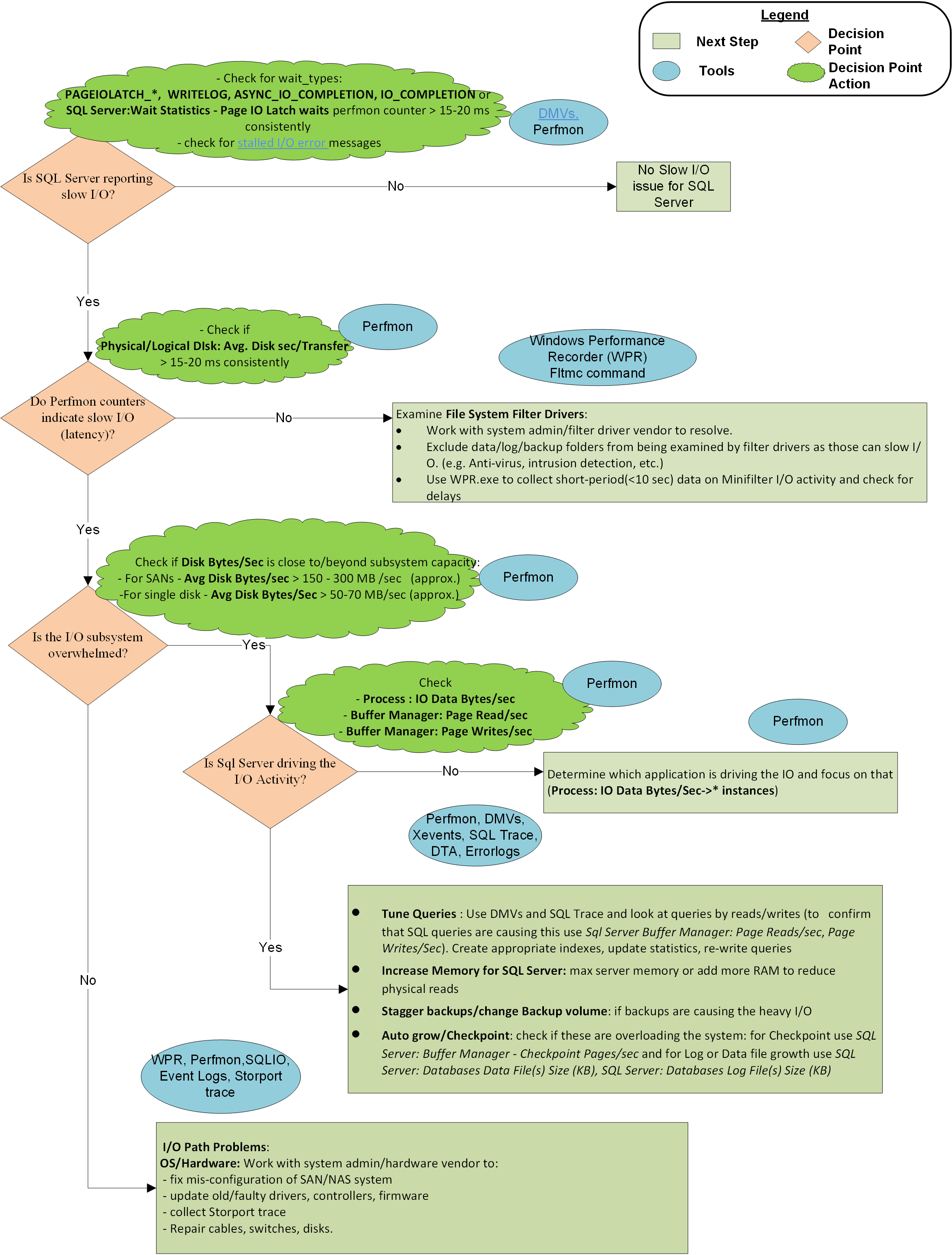
Een stroomdiagram aan het einde van dit artikel beschrijft de methodologie die Microsoft CSS gebruikt om trage I/O-problemen met SQL Server te benaderen. Het is geen volledige of exclusieve benadering, maar is nuttig gebleken bij het isoleren van het probleem en het oplossen ervan.
U kunt een van de volgende twee opties kiezen om het probleem op te lossen:
Optie 1: Voer de stappen rechtstreeks in een notebook uit via Azure Data Studio
Notitie
Voordat u dit notebook probeert te openen, moet u ervoor zorgen dat Azure Data Studio is geïnstalleerd op uw lokale computer. Als u deze wilt installeren, gaat u naar Meer informatie over het installeren van Azure Data Studio.
