Deltatabellen optimaliseren
Spark is een framework voor parallelle verwerking, met gegevens die zijn opgeslagen op een of meer werkknooppunten. Daarnaast zijn Parquet-bestanden onveranderbaar, met nieuwe bestanden die zijn geschreven voor elke update of verwijdering. Dit proces kan ertoe leiden dat Spark gegevens opslaat in een groot aantal kleine bestanden, ook wel bekend als het probleem met het kleine bestand. Dit betekent dat query's over grote hoeveelheden gegevens langzaam kunnen worden uitgevoerd of zelfs niet kunnen worden voltooid.
OptimizeWrite, functie
OptimizeWrite is een functie van Delta Lake die het aantal bestanden vermindert wanneer ze worden geschreven. In plaats van veel kleine bestanden te schrijven, worden er minder grotere bestanden geschreven. Dit helpt om het probleem met kleine bestanden te voorkomen en ervoor te zorgen dat de prestaties niet verslechterd zijn.
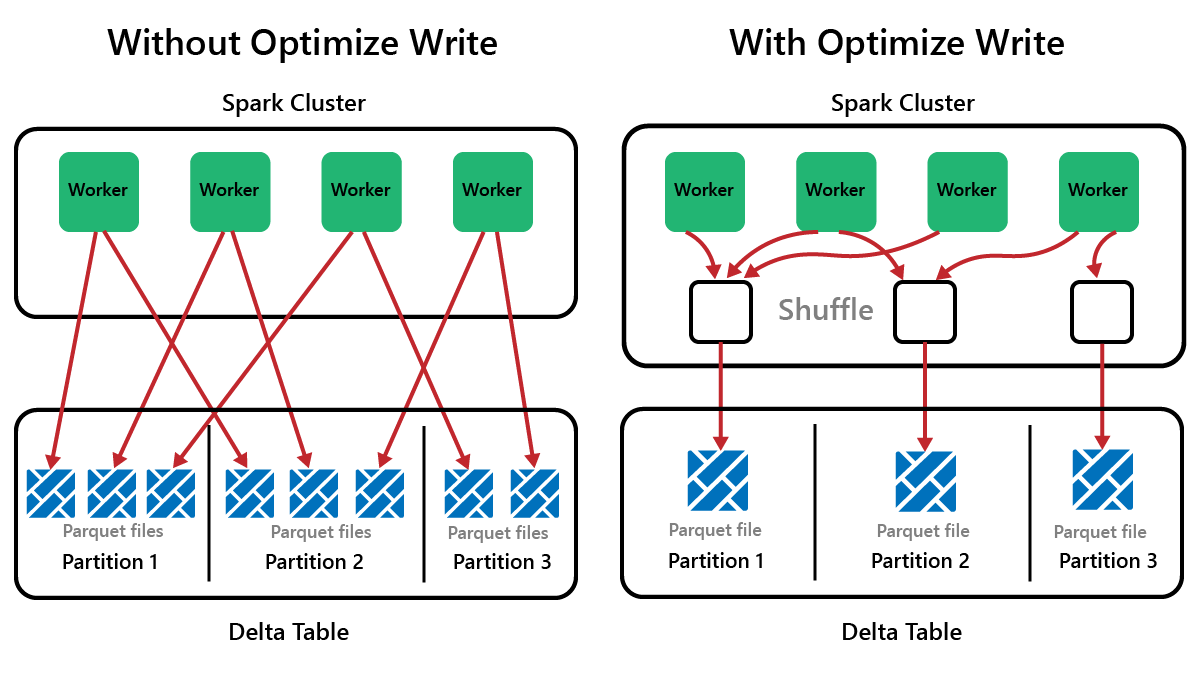
In Microsoft Fabric OptimizeWrite is standaard ingeschakeld. U kunt deze in- of uitschakelen op het niveau van de Spark-sessie:
# Disable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", False)
# Enable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", True)
print(spark.conf.get("spark.microsoft.delta.optimizeWrite.enabled"))
Notitie
OptimizeWrite kan ook worden ingesteld in Tabeleigenschappen en voor afzonderlijke schrijfopdrachten.
