Kennismaken met Apache Spark
Apache Spark is een gedistribueerd framework voor gegevensverwerking dat grootschalige gegevensanalyse mogelijk maakt door werk te coördineren op meerdere verwerkingsknooppunten in een cluster.
Hoe Spark werkt
Apache Spark-toepassingen worden uitgevoerd als onafhankelijke sets processen in een cluster, gecoördineerd door het SparkContext-object in uw hoofdprogramma (het stuurprogrammaprogramma genoemd). SparkContext maakt verbinding met clusterbeheer, waarmee resources worden toegewezen aan toepassingen met behulp van een implementatie van Apache Hadoop YARN. Zodra er verbinding is gemaakt, verkrijgt Spark uitvoerders op knooppunten in het cluster om uw toepassingscode uit te voeren.
SparkContext voert de hoofdfunctie en parallelle bewerkingen uit op de clusterknooppunten en verzamelt vervolgens de resultaten van de bewerkingen. De knooppunten lezen en schrijven gegevens van en naar het bestandssysteem en cache getransformeerde gegevens in het geheugen als Resilient Distributed Datasets (RDD's ).
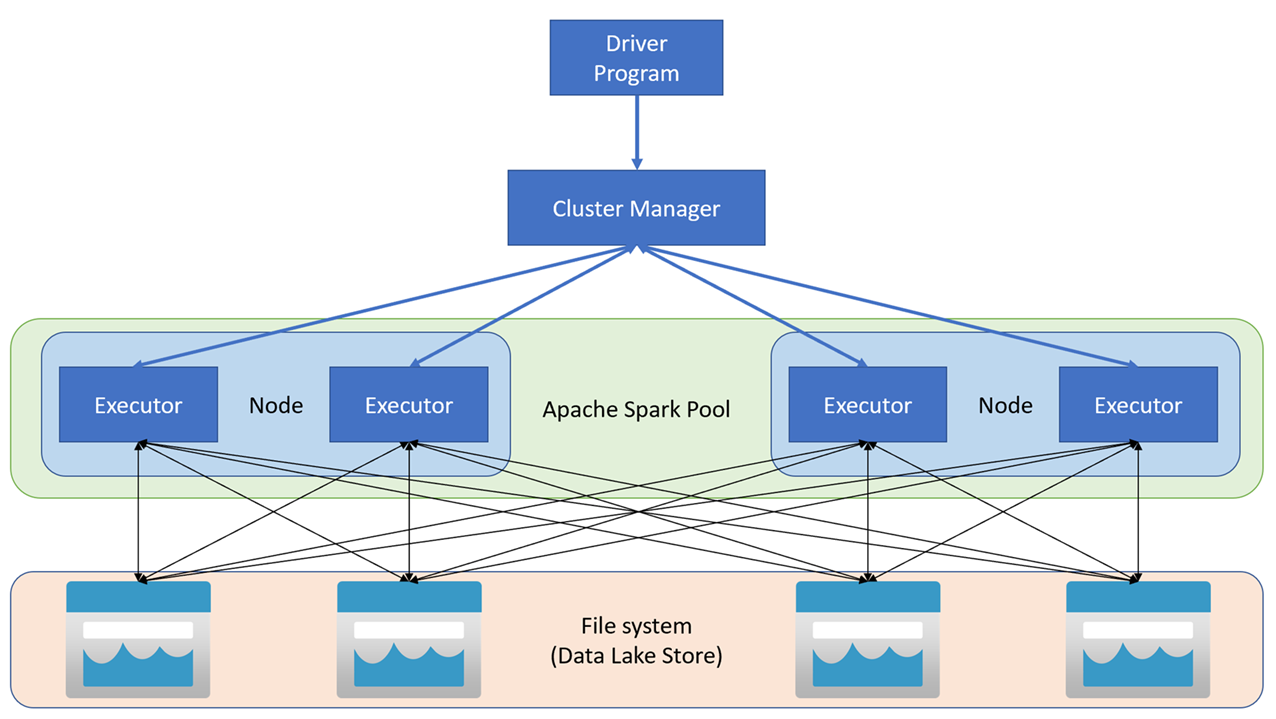
SparkContext is verantwoordelijk voor het converteren van een toepassing naar een gerichte acyclische grafiek (DAG). De graaf bestaat uit afzonderlijke taken die worden uitgevoerd in een uitvoerproces op de knooppunten. Elke toepassing krijgt zijn eigen executorprocessen, die voor de duur van de gehele toepassing blijven en taken uitvoeren in meerdere threads.
Spark-pools in Azure Synapse Analytics
In Azure Synapse Analytics wordt een cluster geïmplementeerd als een Spark-pool, die een runtime biedt voor Spark-bewerkingen. U kunt een of meer Spark-pools maken in een Azure Synapse Analytics-werkruimte met behulp van Azure Portal of in Azure Synapse Studio. Wanneer u een Spark-pool definieert, kunt u configuratieopties voor de pool opgeven, waaronder:
- Een naam voor de Spark-pool.
- De grootte van de virtuele machine (VM) die wordt gebruikt voor de knooppunten in de pool, inclusief de optie voor het gebruik van hardware versnelde GPU-knooppunten.
- Het aantal knooppunten in de pool en of de poolgrootte vast is of afzonderlijke knooppunten dynamisch online kunnen worden gebracht om het cluster automatisch te schalen . In dat geval kunt u het minimum- en maximumaantal actieve knooppunten opgeven.
- De versie van de Spark Runtime die in de pool moet worden gebruikt. Hiermee worden de versies van afzonderlijke onderdelen, zoals Python, Java en andere onderdelen, gedicteerd die worden geïnstalleerd.
Tip
Zie configuratieopties voor Apache Spark-pools in Azure Synapse Analytics in de documentatie van Azure Synapse Analytics voor meer informatie over configuratieopties voor Spark-pools.
Spark-pools in een Azure Synapse Analytics-werkruimte zijn serverloos . Ze starten op aanvraag en stoppen wanneer ze niet actief zijn.