Optie 2: Volg de stappen handmatig
De methodologie wordt in deze stappen beschreven:
Stap 1: Rapporteert SQL Server trage I/O?
SQL Server kan I/O-latentie op verschillende manieren rapporteren:
- I/O-wachttypen
- DMV
sys.dm_io_virtual_file_stats - Foutenlogboek of toepassingslogboek
I/O-wachttypen
Bepaal of er I/O-latentie is gerapporteerd door SQL Server-wachttypen. De waarden, WRITELOGen ASYNC_IO_COMPLETION en de waarden PAGEIOLATCH_*van verschillende andere minder gangbare wachttypen moeten over het algemeen onder de 10-15 milliseconden per I/O-aanvraag blijven. Als deze waarden consistenter zijn, bestaat er een I/O-prestatieprobleem en is verder onderzoek vereist. Met de volgende query kunt u deze diagnostische gegevens op uw systeem verzamelen:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
for ([int]$i = 0; $i -lt 100; $i++)
{
sqlcmd -E -S $sqlserver_instance -Q "SELECT r.session_id, r.wait_type, r.wait_time as wait_time_ms`
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s `
ON r.session_id = s.session_id `
WHERE wait_type in ('PAGEIOLATCH_SH', 'PAGEIOLATCH_EX', 'WRITELOG', `
'IO_COMPLETION', 'ASYNC_IO_COMPLETION', 'BACKUPIO')`
AND is_user_process = 1"
Start-Sleep -s 2
}
Bestandsstatistieken in sys.dm_io_virtual_file_stats
Als u de latentie op databasebestandsniveau wilt weergeven zoals gerapporteerd in SQL Server, voert u de volgende query uit:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT LEFT(mf.physical_name,100), `
ReadLatency = CASE WHEN num_of_reads = 0 THEN 0 ELSE (io_stall_read_ms / num_of_reads) END, `
WriteLatency = CASE WHEN num_of_writes = 0 THEN 0 ELSE (io_stall_write_ms / num_of_writes) END, `
AvgLatency = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE (io_stall / (num_of_reads + num_of_writes)) END,`
LatencyAssessment = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 'No data' ELSE `
CASE WHEN (io_stall / (num_of_reads + num_of_writes)) < 2 THEN 'Excellent' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 2 AND 5 THEN 'Very good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 6 AND 15 THEN 'Good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 16 AND 100 THEN 'Poor' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 100 AND 500 THEN 'Bad' `
ELSE 'Deplorable' END END, `
[Avg KBs/Transfer] = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE ((([num_of_bytes_read] + [num_of_bytes_written]) / (num_of_reads + num_of_writes)) / 1024) END, `
LEFT (mf.physical_name, 2) AS Volume, `
LEFT(DB_NAME (vfs.database_id),32) AS [Database Name]`
FROM sys.dm_io_virtual_file_stats (NULL,NULL) AS vfs `
JOIN sys.master_files AS mf ON vfs.database_id = mf.database_id `
AND vfs.file_id = mf.file_id `
ORDER BY AvgLatency DESC"
Bekijk de AvgLatency en LatencyAssessment kolommen om inzicht te hebben in de latentiedetails.
Fout 833 gerapporteerd in foutenlogboek of toepassingslogboek
In sommige gevallen ziet u mogelijk fout 833 SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database [%ls] (%d) in het foutenlogboek. U kunt foutenlogboeken van SQL Server op uw systeem controleren door de volgende PowerShell-opdracht uit te voeren:
Get-ChildItem -Path "c:\program files\microsoft sql server\mssql*" -Recurse -Include Errorlog |
Select-String "occurrence(s) of I/O requests taking longer than Longer than 15 secs"
Zie ook de sectie MSSQLSERVER_833 voor meer informatie over deze fout.
Stap 2: Geven prestatiemeteritems de I/O-latentie aan?