Optimaliseren
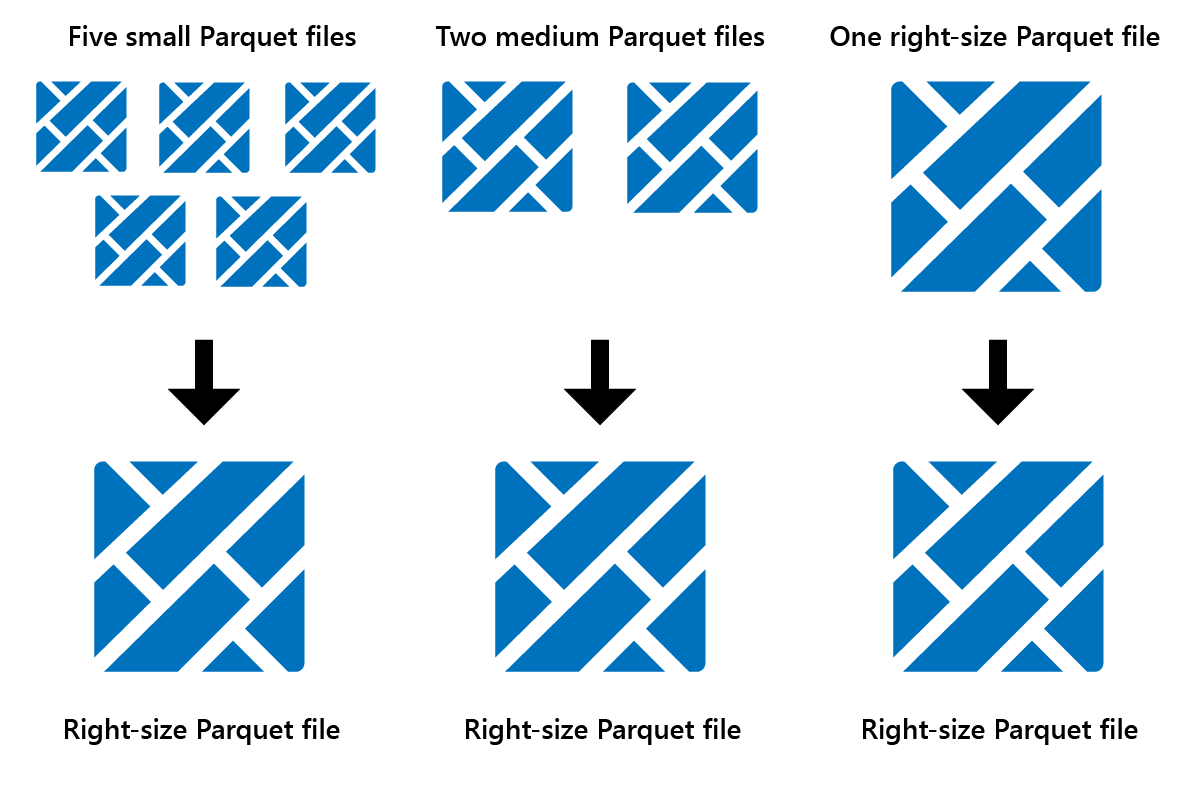
Optimaliseren is een functie voor tabelonderhoud waarmee kleine Parquet-bestanden worden samengevoegd tot minder grote bestanden. U