Problemen met een query oplossen die een aanzienlijk prestatieverschil tussen twee servers laat zien
Van toepassing op: SQL Server
Dit artikel bevat stappen voor probleemoplossing voor een prestatieprobleem waarbij een query langzamer wordt uitgevoerd op de ene server dan op een andere server.
Symptomen
Stel dat er twee servers zijn waarop SQL Server is geïnstalleerd. Een van de SQL Server-exemplaren bevat een kopie van een database in het andere SQL Server-exemplaar. Wanneer u een query uitvoert op de databases op beide servers, wordt de query langzamer uitgevoerd op de ene server dan de andere.
Met de volgende stappen kunt u dit probleem oplossen.
Stap 1: Bepalen of het een veelvoorkomend probleem is met meerdere query's
Gebruik een van de volgende twee methoden om de prestaties voor twee of meer query's op de twee servers te vergelijken:
Test de query's op beide servers handmatig:
- Kies verschillende query's voor het testen met prioriteit voor query's die:
- Aanzienlijk sneller op de ene server dan op de andere.
- Belangrijk voor de gebruiker/toepassing.
- Vaak uitgevoerd of ontworpen om het probleem op aanvraag te reproduceren.
- Voldoende lang voor het vastleggen van gegevens (bijvoorbeeld in plaats van een query van 5 milliseconden, kiest u een query van 10 seconden).
- Voer de query's uit op de twee servers.
- Vergelijk de verstreken tijd (duur) op twee servers voor elke query.
- Kies verschillende query's voor het testen met prioriteit voor query's die:
Analyseer prestatiegegevens met SQL Nexus.
- Verzamel PSSDiag/SQLdiag - of SQL LogScout-gegevens voor de query's op de twee servers.
- Importeer de verzamelde gegevensbestanden met SQL Nexus en vergelijk de query's van de twee servers. Zie Prestatievergelijking tussen twee logboekverzamelingen (bijvoorbeeld Traag en Snel) voor meer informatie.
Scenario 1: Slechts één query wordt anders uitgevoerd op de twee servers
Als slechts één query anders wordt uitgevoerd, is het probleem waarschijnlijk specifieker voor de afzonderlijke query in plaats van voor de omgeving. Ga in dit geval naar stap 2: Gegevens verzamelen en het type prestatieprobleem bepalen.
Scenario 2: Meerdere query's worden anders uitgevoerd op de twee servers
Als meerdere query's langzamer worden uitgevoerd op de ene server dan de andere, is de meest waarschijnlijke oorzaak de verschillen in de server- of gegevensomgeving. Ga naar Omgevingsverschillen vaststellen en kijk of de vergelijking tussen de twee servers geldig is.
Stap 2: Gegevens verzamelen en het type prestatieprobleem bepalen
Verstreken tijd, CPU-tijd en logische leesbewerkingen verzamelen
Als u verstreken tijd en CPU-tijd van de query op beide servers wilt verzamelen, gebruikt u een van de volgende methoden die het beste bij uw situatie passen:
Controleer total_elapsed_time en cpu_time kolommen in sys.dm_exec_requests voor het uitvoeren van instructies. Voer de volgende query uit om de gegevens op te halen:
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;Voor eerdere uitvoeringen van de query controleert u last_elapsed_time en last_worker_time kolommen in sys.dm_exec_query_stats. Voer de volgende query uit om de gegevens op te halen:
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCNotitie
Als
avg_wait_timeeen negatieve waarde wordt weergegeven, is dit een parallelle query.Als u de query op aanvraag kunt uitvoeren in SQL Server Management Studio (SSMS) of Azure Data Studio, voert u deze uit met SET STATISTICS TIME
ONen SET STATISTICS IOON.SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFFVervolgens ziet u in Berichten de CPU-tijd, verstreken tijd en logische leesbewerkingen als volgt:
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.Als u een queryplan kunt verzamelen, controleert u de gegevens uit de eigenschappen van het uitvoeringsplan.
Voer de query uit met Het werkelijke uitvoeringsplan opnemen op.
Selecteer de meest linkse operator in het uitvoeringsplan.
Vouw vanuit Eigenschappen de eigenschap QueryTimeStats uit.