Als SQL Server I/O-latentie rapporteert, raadpleegt u de prestatiemeteritems van het besturingssysteem. U kunt bepalen of er een I/O-probleem is door de latentiemeteritem Avg Disk Sec/Transferte onderzoeken. Het volgende codefragment geeft één manier aan om deze informatie te verzamelen via PowerShell. Het verzamelt tellers op alle schijfvolumes: '_total'. Ga naar een specifiek stationvolume (bijvoorbeeld 'D:'). Als u wilt zoeken naar welke volumes uw databasebestanden worden gehost, voert u de volgende query uit in uw SQL Server:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT DISTINCT LEFT(volume_mount_point, 32) AS volume_mount_point `
FROM sys.master_files f `
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) vs"
Verzamel Avg Disk Sec/Transfer metrische gegevens over uw gewenste volume:
clear
$cntr = 0
# replace with your server name, unless local computer
$serverName = $env:COMPUTERNAME
# replace with your volume name - C: , D:, etc
$volumeName = "_total"
$Counters = @(("\\$serverName" +"\LogicalDisk($volumeName)\Avg. disk sec/transfer"))
$disksectransfer = Get-Counter -Counter $Counters -MaxSamples 1
$avg = $($disksectransfer.CounterSamples | Select-Object CookedValue).CookedValue
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 30 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 5))
turn = $cntr = $cntr +1
running_avg = [Math]::Round(($avg = (($_.CookedValue + $avg) / 2)), 5)
} | Format-Table
}
}
write-host "Final_Running_Average: $([Math]::Round( $avg, 5)) sec/transfer`n"
if ($avg -gt 0.01)
{
Write-Host "There ARE indications of slow I/O performance on your system"
}
else
{
Write-Host "There is NO indication of slow I/O performance on your system"
}
Als de waarden van deze teller consistent hoger zijn dan 10-15 milliseconden, moet u het probleem verder bekijken. Af en toe tellen pieken niet in de meeste gevallen, maar zorg ervoor dat u de duur van een piek controleert. Als de piek één minuut of meer duurde, is het meer van een plateau dan een piek.
Als de prestatiemeteritems geen latentie rapporteren, maar SQL Server dat wel doet, is het probleem tussen SQL Server en Partition Manager, dat wil gezegd filterstuurprogramma's. Partition Manager is een I/O-laag waarin het besturingssysteem prestatiemeteritems verzamelt. Als u de latentie wilt oplossen, moet u de juiste uitsluitingen van filterstuurprogramma's garanderen en problemen met het filterstuurprogramma oplossen. Filterstuurprogramma's worden gebruikt door programma's zoals antivirussoftware, back-upoplossingen, versleuteling, compressie, enzovoort. U kunt deze opdracht gebruiken om filterstuurprogramma's op de systemen en de volumes waaraan ze zijn gekoppeld weer te geven. Vervolgens kunt u de stuurprogrammanamen en softwareleveranciers opzoeken in het artikel Toegewezen filterhoogten .
fltmc instances
Zie Antivirussoftware kiezen die moet worden uitgevoerd op computers waarop SQL Server wordt uitgevoerd voor meer informatie.
Vermijd het gebruik van EFS (Encrypting File System) en bestandssysteemcompressie omdat ze asynchrone I/O synchroon en daarom langzamer veroorzaken. Zie voor meer informatie de Asynchrone schijf-I/O wordt als synchroon weergegeven in het Windows-artikel .
Stap 3: Is het I/O-subsysteem overbelast dan de capaciteit?
Als SQL Server en het besturingssysteem aangeven dat het I/O-subsysteem traag is, controleert u of het systeem wordt overbelast buiten de capaciteit. U kunt de capaciteit controleren door te kijken naar I/O-tellers Disk Bytes/Sec, Disk Read Bytes/Secof Disk Write Bytes/Sec. Neem contact op met uw systeembeheerder of hardwareleverancier voor de verwachte doorvoerspecificaties voor uw SAN (of een ander I/O-subsysteem). U kunt bijvoorbeeld maximaal 200 MB per seconde I/O pushen via een toegewezen HBA-kaart van 2 GB per seconde of 2 GB per seconde toegewezen poort op een SAN-switch. De verwachte doorvoercapaciteit die door een hardwarefabrikant is gedefinieerd, bepaalt hoe u vanaf hier verder gaat.
clear
$serverName = $env:COMPUTERNAME
$Counters = @(
("\\$serverName" +"\PhysicalDisk(*)\Disk Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Read Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Write Bytes/sec")
)
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 20 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 3)) }
}
}
Stap 4: Wordt SQL Server gebruikt om de zware I/O-activiteit te stimuleren?
Als het I/O-subsysteem buiten de capaciteit wordt overweldigd, moet u erachter komen of SQL Server de verantwoordelijkheid is door te kijken Buffer Manager: Page Reads/Sec naar (meest voorkomende verantwoordelijke) en Page Writes/Sec (veel minder vaak) voor het specifieke exemplaar. Als SQL Server het belangrijkste I/O-stuurprogramma is en het I/O-volume verder gaat dan wat het systeem kan verwerken, moet u contact opnemen met de toepassingsontwikkelingsteams of de leverancier van de toepassing om:
- Stem query's af, bijvoorbeeld: betere indexen, updatestatistieken, herschrijfquery's en ontwerp de database opnieuw.