kunt Optimaliseren uitvoeren na het laden van grote tabellen, wat resulteert in:
- minder grotere bestanden
- betere compressie
- efficiënte gegevensdistributie tussen knooppunten
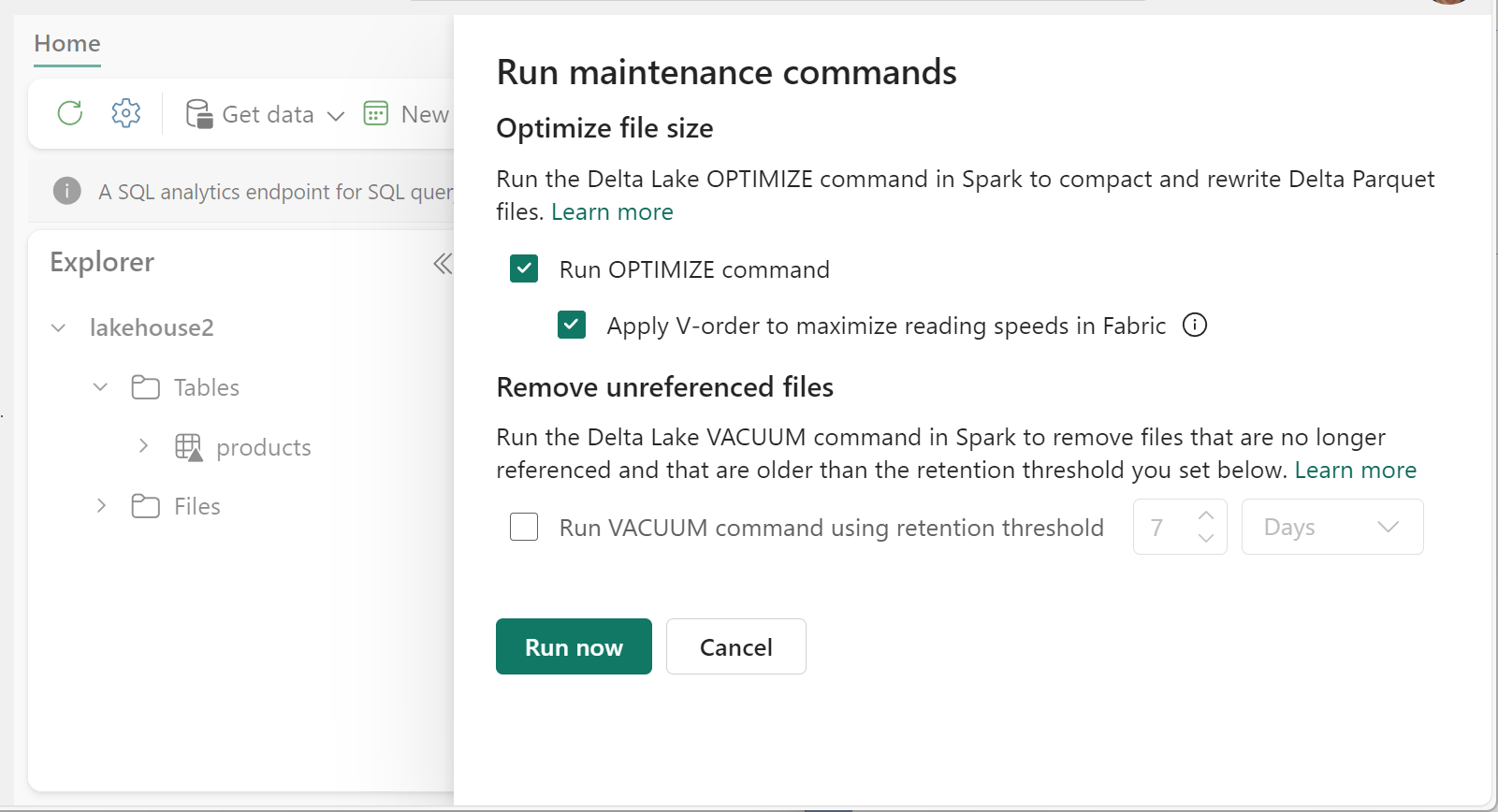
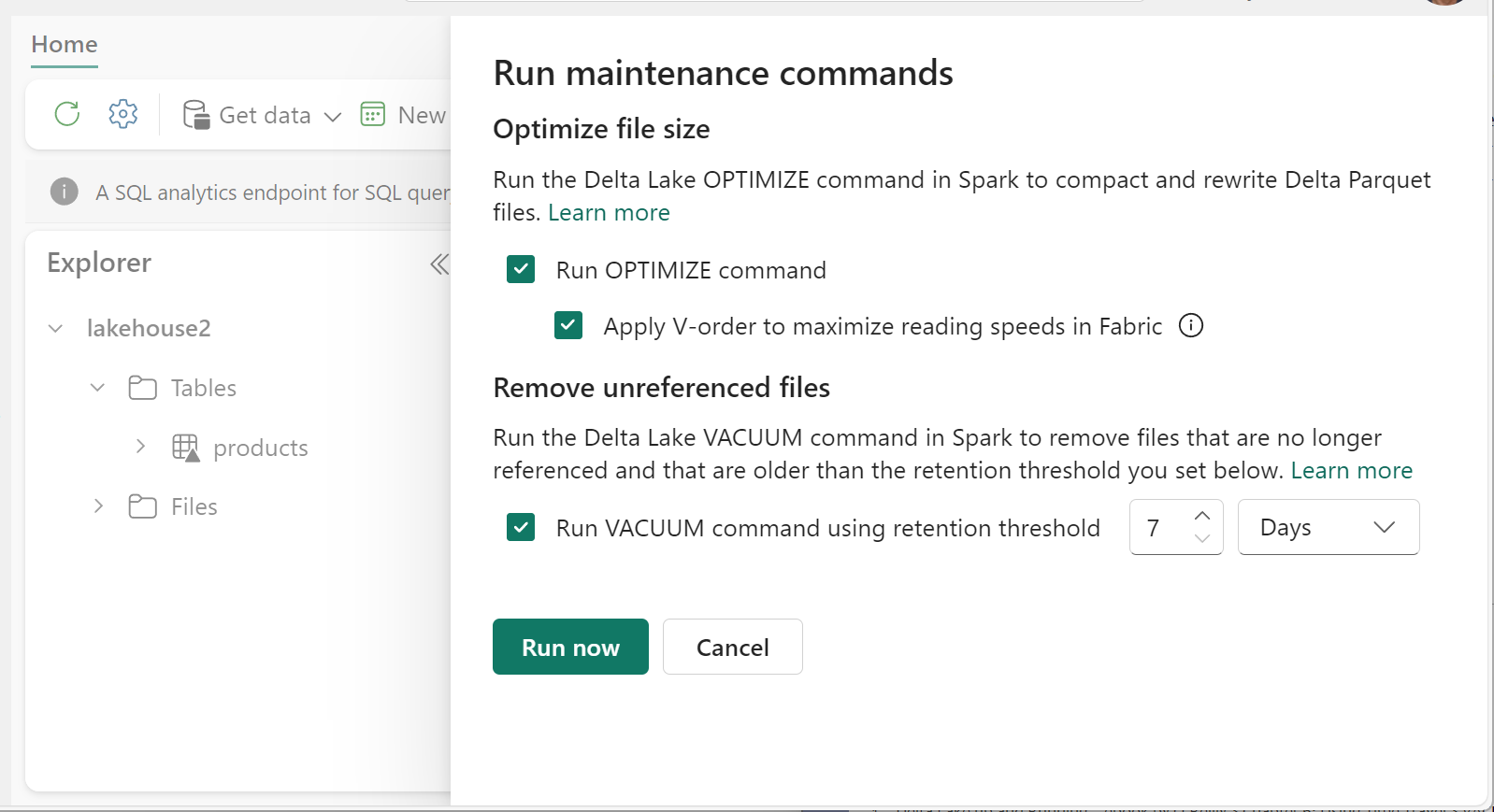
Optimaliseren uitvoeren:
- Selecteer in Lakehouse Explorer de ... menu naast een tabelnaam en selecteer Onderhoud.