Controleer ElapsedTime en CpuTime.
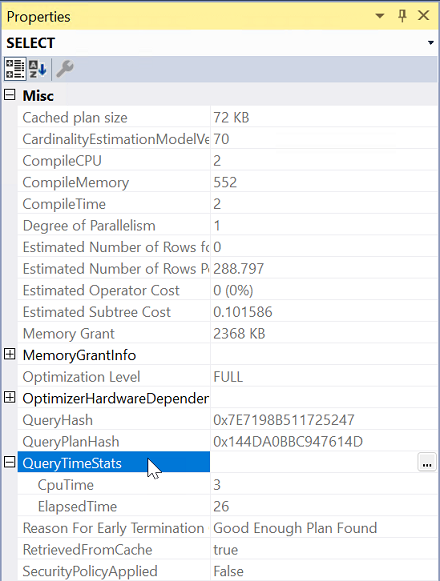
Vergelijk de verstreken tijd en CPU-tijd van de query om het probleemtype voor beide servers te bepalen.
Type 1: CPU-gebonden (runner)
Als de CPU-tijd bijna is, gelijk is aan of hoger is dan de verstreken tijd, kunt u deze behandelen als een CPU-afhankelijke query. Als de verstreken tijd bijvoorbeeld 3000 milliseconden (ms) is en de CPU-tijd 2900 ms is, betekent dit dat de meeste verstreken tijd wordt besteed aan de CPU. Vervolgens kunnen we zeggen dat het een CPU-afhankelijke query is.
Voorbeelden van actieve (CPU-gebonden) query's:
| Verstreken tijd (ms) | CPU-tijd (ms) | Leesbewerkingen (logisch) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1000 | 20 |
Logische leesbewerkingen : het lezen van gegevens/indexpagina's in de cache zijn het meest de stuurprogramma's voor CPU-gebruik in SQL Server. Er kunnen scenario's zijn waarin CPU-gebruik afkomstig is van andere bronnen: een while-lus (in T-SQL of andere code, zoals XProcs- of SQL CRL-objecten). Het tweede voorbeeld in de tabel illustreert een dergelijk scenario, waarbij het merendeel van de CPU niet van leesbewerkingen afkomstig is.
Notitie
Als de CPU-tijd groter is dan de duur, geeft dit aan dat er een parallelle query wordt uitgevoerd; meerdere threads gebruiken tegelijkertijd de CPU. Zie Parallelle query's - runner of ober voor meer informatie.
Type 2: Wachten op een knelpunt (ober)
Een query wacht op een knelpunt als de verstreken tijd aanzienlijk groter is dan de CPU-tijd. De verstreken tijd omvat de tijd die de query uitvoert op de CPU (CPU-tijd) en de tijd die wacht tot een resource wordt vrijgegeven (wachttijd). Als de verstreken tijd bijvoorbeeld 2000 ms is en de CPU-tijd 300 ms is, is de wachttijd 1700 ms (2000 - 300 = 1700). Zie Typen wachttijden voor meer informatie.
Voorbeelden van wachtende query's:
| Verstreken tijd (ms) | CPU-tijd (ms) | Leesbewerkingen (logisch) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10.080 | 700 | 80.000 |
Parallelle query's - runner of ober
Parallelle query's kunnen meer CPU-tijd gebruiken dan de totale duur. Het doel van parallellisme is om meerdere threads toe te staan om delen van een query tegelijkertijd uit te voeren. In één seconde van de kloktijd kan een query acht seconden CPU-tijd gebruiken door acht parallelle threads uit te voeren. Daarom wordt het lastig om een CPU-gebonden of een wachtquery te bepalen op basis van het verstreken tijds- en CPU-tijdsverschil. Als algemene regel volgt u echter de principes die in de bovenstaande twee secties worden vermeld. De samenvatting is:
- Als de verstreken tijd veel groter is dan de CPU-tijd, kunt u een ober overwegen.
- Als de CPU-tijd veel groter is dan de verstreken tijd, overweeg dan een hardloper.
