De oplossingsarchitectuur verkennen
Laten we de MLOps-architectuur (Machine Learning Operations) herzien om inzicht te krijgen in het doel van wat we proberen te bereiken.
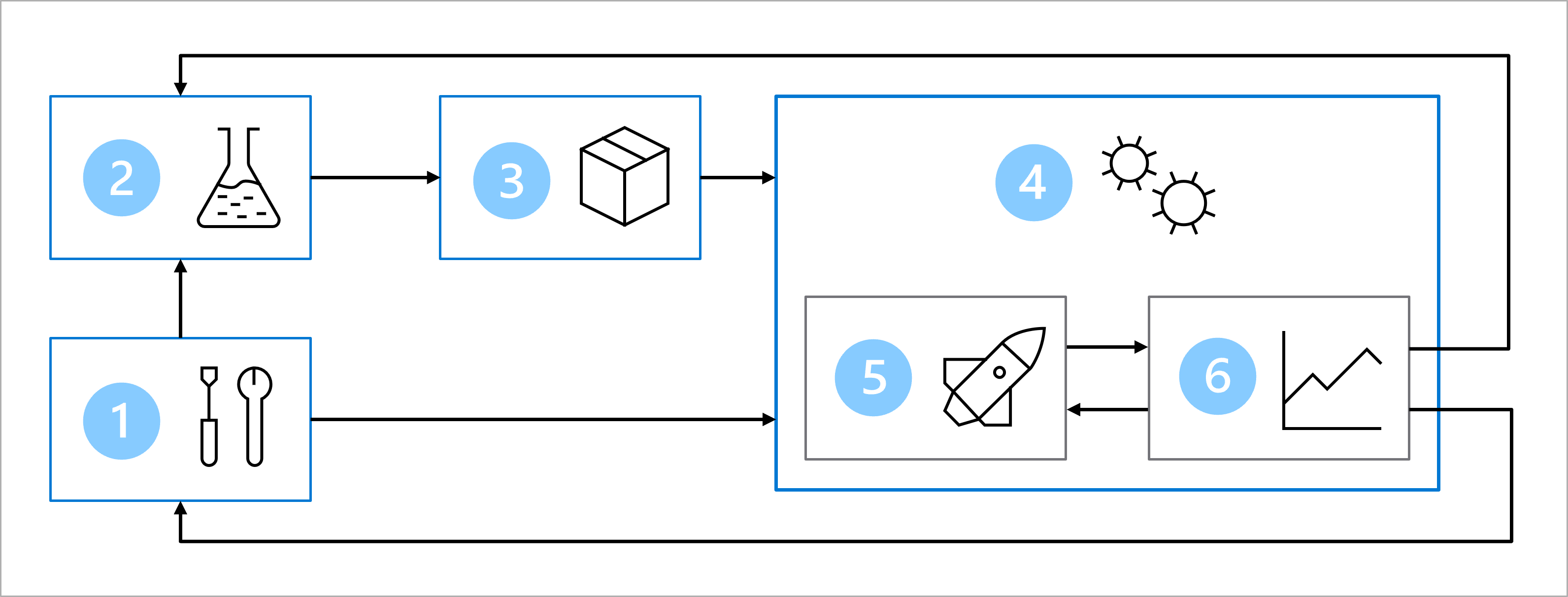
Stel dat u samen met het data science- en softwareontwikkelingsteam akkoord bent gegaan met de volgende architectuur voor het trainen, testen en implementeren van het diabetesclassificatiemodel:
Notitie
Het diagram is een vereenvoudigde weergave van een MLOps-architectuur. Als u een gedetailleerdere architectuur wilt bekijken, bekijkt u de verschillende use cases in de MLOps-oplossingsversneller (v2).
De architectuur bevat:
- Installatie: Maak alle benodigde Azure-resources voor de oplossing.
- Modelontwikkeling (interne lus): de gegevens verkennen en verwerken om het model te trainen en te evalueren.
- Continue integratie: het model verpakken en registreren.
- Modelimplementatie (outer loop): implementeer het model.
- Continue implementatie: test het model en promoot het naar de productieomgeving.
- Bewaking: model- en eindpuntprestaties bewaken.
Het data science-team is verantwoordelijk voor de modelontwikkeling. Het softwareontwikkelingsteam is verantwoordelijk voor het integreren van het geïmplementeerde model met de web-app die wordt gebruikt door beoefenaars om te beoordelen of een patiënt diabetes heeft. U bent verantwoordelijk voor het nemen van het model van modelontwikkeling tot modelimplementatie.
U verwacht dat het data science-team voortdurend wijzigingen voorstelt in de scripts die worden gebruikt om het model te trainen. Wanneer het trainingsscript wordt gewijzigd, moet u het model opnieuw trainen en het model opnieuw implementeren naar het bestaande eindpunt.
U wilt toestaan dat het data science-team experimenteert zonder de code aan te raken die gereed is voor productie. U wilt er ook voor zorgen dat nieuwe of bijgewerkte code automatisch wordt uitgevoerd op overeengekomen kwaliteitscontroles. Nadat u de code hebt gecontroleerd om het model te trainen, gebruikt u het bijgewerkte trainingsscript om een nieuw model te trainen en te implementeren.
Als u wijzigingen wilt bijhouden en uw code wilt controleren voordat u de productiecode bijwerkt, moet u met vertakkingen werken. U bent het eens met het data science-team dat telkens wanneer ze een wijziging willen aanbrengen, een functiebranch maken om een kopie van de code te maken en hun wijzigingen aan te brengen in de kopie.
Elke data scientist kan een functiebranch maken en daar werken. Zodra ze de code hebben bijgewerkt en die code de nieuwe productiecode willen maken, moeten ze een pull-aanvraag maken. In de pull-aanvraag is deze zichtbaar voor anderen wat de voorgestelde wijzigingen zijn, zodat anderen de mogelijkheid hebben om de wijzigingen te bekijken en te bespreken.
Wanneer er een pull-aanvraag wordt gemaakt, wilt u automatisch controleren of de code werkt en of de kwaliteit van de code voldoet aan de standaarden van uw organisatie. Nadat de code de kwaliteitscontroles heeft doorstaan, moet de hoofdgegevenswetenschapper de wijzigingen controleren en de updates goedkeuren voordat de pull-aanvraag kan worden samengevoegd en kan de code in de hoofdbranch dienovereenkomstig worden bijgewerkt.
Belangrijk
Niemand mag ooit wijzigingen naar de hoofdbranch pushen. Als u uw code wilt beveiligen, met name productiecode, wilt u afdwingen dat de hoofdvertakking alleen kan worden bijgewerkt via pull-aanvragen die moeten worden goedgekeurd.