Gegevensbestanden transformeren met de instructie CREATE EXTERNAL TABLE AS SELECT
De SQL-taal bevat veel functies en functies waarmee u gegevens kunt bewerken. U kunt bijvoorbeeld SQL gebruiken om het volgende te doen:
- Rijen en kolommen in een gegevensset filteren.
- Wijzig de naam van gegevensvelden en converteer tussen gegevenstypen.
- Afgeleide gegevensvelden berekenen.
- Tekenreekswaarden bewerken.
- Gegevens groeperen en aggregeren.
Serverloze SQL-pools van Azure Synapse kunnen worden gebruikt om SQL-instructies uit te voeren waarmee gegevens worden getransformeerd en de resultaten als een bestand in een data lake worden bewaard voor verdere verwerking of query's. Als u bekend bent met de Transact-SQL-syntaxis, kunt u een SELECT-instructie maken die de specifieke transformatie toepast waarin u geïnteresseerd bent, en de resultaten van de SELECT-instructie opslaan in een geselecteerde bestandsindeling met een schema voor een metagegevenstabel waarop query's kunnen worden uitgevoerd met behulp van SQL.
U kunt een CETAS-instructie (CREATE EXTERNAL TABLE AS SELECT) in een toegewezen SQL-pool of een serverloze SQL-pool gebruiken om de resultaten van een query in een externe tabel te behouden, waarin de gegevens in een bestand in de data lake worden opgeslagen.
De CETAS-instructie bevat een SELECT-instructie waarmee gegevens uit een geldige gegevensbron worden opgevraagd en bewerkt (dit kan een bestaande tabel of weergave in een database zijn, of een OPENROWSET-functie waarmee gegevens op basis van bestanden uit de data lake worden gelezen). De resultaten van de SELECT-instructie worden vervolgens bewaard in een externe tabel, een metagegevensobject in een database dat een relationele abstractie biedt van gegevens die zijn opgeslagen in bestanden. In het volgende diagram ziet u het concept visueel:
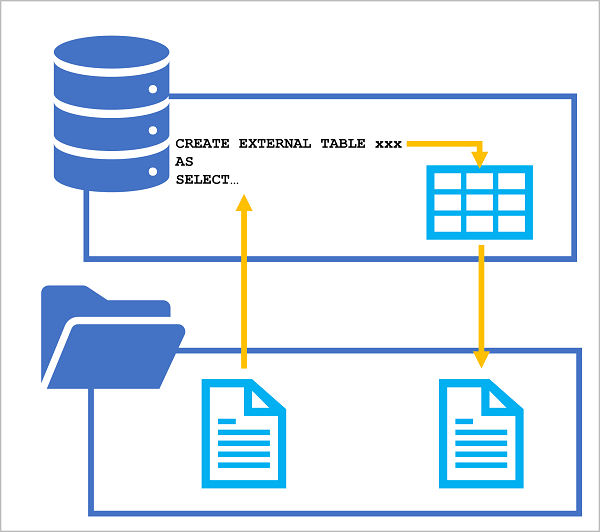
Door deze techniek toe te passen, kunt u SQL gebruiken om gegevens uit bestanden of tabellen te extraheren en te transformeren en de getransformeerde resultaten op te slaan voor downstreamverwerking of -analyse. Volgende bewerkingen op de getransformeerde gegevens kunnen worden uitgevoerd op basis van de relationele tabel in de SQL-pooldatabase of rechtstreeks op basis van de onderliggende gegevensbestanden.
Externe databaseobjecten maken ter ondersteuning van CETAS
Als u CETAS-expressies wilt gebruiken, moet u de volgende typen objecten maken in een database voor een serverloze of toegewezen SQL-pool. Wanneer u een serverloze SQL-pool gebruikt, maakt u deze objecten in een aangepaste database (gemaakt met behulp van de CREATE DATABASE instructie), niet in de ingebouwde database.
Externe gegevensbron
Een externe gegevensbron bevat een verbinding met een bestandssysteemlocatie in een data lake. Vervolgens kunt u deze verbinding gebruiken om een relatief pad op te geven waarin de gegevensbestanden voor de externe tabel die door de CETAS-instructie zijn gemaakt, worden opgeslagen.
Als de brongegevens voor de CETAS-instructie zich in bestanden in hetzelfde Data Lake-pad bevinden, kunt u dezelfde externe gegevensbron gebruiken in de functie OPENROWSET die wordt gebruikt om er query's op uit te voeren. U kunt ook een afzonderlijke externe gegevensbron maken voor de bronbestanden of een volledig gekwalificeerd bestandspad gebruiken in de functie OPENROWSET.