Voorbeelden van parallelle query's:
| Verstreken tijd (ms) | CPU-tijd (ms) | Leesbewerkingen (logisch) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1500000 |
Stap 3: Vergelijk gegevens van beide servers, zoek het scenario uit en los het probleem op
Stel dat er twee computers zijn met de naam Server1 en Server2. En de query wordt langzamer uitgevoerd op Server1 dan op Server2. Vergelijk de tijden van beide servers en volg vervolgens de acties van het scenario dat het beste overeenkomt met die van u uit de volgende secties.
Scenario 1: De query op Server1 gebruikt meer CPU-tijd en de logische leesbewerkingen zijn hoger op Server1 dan op Server2
Als de CPU-tijd op Server1 veel groter is dan op Server2 en de verstreken tijd overeenkomt met de CPU-tijd nauw op beide servers, zijn er geen grote wachttijden of knelpunten. De toename van de CPU-tijd op Server1 wordt waarschijnlijk veroorzaakt door een toename van logische leesbewerkingen. Een belangrijke wijziging in logische leesbewerkingen duidt meestal op een verschil in queryplannen. Bijvoorbeeld:
| Server | Verstreken tijd (ms) | CPU-tijd (ms) | Leesbewerkingen (logisch) |
|---|---|---|---|
| Server1 | 3100 | 3000 | 300000 |
| Server2 | 1100 | 1000 | 90200 |
Actie: Uitvoeringsplannen en omgevingen controleren
- Vergelijk uitvoeringsplannen van de query op beide servers. Gebruik hiervoor een van de twee methoden:
- Vergelijk uitvoeringsplannen visueel. Zie Een werkelijk uitvoeringsplan weergeven voor meer informatie.
- Sla de uitvoeringsplannen op en vergelijk ze met behulp van de functie SQL Server Management Studio Plan Comparison.
- Omgevingen vergelijken. Verschillende omgevingen kunnen leiden tot queryplanverschillen of directe verschillen in CPU-gebruik. Omgevingen omvatten serverversies, database- of serverconfiguratie-instellingen, traceringsvlagmen, CPU-telling of kloksnelheid en virtuele machine versus fysieke machine. Zie Verschillen in queryplan diagnosticeren voor meer informatie.
Scenario 2: De query is een ober op Server1, maar niet op Server2
Als de CPU-tijden voor de query op beide servers vergelijkbaar zijn, maar de verstreken tijd op Server1 veel groter is dan op Server2, besteedt de query op Server1 veel langer aan het wachten op een knelpunt. Bijvoorbeeld:
| Server | Verstreken tijd (ms) | CPU-tijd (ms) | Leesbewerkingen (logisch) |
|---|---|---|---|
| Server1 | 4500 | 1000 | 90200 |
| Server2 | 1100 | 1000 | 90200 |
- Wachttijd op Server1: 4500 - 1000 = 3500 ms
- Wachttijd op Server2: 1100 - 1000 = 100 ms
Actie: Wachttypen controleren op Server1
Het knelpunt op Server1 identificeren en elimineren. Voorbeelden van wachttijden zijn blokkerend (vergrendelingswachttijden), vergrendelingswachttijden, schijf-I/O-wachttijden, netwerkwachttijden en geheugenwachttijden. Als u veelvoorkomende knelpunten wilt oplossen, gaat u verder met het diagnosticeren van wachttijden of knelpunten.
Scenario 3: De query's op beide servers zijn obers, maar de wachttypen of -tijden verschillen
Bijvoorbeeld:
| Server | Verstreken tijd (ms) | CPU-tijd (ms) | Leesbewerkingen (logisch) |
|---|---|---|---|
| Server1 | 8000 | 1000 | 90200 |
| Server2 | 3000 | 1000 | 90200 |
- Wachttijd op Server1: 8000 - 1000 = 7000 ms
- Wachttijd op Server2: 3000 - 1000 = 2000 ms
In dit geval zijn de CPU-tijden vergelijkbaar op beide servers, wat aangeeft dat queryplannen waarschijnlijk hetzelfde zijn. De query's worden op beide servers even goed uitgevoerd als ze niet wachten op de knelpunten. De verschillen in duur zijn dus afkomstig van de verschillende hoeveelheden wachttijden. De query wacht bijvoorbeeld op vergrendelingen op Server1 gedurende 7000 ms terwijl deze wacht op I/O op Server2 voor 2000 ms.
