Gegevens visualiseren met Spark
Een van de meest intuïtieve manieren om de resultaten van gegevensquery's te analyseren, is door ze te visualiseren als grafieken. Notebooks in Azure Synapse Analytics bieden enkele eenvoudige grafiekmogelijkheden in de gebruikersinterface en wanneer deze functionaliteit niet biedt wat u nodig hebt, kunt u een van de vele Python-grafische bibliotheken gebruiken om gegevensvisualisaties in het notebook te maken en weer te geven.
Ingebouwde notebookgrafieken gebruiken
Wanneer u een dataframe weergeeft of een SQL-query uitvoert in een Spark-notebook in Azure Synapse Analytics, worden de resultaten weergegeven onder de codecel. Standaard worden resultaten weergegeven als een tabel, maar u kunt de resultatenweergave ook wijzigen in een grafiek en de grafiekeigenschappen gebruiken om aan te passen hoe de grafiek de gegevens visualiseert, zoals hier wordt weergegeven:
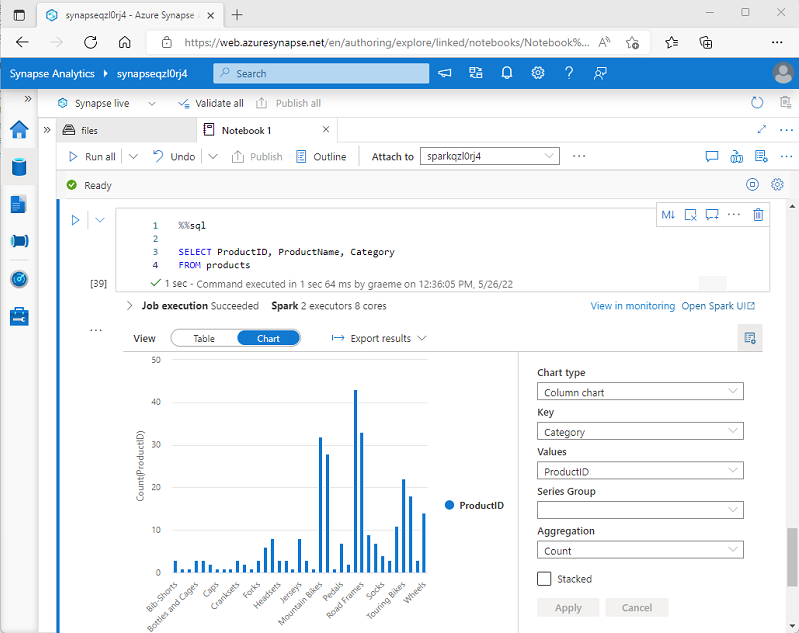
De ingebouwde grafiekfunctionaliteit in notebooks is handig wanneer u werkt met resultaten van een query die geen bestaande groeperingen of aggregaties bevat en u snel de gegevens visueel wilt samenvatten. Als u meer controle wilt hebben over de indeling van de gegevens of om waarden weer te geven die u al in een query hebt samengevoegd, kunt u overwegen een grafisch pakket te gebruiken om uw eigen visualisaties te maken.
Grafische pakketten gebruiken in code
Er zijn veel grafische pakketten die u kunt gebruiken om gegevensvisualisaties in code te maken. Python ondersteunt met name een grote selectie pakketten; de meeste zijn gebouwd op basis van de Matplotlib-bibliotheek . De uitvoer van een grafische bibliotheek kan worden weergegeven in een notebook, zodat u eenvoudig code kunt combineren om gegevens op te nemen en te bewerken met inlinegegevensvisualisaties en Markdown-cellen om commentaar te bieden.
U kunt bijvoorbeeld de volgende PySpark-code gebruiken om gegevens van de hypothetische producten die eerder in deze module zijn verkend, samen te voegen en Matplotlib te gebruiken om een grafiek te maken op basis van de geaggregeerde gegevens.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
De Matplotlib-bibliotheek vereist dat gegevens zich in een Pandas-gegevensframe bevinden in plaats van een Spark-gegevensframe, dus de toPandas-methode wordt gebruikt om deze te converteren. De code maakt vervolgens een afbeelding met een opgegeven grootte en plot een staafdiagram met een aangepaste eigenschapsconfiguratie voordat de resulterende plot wordt weergegeven.
De grafiek die door de code wordt geproduceerd, ziet er ongeveer als volgt uit:
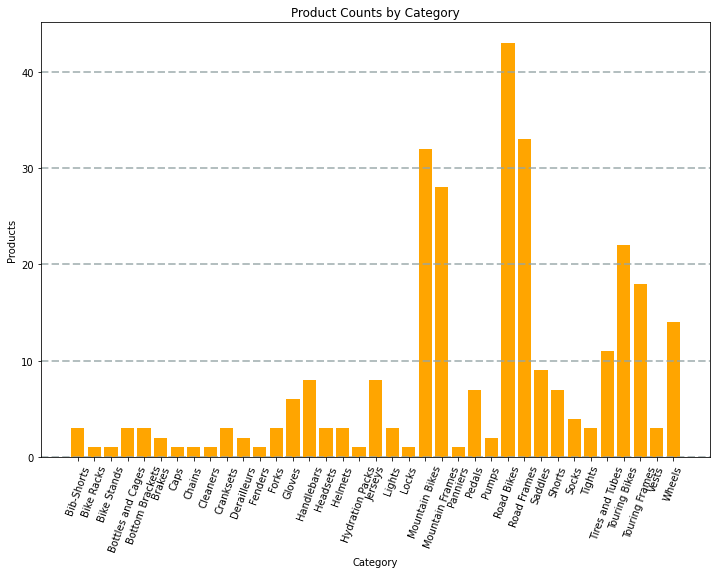
U kunt de Matplotlib-bibliotheek gebruiken om allerlei soorten grafieken te maken; of, indien gewenst, kunt u andere bibliotheken zoals Seaborn gebruiken om zeer aangepaste grafieken te maken.