Als u een externe gegevensbron wilt maken, gebruikt u de CREATE EXTERNAL DATA SOURCE instructie, zoals wordt weergegeven in dit voorbeeld:
-- Create an external data source for the Azure storage account
CREATE EXTERNAL DATA SOURCE files
WITH (
LOCATION = 'https://mydatalake.blob.core.windows.net/data/files/',
TYPE = HADOOP, -- For dedicated SQL pool
-- TYPE = BLOB_STORAGE, -- For serverless SQL pool
CREDENTIAL = storageCred
);
In het vorige voorbeeld wordt ervan uitgegaan dat gebruikers die query's uitvoeren die gebruikmaken van de externe gegevensbron over voldoende machtigingen beschikken om toegang te krijgen tot de bestanden. Een alternatieve methode is het inkapselen van een referentie in de externe gegevensbron, zodat deze kan worden gebruikt voor toegang tot bestandsgegevens zonder dat alle gebruikers machtigingen hebben om deze rechtstreeks te lezen:
CREATE DATABASE SCOPED CREDENTIAL storagekeycred
WITH
IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=xxx...';
CREATE EXTERNAL DATA SOURCE secureFiles
WITH (
LOCATION = 'https://mydatalake.blob.core.windows.net/data/secureFiles/'
CREDENTIAL = storagekeycred
);
Tip
Naast SAS-verificatie kunt u referenties definiëren die gebruikmaken van een beheerde identiteit (de Microsoft Entra-identiteit die wordt gebruikt door uw Azure Synapse-werkruimte), een specifieke Microsoft Entra-principal of passthrough-verificatie op basis van de identiteit van de gebruiker die de query uitvoert (dit is het standaardtype verificatie). Voor meer informatie over het gebruik van referenties in een serverloze SQL-pool raadpleegt u het artikel Toegang tot het opslagaccount beheren voor een serverloze SQL-pool in Azure Synapse Analytics in de documentatie van Azure Synapse Analytics.
Externe bestandsindeling
De CETAS-instructie maakt een tabel met de gegevens die zijn opgeslagen in bestanden. U moet de indeling opgeven van de bestanden die u wilt maken als een externe bestandsindeling.
Als u een externe bestandsindeling wilt maken, gebruikt u de CREATE EXTERNAL FILE FORMAT instructie, zoals wordt weergegeven in dit voorbeeld:
CREATE EXTERNAL FILE FORMAT ParquetFormat
WITH (
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
);
Tip
In dit voorbeeld worden de bestanden opgeslagen in Parquet-indeling. U kunt ook externe bestandsindelingen maken voor andere bestandstypen. Zie CREATE EXTERNAL FILE FORMAT (Transact-SQL) voor meer informatie.
De CETAS-instructie gebruiken
Nadat u een externe gegevensbron en een externe bestandsindeling hebt gemaakt, kunt u de CETAS-instructie gebruiken om gegevens te transformeren en de resultaten op te slaan in een externe tabel.
Stel dat de brongegevens die u wilt transformeren bestaan uit verkooporders in door komma's gescheiden tekstbestanden die zijn opgeslagen in een map in een data lake. U wilt de gegevens filteren om alleen orders op te nemen die zijn gemarkeerd als 'speciale volgorde', en de getransformeerde gegevens opslaan als Parquet-bestanden in een andere map in dezelfde data lake. U kunt dezelfde externe gegevensbron gebruiken voor zowel de bron- als doelmappen, zoals wordt weergegeven in dit voorbeeld:
CREATE EXTERNAL TABLE SpecialOrders
WITH (
-- details for storing results
LOCATION = 'special_orders/',
DATA_SOURCE = files,
FILE_FORMAT = ParquetFormat
)
AS
SELECT OrderID, CustomerName, OrderTotal
FROM
OPENROWSET(
-- details for reading source files
BULK 'sales_orders/*.csv',
DATA_SOURCE = 'files',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE
) AS source_data
WHERE OrderType = 'Special Order';
De LOCATION parameters BULK in het vorige voorbeeld zijn relatieve paden voor respectievelijk de resultaten en bronbestanden. De paden zijn relatief ten opzichte van de locatie van het bestandssysteem waarnaar wordt verwezen door de externe gegevensbron van de bestanden .
Een belangrijk punt om te begrijpen is dat u een externe gegevensbron moet gebruiken om de locatie op te geven waar de getransformeerde gegevens voor de externe tabel moeten worden opgeslagen. Wanneer brongegevens op basis van bestanden worden opgeslagen in dezelfde maphiërarchie, kunt u dezelfde externe gegevensbron gebruiken. Anders kunt u een tweede gegevensbron gebruiken om een verbinding met de brongegevens te definiëren of het volledig gekwalificeerde pad te gebruiken, zoals wordt weergegeven in dit voorbeeld:
CREATE EXTERNAL TABLE SpecialOrders
WITH (
-- details for storing results
LOCATION = 'special_orders/',
DATA_SOURCE = files,
FILE_FORMAT = ParquetFormat
)
AS
SELECT OrderID, CustomerName, OrderTotal
FROM
OPENROWSET(
-- details for reading source files
BULK 'https://mystorage.blob.core.windows.net/data/sales_orders/*.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE
) AS source_data
WHERE OrderType = 'Special Order';
Externe tabellen verwijderen
Als u de externe tabel met de getransformeerde gegevens niet meer nodig hebt, kunt u deze verwijderen uit de database met behulp van de DROP EXTERNAL TABLE instructie, zoals hier wordt weergegeven:
DROP EXTERNAL TABLE SpecialOrders;
Het is echter belangrijk om te begrijpen dat externe tabellen een abstractie van metagegevens zijn voor de bestanden die de werkelijke gegevens bevatten. Als u een externe tabel verwijdert, worden de onderliggende bestanden niet verwijderd.