Actie: Wachttypen controleren op beide servers
Los elk knelpunt afzonderlijk op elke server op en versnel de uitvoeringen op beide servers. Het oplossen van dit probleem is arbeidsintensief omdat u knelpunten op beide servers moet elimineren en de prestaties vergelijkbaar moet maken. Als u veelvoorkomende knelpunten wilt oplossen, gaat u verder met het diagnosticeren van wachttijden of knelpunten.
Scenario 4: De query op Server1 gebruikt meer CPU-tijd dan op Server2, maar de logische leesbewerkingen zijn gesloten
Bijvoorbeeld:
| Server | Verstreken tijd (ms) | CPU-tijd (ms) | Leesbewerkingen (logisch) |
|---|---|---|---|
| Server1 | 3000 | 3000 | 90200 |
| Server2 | 1000 | 1000 | 90200 |
Als de gegevens overeenkomen met de volgende voorwaarden:
- De CPU-tijd op Server1 is veel groter dan op Server2.
- De verstreken tijd komt nauw overeen met de CPU-tijd op elke server, wat aangeeft dat er geen wachttijden zijn.
- De logische leesbewerkingen, meestal het hoogste stuurprogramma van CPU-tijd, zijn vergelijkbaar op beide servers.
Vervolgens is de extra CPU-tijd afkomstig van enkele andere CPU-gebonden activiteiten. Dit scenario is het zeldzaamst van alle scenario's.
Oorzaken: Tracering, UDF's en CLR-integratie
Dit probleem kan worden veroorzaakt door:
- XEvents/SQL Server-tracering, met name met filteren op tekstkolommen (databasenaam, aanmeldingsnaam, querytekst, enzovoort). Als tracering is ingeschakeld op de ene server, maar niet op de andere, kan dit de reden zijn voor het verschil.
- Door de gebruiker gedefinieerde functies (UDF's) of andere T-SQL-code waarmee CPU-afhankelijke bewerkingen worden uitgevoerd. Dit is doorgaans de oorzaak wanneer andere omstandigheden verschillen op Server1 en Server2, zoals gegevensgrootte, CPU-kloksnelheid of energiebeheerschema.
- SQL Server CLR-integratie of uitgebreide opgeslagen procedures (XPs) die CPU mogelijk stimuleren, maar geen logische leesbewerkingen uitvoeren. Verschillen in de DLL's kunnen leiden tot verschillende CPU-tijden.
- Verschil in SQL Server-functionaliteit die afhankelijk is van de CPU (bijvoorbeeld code voor het bewerken van tekenreeksen).
Actie: Traceringen en query's controleren
Controleer de traceringen op beide servers op het volgende:
- Als er een tracering is ingeschakeld op Server1, maar niet op Server2.
- Als een tracering is ingeschakeld, schakelt u de tracering uit en voert u de query opnieuw uit op Server1.
- Als de query deze keer sneller wordt uitgevoerd, schakelt u de tracering in, maar verwijdert u er tekstfilters uit, indien aanwezig.
Controleer of de query UDF's gebruikt die tekenreeksbewerkingen uitvoeren of uitgebreide verwerking uitvoeren op gegevenskolommen in de
SELECTlijst.Controleer of de query lussen, functie-recursies of nestings bevat.
Omgevingsverschillen vaststellen
Controleer de volgende vragen en bepaal of de vergelijking tussen de twee servers geldig is.
Zijn de twee SQL Server-exemplaren dezelfde versie of build?
Als dat niet het probleem is, kunnen er enkele oplossingen zijn die de verschillen hebben veroorzaakt. Voer de volgende query uit om versiegegevens op beide servers op te halen:
SELECT @@VERSIONIs de hoeveelheid fysiek geheugen vergelijkbaar op beide servers?
Als de ene server 64 GB geheugen heeft terwijl de andere 256 GB geheugen heeft, is dat een aanzienlijk verschil. Omdat er meer geheugen beschikbaar is voor het opslaan van gegevens/indexpagina's en queryplannen, kan de query anders worden geoptimaliseerd op basis van de beschikbaarheid van hardwareresources.
