Inzicht in Delta Lake
Delta Lake is een opensource-opslaglaag die semantiek van relationele databases toevoegt aan gegevensverwerking op basis van Spark. Tabellen in Microsoft Fabric Lakehouses zijn Delta-tabellen, die worden aangeduid met het driehoekige Delta-pictogram (Δ) op tabellen in de gebruikersinterface van Lakehouse.
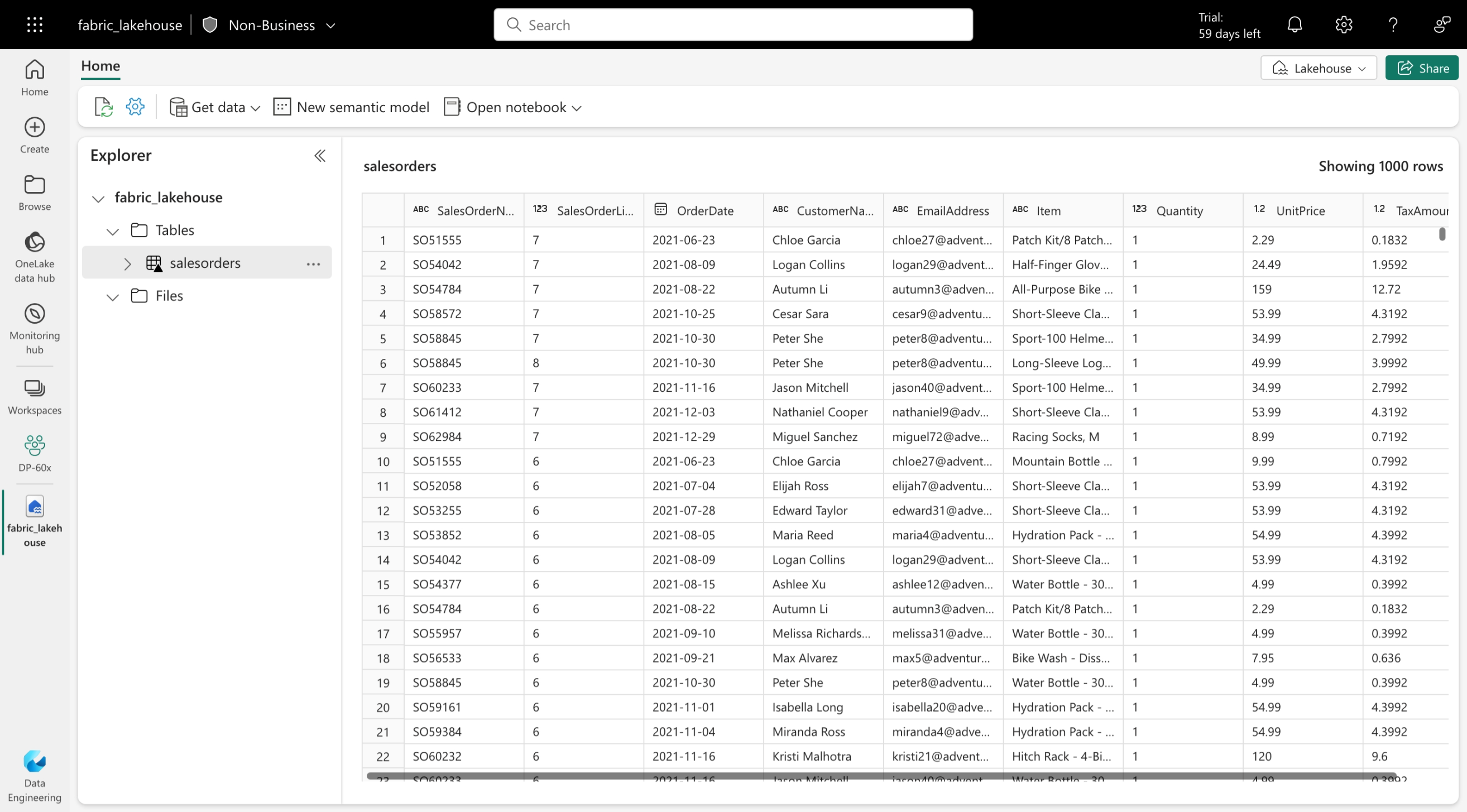
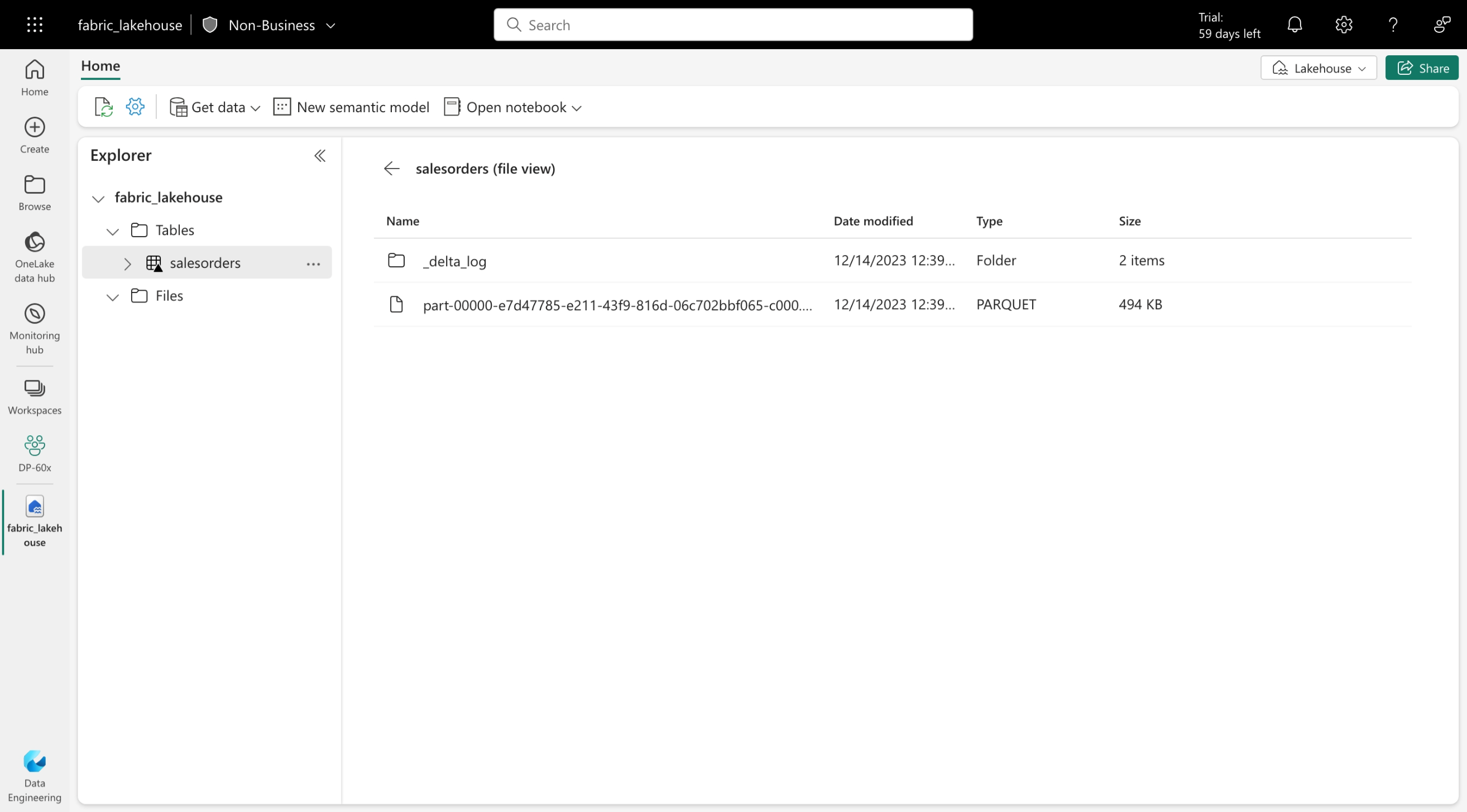
Delta-tabellen zijn schemaabstracties voor gegevensbestanden die zijn opgeslagen in Delta-indeling. Voor elke tabel slaat lakehouse een map op met Parquet-gegevensbestanden en een _delta_Log map waarin transactiegegevens worden vastgelegd in JSON-indeling.
De voordelen van het gebruik van Delta-tabellen zijn:
- Relationele tabellen die ondersteuning bieden voor het uitvoeren van query's en het wijzigen van gegevens. Met Apache Spark kunt u gegevens opslaan in Delta-tabellen die CRUD-bewerkingen (maken, lezen, bijwerken en verwijderen) ondersteunen. Met andere woorden, u kunt rijen met gegevens op dezelfde manier selecteren, invoegen, bijwerken en verwijderen als in een relationeel databasesysteem.
- Ondersteuning voor ACID-transacties. Relationele databases zijn ontworpen ter ondersteuning van transactionele gegevenswijzigingen die atomiciteit bieden (transacties voltooid als één werkeenheid), consistentie (transacties