- Selecteer de opdracht OPTIMALISEREN uitvoeren.
- Selecteer desgewenst V-volgorde toepassen om de leessnelheden in Fabric te maximaliseren.
- Selecteer Nu uitvoeren.
V-Order, functie
Wanneer u Optimize uitvoert, kunt u desgewenst V-Order uitvoeren, dat is ontworpen voor de Parquet-bestandsindeling in Fabric. V-Order maakt razendsnelle leesbewerkingen mogelijk, met in-memory-achtige gegevenstoegangstijden. Het verbetert ook de kostenefficiëntie omdat het netwerk-, schijf- en CPU-resources vermindert tijdens leesbewerkingen.
V-Order is standaard ingeschakeld in Microsoft Fabric en wordt toegepast wanneer gegevens worden geschreven. Er is een kleine overhead van ongeveer 15% waardoor schrijfbewerkingen iets langzamer worden. V-Order maakt echter snellere leesbewerkingen mogelijk van de Microsoft Fabric-rekenengines, zoals Power BI, SQL, Spark en andere.
In Microsoft Fabric maken de Power BI- en SQL-engines gebruik van Microsoft Verti-Scan-technologie die optimaal gebruikmaakt van V-Order-optimalisatie om leesbewerkingen te versnellen. Spark en andere engines gebruiken geen VertiScan-technologie, maar profiteren nog steeds van V-Order-optimalisatie met ongeveer 10% snellere leesbewerkingen, soms tot 50%.
V-Order werkt door speciale sortering, rijgroepdistributie, woordenlijstcodering en compressie toe te passen op Parquet-bestanden. Het is 100% compatibel met de opensource Parquet-indeling en alle Parquet-engines kunnen deze lezen.
V-Order is mogelijk niet nuttig voor schrijfintensieve scenario's, zoals faseringsgegevensarchieven waarbij gegevens slechts één of twee keer worden gelezen. In deze situaties kan het uitschakelen van V-Order de totale verwerkingstijd voor gegevensopname verminderen.
V-Order toepassen op afzonderlijke tabellen met behulp van de functie Tabelonderhoud door de opdracht uit te OPTIMIZE voeren.
Vacuum
Met de opdracht VACUUM kunt u oude gegevensbestanden verwijderen.
Telkens wanneer een update of verwijdering wordt uitgevoerd, wordt er een nieuw Parquet-bestand gemaakt en wordt er een vermelding gemaakt in het transactielogboek. Oude Parquet-bestanden worden bewaard om tijdreizen mogelijk te maken, wat betekent dat Parquet-bestanden zich in de loop van de tijd verzamelen.
Met de opdracht VACUUM worden oude Parquet-gegevensbestanden verwijderd, maar niet de transactielogboeken. Wanneer u VACUUM uitvoert, kunt u de reistijd niet eerder terugbrengen dan de bewaarperiode.