- Verhoog het maximale servergeheugen of voeg meer RAM-geheugen toe aan het systeem. Meer RAM-geheugen slaat meer gegevens of indexpagina's op zonder regelmatig opnieuw te lezen van schijf, waardoor I/O-activiteit wordt verminderd. Meer geheugen kan ook verminderen
Lazy Writes/sec, die worden aangestuurd door luie schrijver wordt leeggemaakt wanneer er regelmatig meer databasepagina's moeten worden opgeslagen in het beperkte geheugen. - Als u merkt dat schrijfbewerkingen van pagina's de bron zijn van zware I/O-activiteit, controleert u
Buffer Manager: Checkpoint pages/secof deze te wijten is aan enorme pagina's die nodig zijn om te voldoen aan de vereisten voor de configuratie van het herstelinterval. U kunt indirecte controlepunten gebruiken om I/O in de loop van de tijd te gelijkmatiger te maken of de I/O-doorvoer van hardware te verhogen.
Oorzaken
Over het algemeen zijn de volgende problemen de belangrijkste redenen waarom SQL Server-query's last hebben van I/O-latentie:
Hardwareproblemen:
Een ONJUISTE SAN-configuratie (switch, kabels, HBA, opslag)
I/O-capaciteit overschreden (onevenwichtig in het hele SAN-netwerk, niet alleen back-endopslag)
Problemen met stuurprogramma's of firmware
Hardwareleveranciers en/of systeembeheerders moeten in deze fase betrokken zijn.
Queryproblemen: SQL Server verzadiging van schijfvolumes met I/O-aanvragen en pusht het I/O-subsysteem buiten de capaciteit, waardoor I/O-overdrachtssnelheden hoog zijn. In dit geval is de oplossing om de query's te vinden die een groot aantal logische leesbewerkingen (of schrijfbewerkingen) veroorzaken en deze query's zo afstemmen dat de juiste indexen voor schijf-I/O worden gebruikt, is de eerste stap om dat te doen. Zorg er ook voor dat statistieken worden bijgewerkt wanneer ze de queryoptimalisatie voorzien van voldoende informatie om het beste plan te kiezen. Ook kan onjuist databaseontwerp en queryontwerp leiden tot een toename van I/O-problemen. Daarom kan het opnieuw ontwerpen van query's en soms tabellen helpen met verbeterde I/O.
Filterstuurprogramma's: de I/O-reactie van SQL Server kan ernstig worden beïnvloed als stuurprogramma's voor bestandssysteemfilters intensief I/O-verkeer verwerken. De juiste bestandsuitsluitingen van antivirusscans en het juiste ontwerp van filterstuurprogramma's door softwareleveranciers worden aanbevolen om invloed op I/O-prestaties te voorkomen.
Andere toepassingen: Een andere toepassing op dezelfde computer met SQL Server kan het I/O-pad overbelasten met overmatige lees- of schrijfaanvragen. Deze situatie kan het I/O-subsysteem buiten de capaciteitslimieten duwen en I/O-traagheid veroorzaken voor SQL Server. Identificeer de toepassing en stem deze af of verplaats deze ergens anders om de impact op de I/O-stack te elimineren.
Grafische weergave van de methodologie
Informatie over I/O-gerelateerde wachttypen
Hier volgen beschrijvingen van de veelvoorkomende wachttypen die in SQL Server worden waargenomen wanneer I/O-problemen met schijf worden gerapporteerd.
PAGEIOLATCH_EX
Treedt op wanneer een taak wacht op een vergrendeling voor een gegevens- of indexpagina (buffer) in een I/O-aanvraag. De vergrendelingsaanvraag bevindt zich in de modus Exclusief. Er wordt een exclusieve modus gebruikt wanneer de buffer naar de schijf wordt geschreven. Lange wachttijden kunnen duiden op problemen met het schijfsubsysteem.
PAGEIOLATCH_SH
Treedt op wanneer een taak wacht op een vergrendeling voor een gegevens- of indexpagina (buffer) in een I/O-aanvraag. De vergrendelingsaanvraag bevindt zich in de modus Gedeeld. De modus Gedeeld wordt gebruikt wanneer de buffer wordt gelezen van de schijf. Lange wachttijden kunnen duiden op problemen met het schijfsubsysteem.
PAGEIOLATCH_UP
Treedt op wanneer een taak wacht op een vergrendeling voor een buffer in een I/O-aanvraag. De vergrendelingsaanvraag bevindt zich in de updatemodus. Lange wachttijden kunnen duiden op problemen met het schijfsubsysteem.
WRITELOG
Treedt op wanneer een taak wacht totdat een transactielogboek is leeggemaakt. Er wordt leeggemaakt wanneer logbeheer de tijdelijke inhoud naar de schijf schrijft. Veelvoorkomende bewerkingen die ertoe leiden dat logboeken worden leeggemaakt, zijn transactiedoorvoeringen en controlepunten.
