Kennismaken met Spark
Voor een beter inzicht in het verwerken en analyseren van gegevens met Apache Spark in Azure Databricks is het belangrijk om inzicht te krijgen in de onderliggende architectuur.
Overzicht op hoog niveau
Op hoog niveau wordt de Azure Databricks-service gestart en beheert Apache Spark-clusters binnen uw Azure-abonnement. Apache Spark-clusters zijn groepen computers die worden behandeld als één computer en verwerken de uitvoering van opdrachten die zijn uitgegeven vanuit notebooks. Met clusters kan de verwerking van gegevens op veel computers worden geparallelliseerd om de schaal en prestaties te verbeteren. Ze bestaan uit een Spark-stuurprogramma en werkknooppunten. Het stuurprogrammaknooppunt verzendt werk naar de werkknooppunten en geeft hen de opdracht om gegevens op te halen uit een opgegeven gegevensbron.
In Databricks is de notebookinterface doorgaans het stuurprogrammaprogramma. Dit stuurprogrammaprogramma bevat de hoofdlus voor het programma en maakt gedistribueerde gegevenssets op het cluster en past vervolgens bewerkingen toe op deze gegevenssets. Stuurprogrammaprogramma's hebben toegang tot Apache Spark via een SparkSession-object , ongeacht de implementatielocatie.
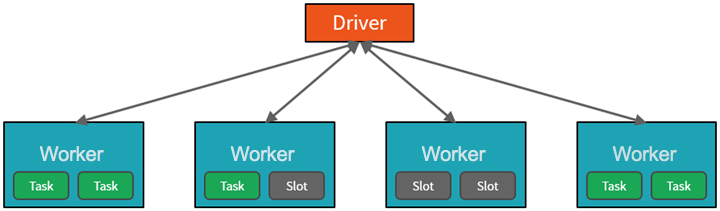
Microsoft Azure beheert het cluster en schaalt het automatisch op basis van uw gebruik en de instelling die wordt gebruikt bij het configureren van het cluster. Automatische beëindiging kan ook worden ingeschakeld, waardoor Azure het cluster kan beëindigen na een opgegeven aantal minuten van inactiviteit.
Spark-taken in detail
Werk dat naar het cluster wordt verzonden, wordt gesplitst in zoveel onafhankelijke taken als nodig is. Dit is hoe werk wordt verdeeld over de knooppunten van het cluster. Taken worden verder onderverdeeld in taken. De invoer voor een taak wordt gepartitioneerd in een of meer partities. Deze partities zijn de werkeenheid voor elke site. Tussen taken moeten partities mogelijk opnieuw worden georganiseerd en gedeeld via het netwerk.
Het geheim voor de hoge prestaties van Spark is parallellisme. Verticaal schalen (door resources toe te voegen aan één computer) is beperkt tot een eindige hoeveelheid RAM-geheugen, threads en CPU-snelheden. Clusters worden echter horizontaal geschaald en worden zo nodig nieuwe knooppunten aan het cluster toegevoegd.
Spark parallelliseert taken op twee niveaus:
- Het eerste niveau van parallelle uitvoering is de executor : een virtuele Java-machine (JVM) die wordt uitgevoerd op een werkknooppunt, meestal één exemplaar per knooppunt.
- Het tweede niveau van parallelle uitvoering is de sleuf , waarvan het aantal wordt bepaald door het aantal kernen en CPU's van elk knooppunt.
- Elke uitvoerder heeft meerdere sites waaraan geparallelliseerde taken kunnen worden toegewezen.
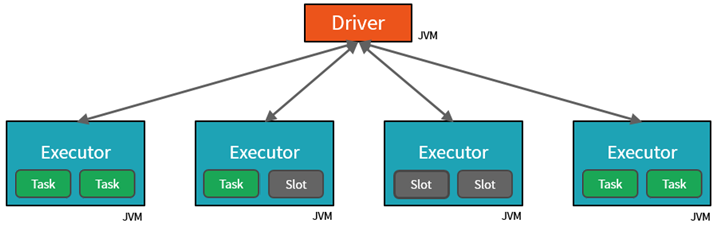
De JVM is natuurlijk meerdere threads, maar één JVM, zoals de JVM die het werk aan de bestuurder coördineert, heeft een eindige bovengrens. Door het werk op te splitsen in taken, kan het stuurprogramma werkeenheden toewijzen aan *sleuven in de uitvoerders op werkknooppunten voor parallelle uitvoering. Daarnaast bepaalt het stuurprogramma hoe de gegevens moeten worden gepartitioneerde, zodat deze kunnen worden gedistribueerd voor parallelle verwerking. Het stuurprogramma wijst dus een partitie met gegevens toe aan elke taak, zodat elke taak weet welk stukje gegevens het moet verwerken. Zodra de taak is gestart, wordt de partitie opgehaald van de gegevens die eraan zijn toegewezen.
Taken en fasen
Afhankelijk van het werk dat wordt uitgevoerd, zijn mogelijk meerdere geparallelliseerde taken vereist. Elke taak wordt onderverdeeld in fasen. Een nuttige analogie is om zich voor te stellen dat de taak is om een huis te bouwen:
- De eerste fase zou zijn om de basis te leggen.
- De tweede fase zou zijn om de muren op te zetten.
- De derde fase zou zijn om het dak toe te voegen.
Een poging om een van deze stappen uit volgorde uit te voeren, is niet logisch en is in feite onmogelijk. Op dezelfde manier breekt Spark elke taak in fasen om ervoor te zorgen dat alles in de juiste volgorde wordt uitgevoerd.
Modulariteit
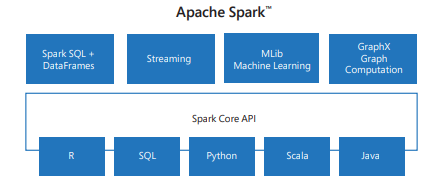
Spark bevat bibliotheken voor taken, variërend van SQL tot streaming en machine learning, waardoor het een hulpprogramma is voor gegevensverwerkingstaken. Enkele van de Spark-bibliotheken zijn:
- Spark SQL: Voor het werken met gestructureerde gegevens.
- SparkML: Voor machine learning.
- GraphX: Voor grafiekverwerking.
- Spark Streaming: voor realtime gegevensverwerking.
Compatibiliteit
Spark kan worden uitgevoerd op verschillende gedistribueerde systemen, waaronder Hadoop YARN, Apache Mesos, Kubernetes of Spark's eigen clustermanager. Het leest ook van en schrijft naar diverse gegevensbronnen, zoals HDFS, Cassandra, HBase en Amazon S3.