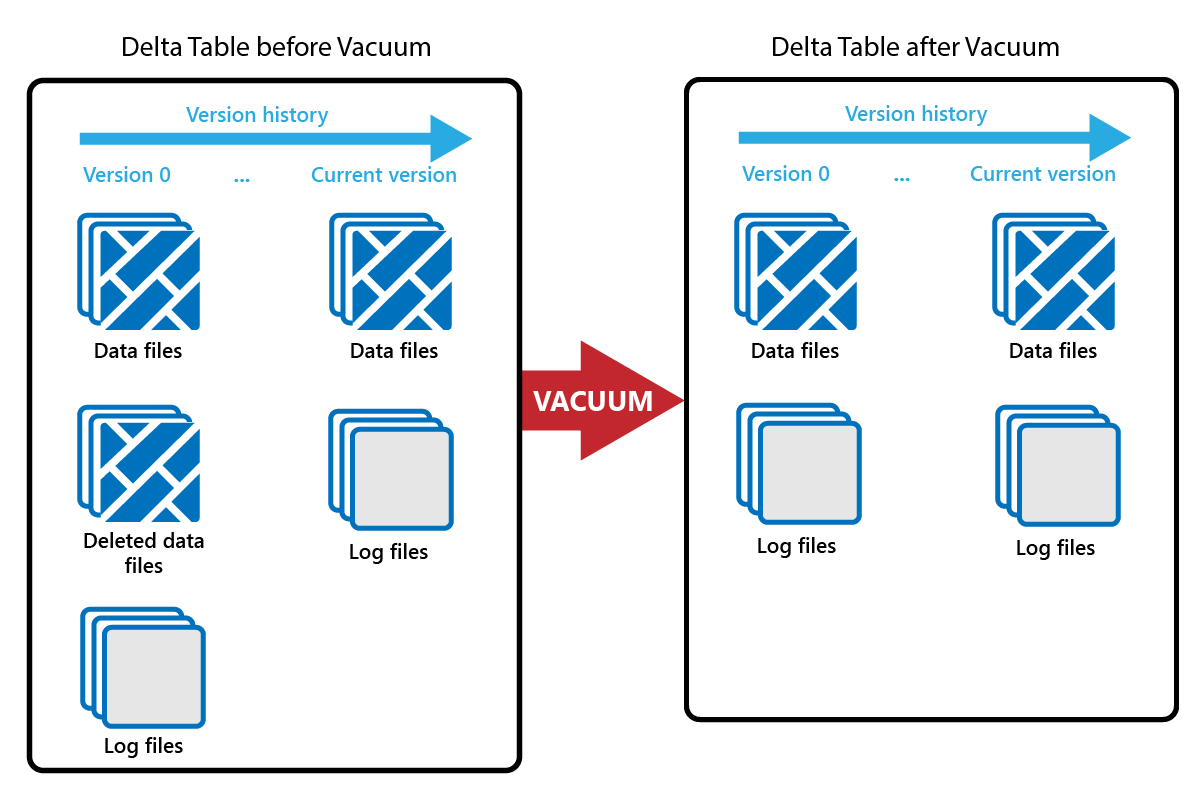
Gegevensbestanden waarnaar momenteel niet wordt verwezen in een transactielogboek en die ouder zijn dan de opgegeven bewaarperiode, worden definitief verwijderd door VACUUM uit te voeren. Kies uw bewaarperiode op basis van factoren zoals:
- Vereisten voor gegevensretentie
- Gegevensgrootte en opslagkosten
- Frequentie van gegevenswijziging
- Wettelijke vereisten
De standaardretentieperiode is 7 dagen (168 uur) en het systeem voorkomt dat u een kortere bewaarperiode gebruikt.
U kunt VACUUM ad-hoc uitvoeren of plannen met behulp van Fabric-notebooks.
Voer VACUUM uit op afzonderlijke tabellen met behulp van de functie Tabelonderhoud:
- Selecteer in Lakehouse Explorer de ... menu naast een tabelnaam en selecteer Onderhoud.
- Selecteer De opdracht VACUUM uitvoeren met behulp van de retentiedrempel en stel de retentiedrempel in.
- Selecteer Nu uitvoeren.
U kunt VACUUM ook uitvoeren als een SQL-opdracht in een notebook:
%%sql
VACUUM lakehouse2.products RETAIN 168 HOURS;
VACUUM-doorvoeringen naar het Delta-transactielogboek, zodat u eerdere uitvoeringen kunt bekijken in DESCRIBE HISTORY.
