De Uitvoeringsomgeving van jupyter-notebook configureren
In deze sectie werken we met het Jupyter-notebook dat is geüpload naar onze Jupyter-werkruimte. We voeren opdrachten uit waarmee afhankelijkheden worden geïnstalleerd om ervoor te zorgen dat onze omgeving later autoML-taken kan uitvoeren. Dit proces omvat het upgraden van de Azure Machine Learning Python SDK en het installeren van het Torchvision Python-pakket.
De Uitvoeringsomgeving van jupyter-notebook configureren
Als u het Jupyter-notebook wilt openen, gaat u naar uw Jupyter-werkruimte en selecteert u het bestand AutoMLImage_ObjectDetection.ipynb .
Als u een kernel niet gevonden prompt ontvangt, selecteert u Python 3.8 - AzureML in de vervolgkeuzelijst, zoals wordt weergegeven en selecteert u Set Kernel.

Voer de cellen uit in de sectie Omgevingsinstellingen . U kunt dit doen door de cel te selecteren en vervolgens op Shift+Enter op het toetsenbord te drukken. Herhaal dit proces voor elke cel en stop na het uitvoeren van pip install torchvision==0.9.1.
Nadat u de pip-installatie torchvision==0.9.1-taak hebt uitgevoerd, moet u de kernel opnieuw opstarten. Als u de kernel opnieuw wilt starten, selecteert u het menu-item Kernel en kiest u Opnieuw opstarten in de vervolgkeuzelijst.
Voer de *pip freeze-cel uit, waarin alle geïnstalleerde Python-bibliotheken worden weergegeven. Voer vervolgens de onderliggende cel uit om de bibliotheken te importeren die in verdere stappen worden gebruikt.
