Het juiste rekendoel kiezen
In Azure Machine Learning zijn rekendoelen fysieke of virtuele computers waarop taken worden uitgevoerd.
Inzicht in de beschikbare typen rekenkracht
Azure Machine Learning ondersteunt meerdere typen berekeningen voor experimenten, training en implementatie. Als u meerdere typen rekenkracht hebt, kunt u het meest geschikte type rekendoel voor uw behoeften selecteren.
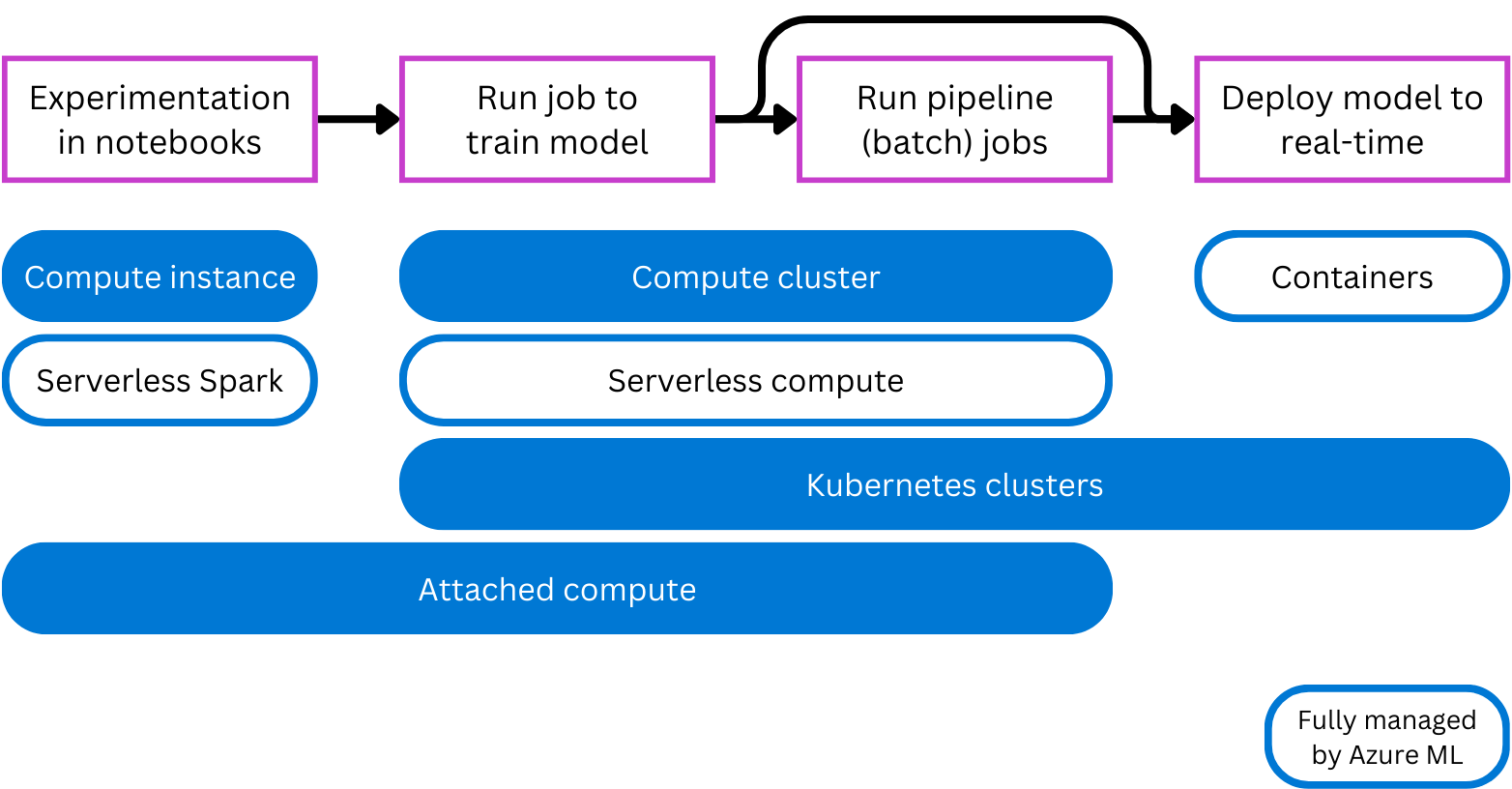
- Rekenproces: gedraagt zich op dezelfde manier als een virtuele machine en wordt voornamelijk gebruikt om notebooks uit te voeren. Het is ideaal voor experimenten.