Zijn hardwareconfiguraties met betrekking tot CPU vergelijkbaar op beide servers? Bijvoorbeeld:
Het aantal CPU's varieert tussen machines (24 CPU's op één computer versus 96 CPU's op de andere).
Energiebeheerschema's: evenwichtig versus hoge prestaties.
Virtuele machine (VM) versus fysieke (bare-metal) machine.
Hyper-V versus VMware: verschil in configuratie.
Kloksnelheidsverschil (lagere kloksnelheid versus hogere kloksnelheid). Zo kan 2 GHz versus 3,5 GHz een verschil maken. Voer de volgende PowerShell-opdracht uit om de kloksnelheid op een server op te halen:
Get-CimInstance Win32_Processor | Select-Object -Expand MaxClockSpeed
Gebruik een van de volgende twee manieren om de CPU-snelheid van de servers te testen. Als ze geen vergelijkbare resultaten opleveren, ligt het probleem buiten SQL Server. Het kan een verschil in energiebeheerschema zijn, minder CPU's, VM-softwareprobleem of kloksnelheidsverschil.
Voer het volgende PowerShell-script uit op beide servers en vergelijk de uitvoer.
$bf = [System.DateTime]::Now for ($i = 0; $i -le 20000000; $i++) {} $af = [System.DateTime]::Now Write-Host ($af - $bf).Milliseconds " milliseconds" Write-Host ($af - $bf).Seconds " Seconds"Voer de volgende Transact-SQL-code uit op beide servers en vergelijk de uitvoer.
SET NOCOUNT ON DECLARE @spins INT = 0 DECLARE @start_time DATETIME = GETDATE(), @time_millisecond INT WHILE (@spins < 20000000) BEGIN SET @spins = @spins +1 END SELECT @time_millisecond = DATEDIFF(millisecond, @start_time, getdate()) SELECT @spins Spins, @time_millisecond Time_ms, @spins / @time_millisecond Spins_Per_ms
Wachttijden of knelpunten diagnosticeren
Als u een query wilt optimaliseren die wacht op knelpunten, identificeert u hoe lang de wachttijd is en waar het knelpunt zich bevindt (het wachttype). Zodra het wachttype is bevestigd, vermindert u de wachttijd of elimineert u de wachttijd volledig.
Als u de geschatte wachttijd wilt berekenen, trekt u de CPU-tijd (werktijd) af van de verstreken tijd van een query. Normaal gesproken is de CPU-tijd de werkelijke uitvoeringstijd en het resterende deel van de levensduur van de query wacht.
Voorbeelden van het berekenen van de geschatte wachttijd:
| Verstreken tijd (ms) | CPU-tijd (ms) | Wachttijd (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
Het knelpunt identificeren of wachten
Voer de volgende query uit om historische langwachtquery's te identificeren (bijvoorbeeld >20% van de totale verstreken tijd is wachttijd). Deze query maakt gebruik van prestatiestatistieken voor queryplannen in de cache sinds het begin van SQL Server.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCVoer de volgende query uit om query's met wachttijden langer dan 500 ms te identificeren:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Als u een queryplan kunt verzamelen, controleert u de WaitStats van de eigenschappen van het uitvoeringsplan in SSMS:
- Voer de query uit met Het werkelijke uitvoeringsplan opnemen op.
- Klik met de rechtermuisknop op de meest linkse operator op het tabblad Uitvoeringsplan
- Selecteer Eigenschappen en vervolgens de eigenschap WaitStats .
- Controleer de WaitTimeMs en WaitType.
Als u bekend bent met PSSDiag-/SQLdiag - of SQL LogScout LightPerf-/GeneralPerf-scenario's, kunt u een van deze scenario's gebruiken om prestatiestatistieken te verzamelen en wachtquery's op uw SQL Server-exemplaar te identificeren. U kunt de verzamelde gegevensbestanden importeren en de prestatiegegevens analyseren met SQL Nexus.