Ga door met het uitvoeren van de cellen in de sectie Werkruimte-instelling . In deze stap wordt het config.json-bestand gelezen dat eerder is geüpload en kunnen we taken uitvoeren op basis van uw Azure Machine Learning-werkruimte.
Ga door met het uitvoeren van de cellen in de sectie Compute-doelinstallatie . U wilt de waarde van compute_name wijzigen zodat deze overeenkomt met de naam van het rekenproces dat aanwezig is in uw Azure Machine Learning-studio werkruimte. Het script kan het exemplaar niet maken als er al een exemplaar van dezelfde naam in dezelfde regio bestaat en er een tweede exemplaar wordt gemaakt. De volgende stappen werken nog steeds, maar gebruiken de bestaande resource niet.
Ga door met het uitvoeren van de cellen in de sectie Experiment setup . Hiermee maakt u een Azure Machine Learning-experiment waarmee we de status van het model tijdens de training kunnen bijhouden.
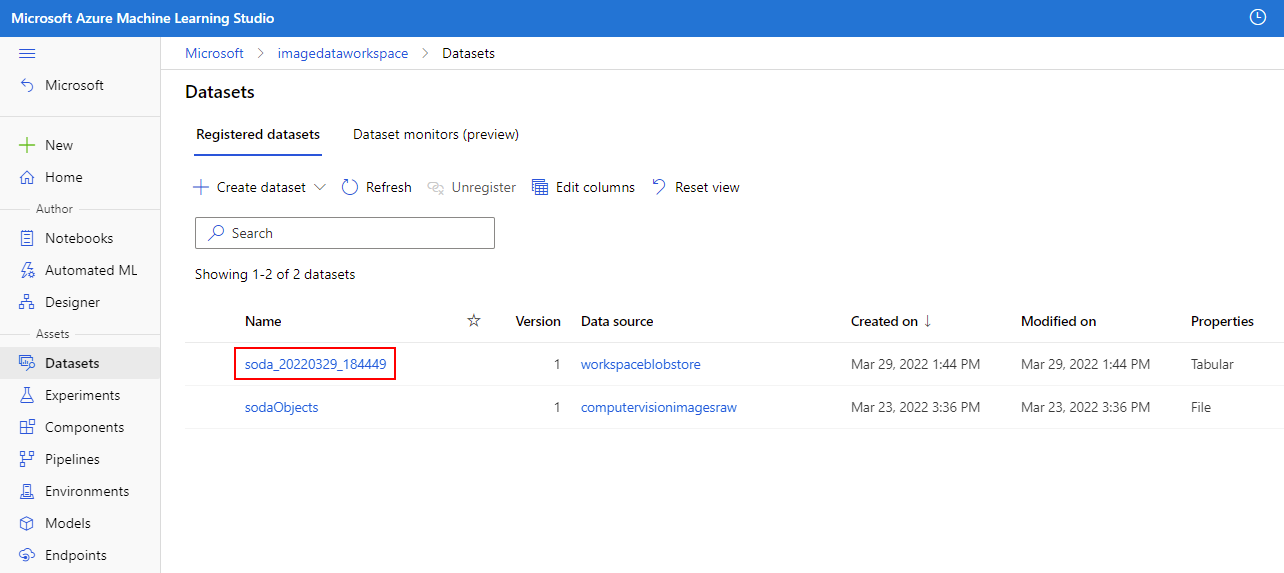
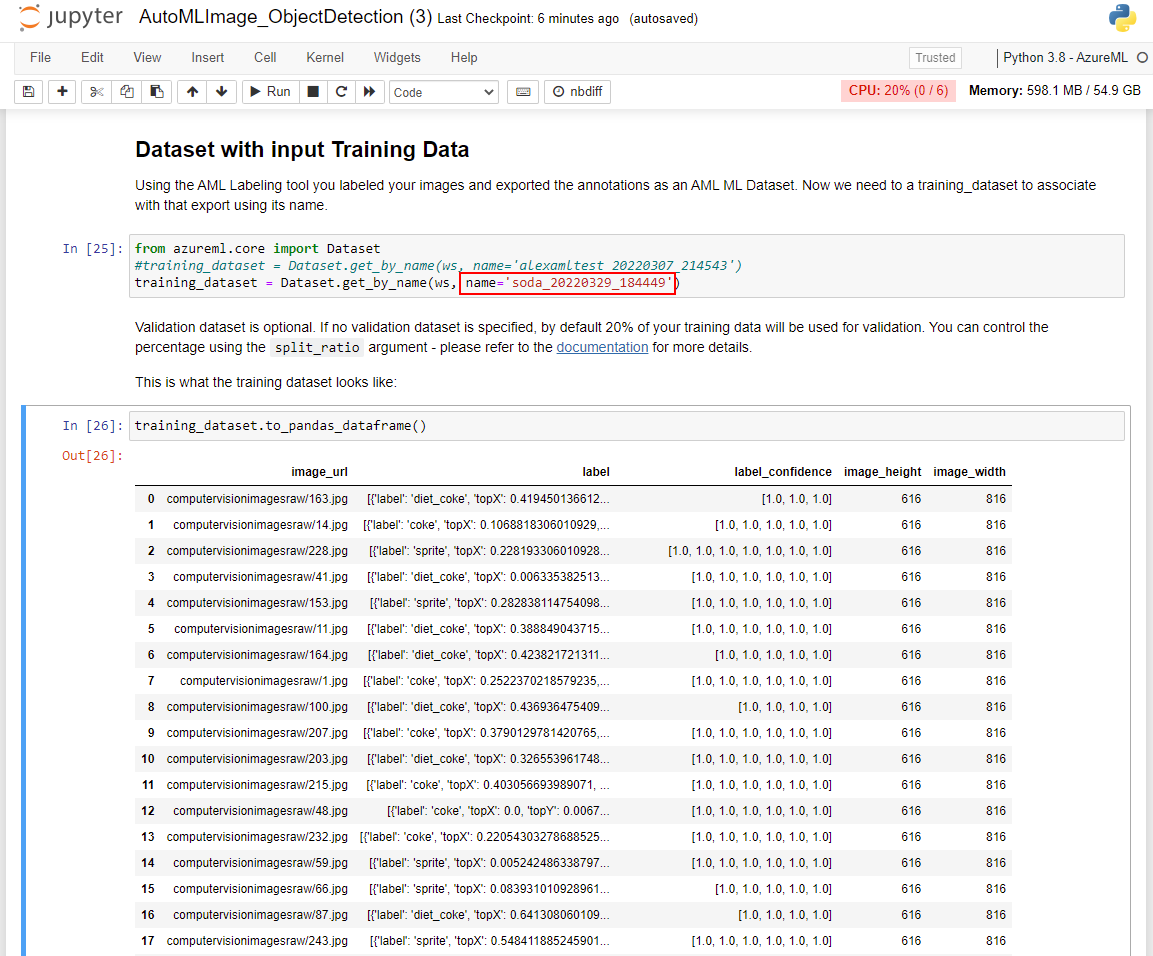
Ga door met het uitvoeren van de cellen in de sectie Gegevensset met invoertrainingsgegevens . Houd er rekening mee dat u de naamvariabele moet vervangen door de naam van de gegevensset die aan het einde van de vorige module is geëxporteerd. Deze waarde kan worden verkregen in uw Azure Machine Learning-studio exemplaar in het linkerdeelvenster. Zoek hier de sectie Assets en selecteer Gegevenssets. U kunt controleren of de gegevensset correct is geïmporteerd door de uitvoer weer te geven in de cel training_dataset.to_pandas_dataframe().