- Rekenclusters: clusters met meerdere knooppunten van virtuele machines die automatisch omhoog of omlaag worden geschaald om aan de vraag te voldoen. Een rendabele manier om scripts uit te voeren die grote hoeveelheden gegevens moeten verwerken. Met clusters kunt u ook parallelle verwerking gebruiken om de werkbelasting te distribueren en de tijd die nodig is om een script uit te voeren verkorten.
- Kubernetes-clusters: Cluster op basis van Kubernetes-technologie, zodat u meer controle hebt over hoe de berekening wordt geconfigureerd en beheerd. U kunt uw zelfbeheerde AKS-cluster (Azure Kubernetes) koppelen voor cloud-compute of een Arc Kubernetes-cluster voor on-premises workloads.
- Gekoppelde rekenkracht: hiermee kunt u bestaande berekeningen, zoals virtuele Azure-machines of Azure Databricks-clusters, koppelen aan uw werkruimte.
- Serverloze berekening: een volledig beheerde, on-demand berekening die u kunt gebruiken voor trainingstaken.
Notitie
Azure Machine Learning biedt u de mogelijkheid om uw eigen rekenkracht te maken en te beheren of om berekeningen te gebruiken die volledig worden beheerd door Azure Machine Learning.
Wanneer gebruikt u welk type berekening?
Over het algemeen zijn er enkele aanbevolen procedures die u kunt volgen wanneer u met rekendoelen werkt. Als u wilt weten hoe u het juiste type rekenproces kiest, worden er verschillende voorbeelden gegeven. Houd er rekening mee dat welk type rekenproces u gebruikt, altijd afhankelijk is van uw specifieke situatie.
Een rekendoel kiezen voor experimenten
Stel dat u een data scientist bent en u wordt gevraagd een nieuw machine learning-model te ontwikkelen. U hebt waarschijnlijk een kleine subset van de trainingsgegevens waarmee u kunt experimenteren.
Tijdens experimenten en ontwikkeling werkt u liever in een Jupyter-notebook. Een notebookervaring profiteert het meeste van een berekening die continu wordt uitgevoerd.
Veel gegevenswetenschappers zijn bekend met het uitvoeren van notebooks op hun lokale apparaat. Een alternatief voor de cloud dat wordt beheerd door Azure Machine Learning, is een rekenproces. U kunt er ook voor kiezen om serverloze Spark-berekeningen uit te voeren in notebooks als u gebruik wilt maken van de gedistribueerde rekenkracht van Spark.
Een rekendoel voor productie kiezen
Na experimenten kunt u uw modellen trainen door Python-scripts uit te voeren om de productie voor te bereiden. Scripts zijn eenvoudiger te automatiseren en te plannen wanneer u uw model gedurende een bepaalde periode continu opnieuw wilt trainen. U kunt scripts uitvoeren als (pijplijn)-taken.
Wanneer u overstapt naar productie, wilt u dat het rekendoel gereed is voor het verwerken van grote hoeveelheden gegevens. Hoe meer gegevens u gebruikt, hoe beter het machine learning-model waarschijnlijk is.
Wanneer u modellen met scripts traint, wilt u een rekendoel op aanvraag. Een rekencluster wordt automatisch opgeschaald wanneer de scripts moeten worden uitgevoerd en wordt omlaag geschaald wanneer het script is uitgevoerd. Als u een alternatief wilt dat u niet hoeft te maken en beheren, kunt u de serverloze rekenkracht van Azure Machine Learning gebruiken.
Een rekendoel kiezen voor implementatie
Het type rekenproces dat u nodig hebt bij het gebruik van uw model om voorspellingen te genereren, is afhankelijk van of u batch- of realtime voorspellingen wilt.
Voor batchvoorspellingen kunt u een pijplijntaak uitvoeren in Azure Machine Learning. Rekendoelen zoals rekenclusters en serverloze berekeningen van Azure Machine Learning zijn ideaal voor pijplijntaken omdat ze on-demand en schaalbaar zijn.
Wanneer u realtime voorspellingen wilt, hebt u een type berekening nodig dat continu wordt uitgevoerd. Realtime implementaties profiteren daarom van lichtgewicht (en dus rendabeler) rekenkracht. Containers zijn ideaal voor realtime implementaties. Wanneer u uw model implementeert op een beheerd online-eindpunt, maakt en beheert Azure Machine Learning containers om uw model uit te voeren. U kunt ook Kubernetes-clusters koppelen om de benodigde rekenkracht te beheren om realtime voorspellingen te genereren.