Verwijzingen om wachttijden te elimineren of te verminderen
De oorzaken en oplossingen voor elk wachttype variëren. Er is geen algemene methode om alle wachttypen op te lossen. Hier volgen artikelen voor het oplossen van veelvoorkomende problemen met wachttypen:
- Blokkerende problemen begrijpen en oplossen (LCK_M_*)
- Problemen met blokkerende Azure SQL Database begrijpen en oplossen
- Trage SQL Server-prestaties oplossen die worden veroorzaakt door I/O-problemen (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- PAGELATCH_EX-conflicten met invoegen van laatste pagina oplossen in SQL Server
- Geheugen verleent uitleg en oplossingen (RESOURCE_SEMAPHORE)
- Problemen met trage query's oplossen die het gevolg zijn van ASYNC_NETWORK_IO wachttype
- Problemen met hoog HADR_SYNC_COMMIT wachttype met AlwaysOn-beschikbaarheidsgroepen oplossen
- Hoe het werkt: CMEMTHREAD en foutopsporing
- Parallelle uitvoering van wachttijden uitvoeren (CXPACKET en CXCONSUMER)
- THREADPOOL-wachttijd
Zie de tabel in Typen wachttijden voor beschrijvingen van veel wachttypen en wat ze aangeven.
Verschillen in queryplannen vaststellen
Hier volgen enkele veelvoorkomende oorzaken voor verschillen in queryplannen:
Verschillen in gegevensgrootte of gegevenswaarden
Wordt dezelfde database op beide servers gebruikt, met dezelfde databaseback-up? Zijn de gegevens op de ene server gewijzigd in vergelijking met de andere? Gegevensverschillen kunnen leiden tot verschillende queryplannen. Het samenvoegen van tabel T1 (1000 rijen) met tabel T2 (2.000.000 rijen) verschilt bijvoorbeeld van het samenvoegen van tabel T1 (100 rijen) met tabel T2 (2.000.000 rijen). Het type en de snelheid van de
JOINbewerking kunnen aanzienlijk verschillen.Verschillen in statistieken
Zijn statistieken bijgewerkt in de ene database en niet op de andere? Zijn statistieken bijgewerkt met een andere steekproeffrequentie (bijvoorbeeld 30% versus 100% volledige scan)? Zorg ervoor dat u statistieken aan beide zijden bijwerkt met dezelfde steekproeffrequentie.
Verschillen in databasecompatibiliteitsniveau
Controleer of de compatibiliteitsniveaus van de databases verschillen tussen de twee servers. Voer de volgende query uit om het compatibiliteitsniveau van de database op te halen:
SELECT name, compatibility_level FROM sys.databases WHERE name = '<YourDatabase>'Verschillen in serverversie/build
Verschillen de versies of builds van SQL Server tussen de twee servers? Is bijvoorbeeld één server SQL Server versie 2014 en de andere SQL Server-versie 2016? Er kunnen productwijzigingen zijn die kunnen leiden tot wijzigingen in de wijze waarop een queryplan wordt geselecteerd. Zorg ervoor dat u dezelfde versie en build van SQL Server vergelijkt.
SELECT ServerProperty('ProductVersion')Kardinaliteitsschatter (CE) versieverschillen
Controleer of de verouderde kardinaliteitsschatter is geactiveerd op databaseniveau. Zie Kardinaliteitsraming (SQL Server) voor meer informatie over CE.
SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'LEGACY_CARDINALITY_ESTIMATION'Optimizer-hotfixes ingeschakeld/uitgeschakeld
Als de hotfixes voor de queryoptimalisatie zijn ingeschakeld op de ene server, maar op de andere server zijn uitgeschakeld, kunnen verschillende queryplannen worden gegenereerd. Zie voor meer informatie sql Server query optimizer hotfix trace flag 4199 servicing model.
