Een Spark-cluster maken
U kunt een of meer clusters maken in uw Azure Databricks-werkruimte met behulp van de Azure Databricks-portal.
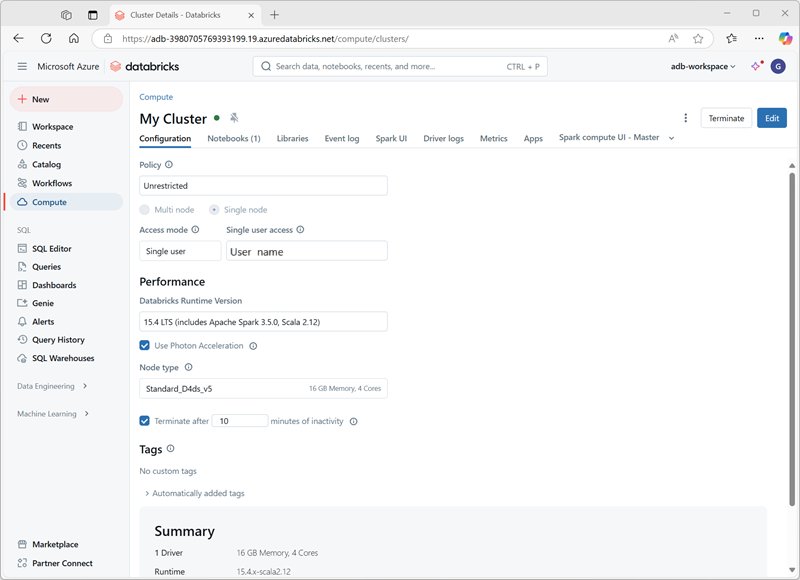
Wanneer u het cluster maakt, kunt u configuratie-instellingen opgeven, waaronder:
- Een naam voor het cluster.
- Een clustermodus, die kan zijn:
- Standaard: geschikt voor workloads van één gebruiker waarvoor meerdere werkknooppunten zijn vereist.
- Hoge gelijktijdigheid: geschikt voor workloads waarbij meerdere gebruikers het cluster gelijktijdig gebruiken.
- Eén knooppunt: geschikt voor kleine workloads of tests, waarbij slechts één werkknooppunt is vereist.
- De versie van de Databricks Runtime die in het cluster moet worden gebruikt. Deze versie bepaalt de versie van Spark en afzonderlijke onderdelen, zoals Python, Scala en andere onderdelen die worden geïnstalleerd.
- Het type virtuele machine (VM) dat wordt gebruikt voor de werkknooppunten in het cluster.
- Het minimum- en maximum aantal werkknooppunten in het cluster.
- Het type VM dat wordt gebruikt voor het stuurprogrammaknooppunt in het cluster.
- Of het cluster ondersteuning biedt voor automatisch schalen om het formaat van het cluster dynamisch te wijzigen.
- Hoe lang het cluster inactief kan blijven voordat het automatisch wordt afgesloten.
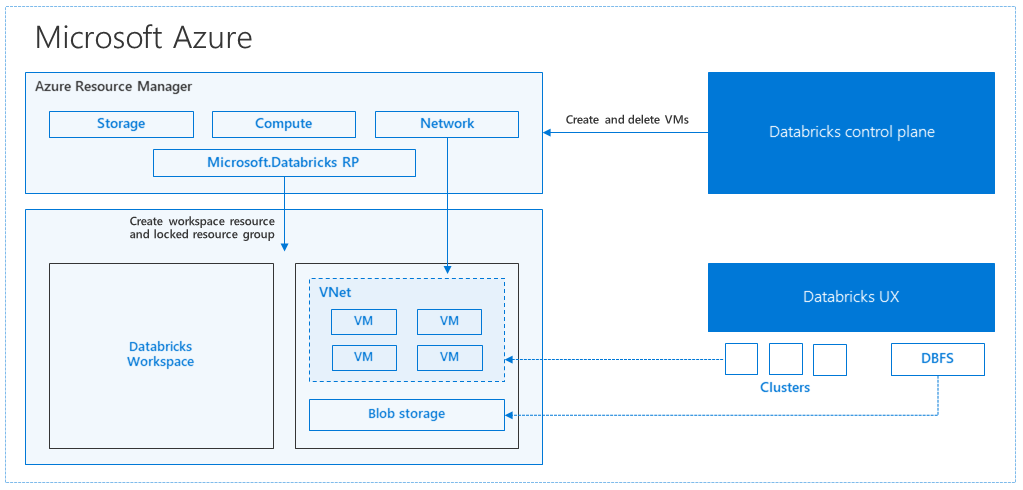
Hoe Azure clusterbronnen beheert
Wanneer u een Azure Databricks-werkruimte maakt, wordt een Databricks-apparaat geïmplementeerd als een Azure-resource in uw abonnement. Wanneer u een cluster in de werkruimte maakt, geeft u de typen en grootten op van de virtuele machines (VM's) die moeten worden gebruikt voor zowel het stuurprogramma als de werkrolknooppunten, en enkele andere configuratieopties, maar Azure Databricks beheert alle andere aspecten van het cluster.
Het Databricks-apparaat wordt in Azure geïmplementeerd als een beheerde resourcegroep binnen uw abonnement. Deze resourcegroep bevat de stuurprogramma- en werkrol-VM's voor uw clusters, samen met andere vereiste resources, waaronder een virtueel netwerk, een beveiligingsgroep en een opslagaccount. Alle metagegevens voor uw cluster, zoals geplande taken, worden opgeslagen in een Azure Database met geo-replicatie voor fouttolerantie.
Intern wordt Azure Kubernetes Service (AKS) gebruikt om de Azure Databricks-besturingsvlak en gegevensvlakken uit te voeren via containers die worden uitgevoerd op de nieuwste generatie Azure-hardware (Dv3-VM's), met NvMe-SDK's die 100uslatentie kunnen veroorzaken op virtuele Azure-machines met versneld netwerken. Azure Databricks maakt gebruik van deze functies van Azure om de Prestaties van Spark verder te verbeteren. Nadat de services in uw beheerde resourcegroep gereed zijn, kunt u het Databricks-cluster beheren via de gebruikersinterface van Azure Databricks en via functies zoals automatisch schalen en automatisch beëindigen.
Notitie
U kunt uw cluster ook koppelen aan een groep niet-actieve knooppunten om de opstarttijd van het cluster te verminderen. Zie Pools in de documentatie van Azure Databricks voor meer informatie.