%%sql
DESCRIBE HISTORY lakehouse2.products;
Delta-tabellen partitioneren
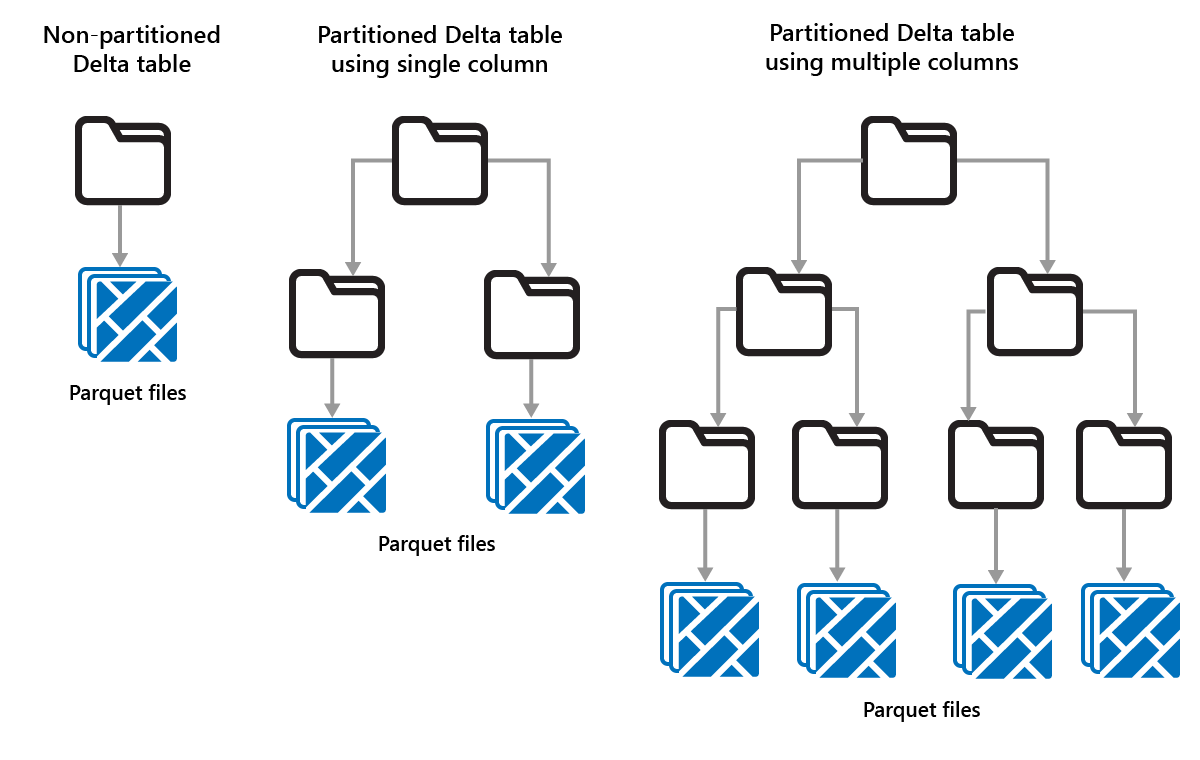
Met Delta Lake kunt u gegevens ordenen in partities. Dit kan de prestaties verbeteren door het overslaan van gegevens mogelijk te maken, waardoor de prestaties worden verbeterd door irrelevante gegevensobjecten over te slaan op basis van de metagegevens van een object.
Overweeg een situatie waarin grote hoeveelheden verkoopgegevens worden opgeslagen. U kunt verkoopgegevens per jaar partitioneren. De partities worden opgeslagen in submappen met de naam "year=2021", "year=2022", enzovoort. Als u alleen wilt rapporteren over verkoopgegevens voor 2024, kunnen de partities voor andere jaren worden overgeslagen, waardoor de leesprestaties worden verbeterd.
Het partitioneren van kleine hoeveelheden gegevens kan echter de prestaties verminderen, omdat het aantal bestanden toeneemt en het 'probleem met kleine bestanden' kan verergeren.
Partitionering gebruiken wanneer:
- U hebt zeer grote hoeveelheden gegevens.
- Tabellen kunnen worden gesplitst in een paar grote partities.
Gebruik partitionering niet wanneer:
- Gegevensvolumes zijn klein.
- Een partitioneringskolom heeft een hoge kardinaliteit, omdat hiermee een groot aantal partities wordt gemaakt.