Voer de volgende query uit om de status van hotfixes voor queryoptimalisatie op te halen:
-- Check at server level for TF 4199 DBCC TRACESTATUS (-1) -- Check at database level USE <YourDatabase> SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'QUERY_OPTIMIZER_HOTFIXES'Verschillen in traceringsvlagmen
Sommige traceringsvlagmen zijn van invloed op de selectie van het queryplan. Controleer of er traceringsvlagmen zijn ingeschakeld op de ene server die niet op de andere server zijn ingeschakeld. Voer de volgende query uit op beide servers en vergelijk de resultaten:
-- Check at server level for trace flags DBCC TRACESTATUS (-1)Hardwareverschillen (CPU-aantal, geheugengrootte)
Voer de volgende query uit om de hardwaregegevens op te halen:
SELECT cpu_count, physical_memory_kb/1024/1024 PhysicalMemory_GB FROM sys.dm_os_sys_infoHardwareverschillen volgens de queryoptimalisatie
Controleer het
OptimizerHardwareDependentPropertiesqueryplan en kijk of hardwareverschillen belangrijk zijn voor verschillende plannen.WITH xmlnamespaces(DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan') SELECT txt.text, t.OptHardw.value('@EstimatedAvailableMemoryGrant', 'INT') AS EstimatedAvailableMemoryGrant , t.OptHardw.value('@EstimatedPagesCached', 'INT') AS EstimatedPagesCached, t.OptHardw.value('@EstimatedAvailableDegreeOfParallelism', 'INT') AS EstimatedAvailDegreeOfParallelism, t.OptHardw.value('@MaxCompileMemory', 'INT') AS MaxCompileMemory FROM sys.dm_exec_cached_plans AS cp CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp CROSS APPLY qp.query_plan.nodes('//OptimizerHardwareDependentProperties') AS t(OptHardw) CROSS APPLY sys.dm_exec_sql_text (CP.plan_handle) txt WHERE text Like '%<Part of Your Query>%'Time-out van optimizer
Is er een time-outprobleem voor de optimalisatie? De queryoptimalisatie kan stoppen met het evalueren van planopties als de query die wordt uitgevoerd te complex is. Wanneer het stopt, wordt het abonnement gekozen met de laagste kosten die op dat moment beschikbaar zijn. Dit kan leiden tot een willekeurige keuze voor een plan op de ene server versus een andere.
OPTIES INSTELLEN
Sommige SET-opties zijn van invloed op het plan, zoals SET ARITHABORT. Zie SET-opties voor meer informatie.
Verschillen tussen queryhints
Maakt de ene query gebruik van queryhints en de andere niet? Controleer de querytekst handmatig om de aanwezigheid van queryhints vast te stellen.
Parametergevoelige plannen (probleem met parametersniffing)
Test u de query met exact dezelfde parameterwaarden? Zo niet, dan kunt u daar beginnen. Is het plan eerder gecompileerd op één server op basis van een andere parameterwaarde? Test de twee query's met behulp van de hint voor RECOMPILE-query om ervoor te zorgen dat er geen plan opnieuw wordt gebruikt. Zie Parametergevoelige problemen onderzoeken en oplossen voor meer informatie.
Verschillende databaseopties/configuratie-instellingen met bereik
Worden dezelfde databaseopties of configuratie-instellingen binnen het bereik gebruikt op beide servers? Sommige databaseopties kunnen van invloed zijn op plankeuzen. Databasecompatibiliteit, verouderde CE versus standaard CE en parameter-sniffing. Voer de volgende query uit vanaf één server om de databaseopties te vergelijken die op de twee servers worden gebruikt:
-- On Server1 add a linked server to Server2 EXEC master.dbo.sp_addlinkedserver @server = N'Server2', @srvproduct=N'SQL Server' -- Run a join between the two servers to compare settings side by side SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value_in_use AS srv1_value_in_use, s2.value_in_use AS srv2_value_in_use, Variance = CASE WHEN ISNULL(s1.value_in_use, '##') != ISNULL(s2.value_in_use,'##') THEN 'Different' ELSE '' END FROM sys.configurations s1 FULL OUTER JOIN [server2].master.sys.configurations s2 ON s1.name = s2.name SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value srv1_value_in_use, s2.value srv2_value_in_use, s1.is_value_default, s2.is_value_default, Variance = CASE WHEN ISNULL(s1.value, '##') != ISNULL(s2.value, '##') THEN 'Different' ELSE '' END FROM sys.database_scoped_configurations s1 FULL OUTER JOIN [server2].master.sys.database_scoped_configurations s2 ON s1.name = s2.nameHandleidingen plannen
Worden er planhandleidingen gebruikt voor uw query's op de ene server, maar niet op de andere? Voer de volgende query uit om verschillen vast te stellen:
SELECT * FROM sys.plan_guides