Problemen met netwerken oplossen met behulp van metrische gegevens en logboeken van Network Watcher
Als u snel een probleem wilt vaststellen, moet u de informatie die beschikbaar is in de logboeken van Azure Network Watcher begrijpen.
In uw technische onderneming wilt u er zeker van zijn dat uw medewerkers zo weinig mogelijk tijd nodig hebben om een probleem met de netwerkconfiguratie op te lossen. U wilt er zeker van zijn dat ze weten welke informatie beschikbaar is in welke logboeken.
In deze module gaat u zich richten op stroomlogboeken, diagnostische logboeken en verkeersanalyses. U leert hoe u met deze hulpprogramma's problemen met het Azure-netwerk kunt oplossen.
Gebruik en quota
U kunt elke Microsoft Azure-resource gebruiken tot het quotum wordt bereikt. Elk abonnement heeft afzonderlijke quota en het gebruik wordt bijgehouden per abonnement. Er is slechts één exemplaar van Network Watcher vereist per abonnement per regio. Dit exemplaar geeft u een weergave van het gebruik en de quota, zodat u kunt zien of u risico loopt om een quotum te overschrijden.
Als u de gegevens over gebruik en quota wilt weergeven, gaat u naar Alle services>Netwerken>Network Watcher en selecteert u vervolgens Gebruik en quota. U ziet gedetailleerde gegevens op basis van het gebruik en de locatie van de resource. Gegevens voor de volgende metrische gegevens worden vastgelegd:
- Netwerkinterfaces
- Netwerkbeveiligingsgroepen (NSG's)
- Virtuele netwerken
- Openbare IP-adressen
Hier volgt een voorbeeld waarin het gebruik en de quota in de portal worden weergegeven:

Logboeken
Diagnostische logboeken van netwerken bieden gedetailleerde gegevens. U gebruikt deze gegevens om de connectiviteits- en prestatieproblemen beter te begrijpen. Er zijn drie hulpprogramma's voor logboekweergave in Network Watcher:
- NSG-stroomlogboeken
- Diagnostische logboeken
- Verkeersanalyse
Laten we elk van deze hulpprogramma's eens bekijken.
NSG-stroomlogboeken
In NSG-stroomlogboeken kunt u informatie bekijken over inkomend en uitgaand IP-verkeer in netwerkbeveiligingsgroepen. Stroomlogboeken tonen uitgaande en binnenkomende stromen per regel, op basis van de netwerkadapter waarop de stroom van toepassing is. In NSG-stroomlogboeken wordt weergegeven of verkeer is toegestaan of geweigerd op basis van de 5-tuple-gegevens die zijn vastgelegd. Deze informatie omvat:
- Bron-IP
- Bronpoort
- Doel-IP
- Doelpoort
- Protocol
Dit diagram toont de werkstroom die de NSG volgt.
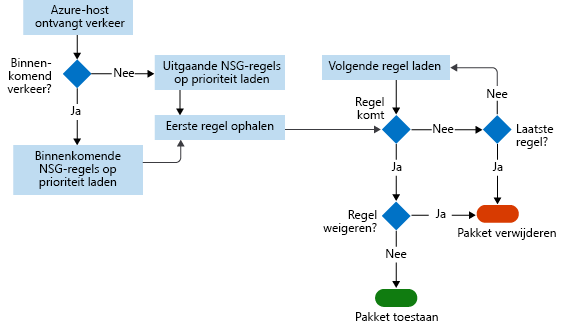
In stroomlogboeken worden gegevens in een JSON-bestand opgeslagen. Het kan lastig zijn om inzicht te krijgen in deze gegevens door handmatig de logboekbestanden te doorzoeken, met name als u een grote infrastructuurimplementatie in Azure hebt. Gebruik Power BI om dit probleem op te lossen.
In Power BI kunt u NSG-stroomlogboeken op veel manieren visualiseren. Voorbeeld:
- Top Talkers (IP-adres)
- Stromen op richting (inkomend en uitgaand)
- Stromen op beslissing (toegestaan en geweigerd)
- Stromen op doelpoort
U kunt ook opensource-hulpprogramma's gebruiken voor het analyseren van uw logboeken, zoals Elastic Stack, Grafana en Graylog.
Notitie
NSG-stroomlogboeken bieden geen ondersteuning voor opslagaccounts op de klassieke Azure-portal.
Diagnostische logboeken
In Network Watcher vormen diagnostische logboeken een centrale locatie om logboeken in en uit te schakelen voor Azure-netwerkresources. Dit zijn onder andere resources zoals NSG's, openbare IP-adressen, load balancers en app-gateways. Nadat u de logboeken hebt ingeschakeld waarin u geïnteresseerd bent, kunt u de hulpprogramma's gebruiken om logboekvermeldingen op te vragen en weer te geven.
U kunt diagnostische logboeken importeren in Power BI en andere hulpprogramma's om ze te analyseren.
Verkeersanalyse
Gebruik Traffic Analytics om de activiteit van gebruikers en toepassingen in uw cloudnetwerken te onderzoeken.