- Een partitioneringskolom resulteert in meerdere niveaus.
Partities zijn een vaste gegevensindeling en passen zich niet aan verschillende querypatronen aan. Denk bij het gebruik van partitionering na over hoe uw gegevens worden gebruikt en de granulariteit ervan.
In dit voorbeeld wordt een DataFrame met productgegevens gepartitioneerd op categorie:
df.write.format("delta").partitionBy("Category").saveAsTable("partitioned_products", path="abfs_path/partitioned_products")
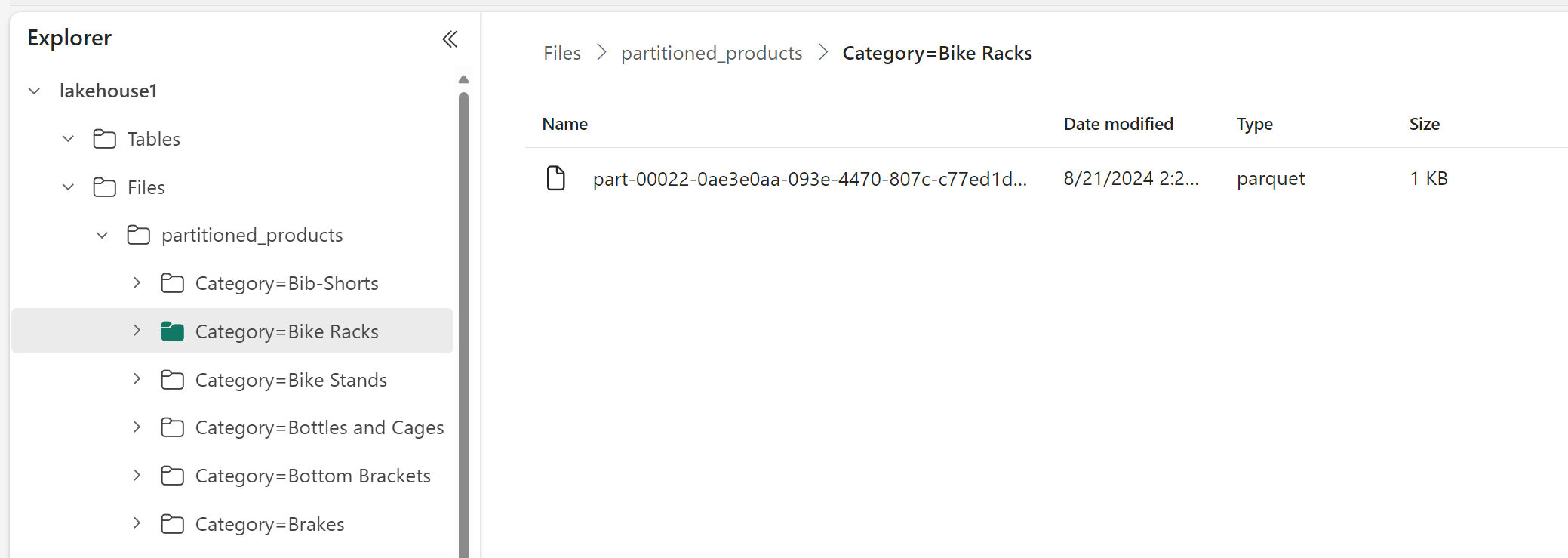
In Lakehouse Explorer ziet u dat de gegevens een gepartitioneerde tabel zijn.
- Er is één map voor de tabel, genaamd 'partitioned_products'.
- Er zijn submappen voor elke categorie, bijvoorbeeld 'Category=Bike Racks', enzovoort.
We kunnen een vergelijkbare gepartitioneerde tabel maken met behulp van SQL:
%%sql
CREATE TABLE partitioned_products (
ProductID INTEGER,
ProductName STRING,
Category STRING,
ListPrice DOUBLE
)
PARTITIONED BY (Category);