Veelvoorkomende redenen voor lange wachttijden WRITELOG zijn:
Latentie van transactielogboekschijf: dit is de meest voorkomende oorzaak van
WRITELOGwachttijden. Over het algemeen is het raadzaam om de gegevens en logboekbestanden op afzonderlijke volumes te bewaren. Schrijfbewerkingen voor transactielogboeken zijn sequentiële schrijfbewerkingen tijdens het lezen of schrijven van gegevens uit een gegevensbestand, is willekeurig. Het combineren van gegevens en logboekbestanden op één schijfvolume (met name conventionele draaiende schijfstations) veroorzaakt overmatige verplaatsing van de schijfkop.Te veel VLF's: te veel virtuele logboekbestanden (VLF's) kunnen wachttijden veroorzaken
WRITELOG. Te veel VLF's kunnen andere soorten problemen veroorzaken, zoals lang herstel.Te veel kleine transacties: hoewel grote transacties tot blokkeren kunnen leiden, kunnen te veel kleine transacties leiden tot een andere set problemen. Als u een transactie niet expliciet start, resulteert een invoeg-, verwijder- of updatebewerking in een transactie (deze automatische transactie wordt genoemd). Als u 1000 invoegingen in een lus uitvoert, worden er 1000 transacties gegenereerd. Elke transactie in dit voorbeeld moet worden doorgevoerd, wat resulteert in een leeggemaakt transactielogboek en 1000 transacties worden leeggemaakt. Groepeer indien mogelijk afzonderlijke updates, verwijder of voeg deze in een grotere transactie in om het leegmaken van transactielogboeken te verminderen en de prestaties te verbeteren. Deze bewerking kan leiden tot minder
WRITELOGwachttijden.Planningsproblemen zorgen ervoor dat Logboekschrijver-threads niet snel genoeg worden gepland: vóór SQL Server 2016 heeft één Log Writer-thread alle logboekschrijfbewerkingen uitgevoerd. Als er problemen zijn met het plannen van threads (bijvoorbeeld een hoog CPU-gebruik), kunnen zowel de Thread voor Logboekschrijver als logboeken worden vertraagd. In SQL Server 2016 zijn maximaal vier Log Writer-threads toegevoegd om de doorvoer voor het schrijven van logboeken te verhogen. Zie SQL 2016: het wordt gewoon sneller uitgevoerd: meerdere werkrollen voor logboekschrijvers. In SQL Server 2019 zijn maximaal acht Log Writer-threads toegevoegd, waardoor de doorvoer nog meer wordt verbeterd. In SQL Server 2019 kan elke reguliere werkrolthread ook rechtstreeks logboekschrijfbewerkingen uitvoeren in plaats van te plaatsen in de Logboekschrijver-thread. Met deze verbeteringen
WRITELOGworden wachttijden zelden geactiveerd door planningsproblemen.
ASYNC_IO_COMPLETION
Treedt op wanneer enkele van de volgende I/O-activiteiten plaatsvinden:
- De Provider voor bulksgewijs invoegen ('Bulk invoegen') gebruikt dit wachttype bij het uitvoeren van I/O.
- Het lezen van het bestand Ongedaan maken in LogShipping en het omsturen van Async I/O voor logboekverzending.
- De werkelijke gegevens uit de gegevensbestanden lezen tijdens een gegevensback-up.
IO_COMPLETION
Treedt op terwijl wordt gewacht tot I/O-bewerkingen zijn voltooid. Dit wachttype omvat over het algemeen I/Os die niet zijn gerelateerd aan gegevenspagina's (buffers). Voorbeelden zijn:
- Het lezen en schrijven van sorteer-/hashresultaten van/naar schijf tijdens een overloop (controleer de prestaties van tempdb-opslag ).
- Het lezen en schrijven van gretige spools naar schijf (controleer tempdb-opslag ).
- Logboekblokken lezen uit het transactielogboek (tijdens een bewerking die ervoor zorgt dat het logboek wordt gelezen vanaf de schijf, bijvoorbeeld herstel).
- Een pagina lezen vanaf schijf wanneer de database nog niet is ingesteld.
- Pagina's kopiëren naar een momentopname van een database (Copy-on-Write).
- Databasebestand en bestandsonderdruking sluiten.
BACKUPIO
Treedt op wanneer een back-uptaak wacht op gegevens of wacht tot een buffer gegevens opslaat. Dit type is niet gebruikelijk, behalve wanneer een taak wacht op een tapekoppeling.