Het hulpprogramma geeft inzicht in netwerkactiviteit in verschillende abonnementen. U kunt beveiligingsdreigingen diagnosticeren, zoals open poorten, VM's die communiceren met netwerken waarvan bekend is dat deze beschadigd zijn, en verkeersstroompatronen. Met Traffic Analytics worden NSG-stroomlogboeken in meerdere Azure-regio's en -abonnementen geanalyseerd. U kunt de gegevens gebruiken om de netwerkprestaties te optimaliseren.
Voor dit hulpprogramma is een logboekanalyse vereist. Er moet zich een Log Analytics-werkruimte in een ondersteunde regio bevinden.
Use-casescenario's
Laten we eens kijken naar enkele gebruiksscenario's waarbij metrische gegevens en logboeken van Azure Network Watcher handig kunnen zijn.
Klantrapporten over trage prestaties
Voor het oplossen van problemen ten aanzien van trage prestaties moet u de grondoorzaak van het probleem bepalen:
- Is er te veel verkeer dat de server beperkt?
- Is de VM-grootte geschikt voor de taak?
- Zijn de drempelwaarden voor schaalbaarheid correct ingesteld?
- Zijn er schadelijke aanvallen aan de gang?
- Is de VM-opslagconfiguratie correct?
Controleer eerst of de VM-grootte geschikt is voor de taak. Schakel vervolgens Azure Diagnostics in op de VM om meer gedetailleerde gegevens te verkrijgen over specifieke metrische gegevens, zoals CPU-gebruik en geheugengebruik. Als u diagnostische gegevens over de virtuele machine via de portal wilt inschakelen, gaat u naar de virtuele machine, selecteert u Diagnostische instellingen en schakelt u Diagnostische gegevens in.
We gaan ervan uit dat u een VM hebt die prima draait. De prestaties van de virtuele machine zijn echter achteruitgegaan. U moet de vastgelegde gegevens controleren om te bepalen of er sprake is van knelpunten in resources.
Begin met een tijdsbereik van vastgelegde gegevens vóór, tijdens en na het gemelde probleem om een nauwkeurig beeld te krijgen van de prestaties. Deze grafieken kunnen ook handig zijn voor kruisverwijzingen naar verschillende resources in dezelfde periode. U controleert op knelpunten in:
- De CPU
- Het geheugen
- De schijf
De CPU
Wanneer u prestatieproblemen bekijkt, kunt u trends onderzoeken om te begrijpen of deze van invloed zijn op uw server. Gebruik de bewakingsgrafieken van de portal om trends te herkennen. U ziet wellicht verschillende soorten patronen in de bewakingsgrafieken:
- Geïsoleerde pieken. Een piek kan betrekking hebben op een geplande taak of een verwachte gebeurtenis. Als u weet wat deze taak is, wordt deze uitgevoerd op het vereiste prestatieniveau? Als de prestaties in orde zijn, hoeft u misschien de capaciteit niet meer te verhogen.
- Pieken omhoog en constant hoog. Een nieuwe werkbelasting kan deze trend veroorzaken. Schakel de bewaking in de VM in om te ontdekken welke processen de belasting veroorzaken. Het toegenomen verbruik kan worden veroorzaakt door inefficiënte code of het normale verbruik van de nieuwe workload. Als het verbruik normaal is, werkt het proces op het vereiste prestatieniveau?
- Constant hoog. Is uw virtuele machine altijd zo? Als dat het geval is, moet u de processen identificeren die de meeste resources verbruiken en overwegen om capaciteit toe te voegen.
- Neemt geleidelijk toe. Ziet u een constante toename in het verbruik? Als dit het geval is, kan deze trend duiden op inefficiënte code of een proces dat meer werkbelasting van gebruikers krijgt.
Als u wel een hoog CPU-gebruik constateert, kunt u:
- De schaal van de virtuele machine uitbreiden met meer kernen.
- Het probleem verder onderzoeken. De app en het proces opzoeken, en vervolgens het probleem overeenkomstig oplossen.
Als u de VM omhoog schaalt en de CPU nog steeds boven de 95 procent wordt uitgevoerd, zijn de prestaties van apps beter of is de doorvoer van apps hoger tot een acceptabel niveau? Als dat niet het geval is, moet u de problemen van die afzonderlijke app oplossen.
Het geheugen
U kunt de hoeveelheid geheugen die door de virtuele machine wordt gebruikt, weergeven. Logboeken helpen u de trend te begrijpen en inzien of deze overeenkomt met het moment waarop u problemen ziet. U mag niet minder dan 100 MB aan beschikbaar geheugen op elk gewenst moment hebben. Let op de volgende trends:
- Verbruik met pieken omhoog en constant hoog. Mogelijk worden slechte prestaties niet door een hoog geheugengebruik veroorzaakt. Sommige apps, zoals relationele database-engines, zijn standaard geheugenintensief. Als er echter meerdere veeleisende apps zijn, kan er mogelijk sprake zijn van slechte prestaties omdat de schijf wordt beperkt en gepagineerd door conflicterend geheugen. Deze processen zorgen voor een negatieve invloed op de prestaties.