verlaten de database in een consistente status), isolatie (in-process transacties kunnen elkaar niet verstoren) en duurzaamheid (wanneer een transactie is voltooid, worden de aangebrachte wijzigingen behouden). Delta Lake biedt dezelfde transactionele ondersteuning voor Spark door een transactielogboek te implementeren en serialiseerbare isolatie af te dwingen voor gelijktijdige bewerkingen.
- Versiebeheer van gegevens en tijdreizen. Omdat alle transacties zijn vastgelegd in het transactielogboek, kunt u meerdere versies van elke tabelrij bijhouden en zelfs de functie tijdreizen gebruiken om een eerdere versie van een rij in een query op te halen.
- Ondersteuning voor batch- en streaminggegevens. Hoewel de meeste relationele databases tabellen bevatten die statische gegevens opslaan, bevat Spark systeemeigen ondersteuning voor het streamen van gegevens via de Structured Streaming-API van Spark. Delta Lake-tabellen kunnen worden gebruikt als zowel sinks (bestemmingen) als bronnen voor streaminggegevens.
- Standaardindelingen en interoperabiliteit. De onderliggende gegevens voor Delta-tabellen worden opgeslagen in Parquet-indeling, die vaak wordt gebruikt in data lake-opnamepijplijnen. Daarnaast kunt u het SQL Analytics-eindpunt voor microsoft Fabric lakehouse gebruiken om query's uit te voeren op Delta-tabellen in SQL.