- Verbruik neemt geleidelijk toe. Deze trend kan optreden wanneer een app moet opwarmen. Het komt veel voor wanneer database-engines worden gestart. Het kan echter ook duiden op een geheugenlek in een app.
- Gebruik van pagina- of wisselbestanden. Controleer of u het Windows-paginabestand of het Linux-wisselbestand, dat zich bevindt op /dev/sdb, intensief gebruikt.
Als u hoog geheugengebruik wilt verhelpen, kunt u denken aan de volgende oplossingen:
- Als u onmiddellijk het gebruik van paginabestanden wilt verminderen, kunt u de capaciteit van de virtuele machine verhogen voor extra geheugen en dit vervolgens controleren.
- Het probleem verder onderzoeken. Zoek de app of het proces dat het knelpunt veroorzaakt en los problemen op. Als u de app kent, controleer dan of u de geheugentoewijzing kunt limiteren.
De schijf
Netwerkprestaties kunnen ook betrekking hebben op het opslagsubsysteem van de virtuele machine. U kunt het opslagaccount voor de virtuele machine in de portal onderzoeken. Als u wilt zoeken naar problemen ten aanzien van de opslag, bekijkt u de metrische prestatiegegevens uit de diagnoses van het opslagaccount en de virtuele machine. Zoek naar de belangrijkste trends binnen een specifiek tijdsbereik op het moment dat het probleem optreedt.
- Als u op time-outs van Azure Storage wilt controleren, gebruikt u de metrische gegevens ClientTimeOutError, ServerTimeOutError, AverageE2ELatency, AverageServerLatency en TotalRequests. Als u waarden in de metrische timeOutError-gegevens ziet, duurde een I/O-bewerking te lang en is er een time-out opgetreden. Als u AverageServerLatency op hetzelfde moment als TimeOutErrors ziet toenemen, kan dit een platformprobleem zijn. Dien een aanvraag in bij de technische ondersteuning van Microsoft.
- Als u wilt controleren op beperkingen van Azure Storage, gebruikt u de metrische gegevens van ThrottlingError voor het opslagaccount. Als u beperkingen ziet, hebt u de limiet voor IOPS van het account bereikt. U kunt dit probleem controleren door de metrische gegevens van TotalRequests te onderzoeken.
Voor het oplossen van problemen ten aanzien van een hoog schijfgebruik en latentieproblemen:
- Optimaliseer de I/O van de VM door omhoog te schalen tot boven de VHD-limieten (virtuele harde schijf).
- Verhoog de doorvoer en verminder de latentie. Als u merkt dat u een latentiegevoelige app hebt en een hoge doorvoer nodig hebt, migreert u uw VHD's naar Azure Premium Storage.
Firewall-regels voor virtuele machines die het verkeer blokkeren
Als u problemen met een NSG-stroom wilt oplossen, gebruikt u het hulpprogramma IP-stroom controleren en NSG-stroomlogboeken van Network Watcher om te bepalen of er een NSG of UDR (User Defined Routing) is die de verkeersstroom verstoort.
Voer het hulpprogramma IP-stroom controleren uit en geef de lokale virtuele machine en de externe virtuele machine op. Nadat u Controleren hebt geselecteerd, voert Azure een logische test uit op de aanwezige regels. Als het resultaat is dat toegang is toegestaan, gebruikt u NSG-stroomlogboeken.
In de portal gaat u naar de NSG's. Selecteer onder de instellingen voor stroomlogboeken de optie Aan. Probeer nu opnieuw verbinding te maken met de virtuele machine. Gebruik Traffic Analytics van Network Watcher om de gegevens te visualiseren. Als het resultaat is dat toegang is toegestaan, is er geen blokkerende NSG-regel.
Als u op dit punt bent aangekomen en nog steeds geen diagnose hebt gemaakt van het probleem, kan er iets mis zijn met de externe VM. Schakel de firewall op de externe virtuele machine uit en test de connectiviteit opnieuw. Als u verbinding kunt maken met de externe virtuele machine terwijl de firewall is uitgeschakeld, controleert u de instellingen van de externe firewall. Schakel vervolgens de firewall opnieuw in.
Onvermogen van de front-end- en back-endsubnetten om te communiceren
Standaard kunnen alle subnetten communiceren in Azure. Als twee VM's op twee subnetten niet kunnen communiceren, moet er een configuratie zijn waardoor de communicatie wordt geblokkeerd. Voordat u de stroomlogboeken controleert, voert u het hulpprogramma IP-stroom controleren uit vanaf de front-end-VM naar de back-end-VM. Dit hulpprogramma voert een logische test uit op de regels van het netwerk.
Als hieruit blijkt dat een NSG op het back-endsubnet alle communicatie blokkeert, moet u die NSG opnieuw configureren. Uit veiligheidsoverwegingen moet u bepaalde communicatie met de front-end blokkeren, omdat de front-end wordt blootgesteld aan het openbare internet.
Door de communicatie met de back-end te blokkeren, beperkt u de mate van blootstelling in het geval van malware of een beveiligingsaanval. Als de NSG echter alles blokkeert, is deze onjuist geconfigureerd. Schakel de specifieke protocollen en poorten in die vereist zijn.