Gegevensbestanden partitioneren
Partitioneren is een optimalisatietechniek waarmee Spark de prestaties op de werkknooppunten kan maximaliseren. Er kunnen meer prestatieverbeteringen worden bereikt bij het filteren van gegevens in query's door onnodige schijf-IO te elimineren.
Het uitvoerbestand partitioneren
Als u een dataframe wilt opslaan als een gepartitioneerde set bestanden, gebruikt u de partitionBy-methode bij het schrijven van de gegevens.
In het volgende voorbeeld wordt een afgeleid jaarveld gemaakt. Vervolgens wordt deze gebruikt om de gegevens te partitioneren.
from pyspark.sql.functions import year, col
# Load source data
df = spark.read.csv('/orders/*.csv', header=True, inferSchema=True)
# Add Year column
dated_df = df.withColumn("Year", year(col("OrderDate")))
# Partition by year
dated_df.write.partitionBy("Year").mode("overwrite").parquet("/data")
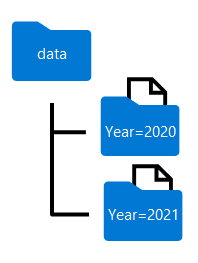
De mapnamen die worden gegenereerd bij het partitioneren van een dataframe, bevatten de partitioneringskolomnaam en -waarde in een kolom=waarde-indeling , zoals hier wordt weergegeven:
Notitie
U kunt de gegevens partitioneren op meerdere kolommen, wat resulteert in een hiërarchie van mappen voor elke partitiesleutel. U kunt bijvoorbeeld de volgorde in het voorbeeld per jaar en maand partitioneren, zodat de maphiërarchie een map bevat voor elke jaarwaarde, die op zijn beurt een submap voor elke maandwaarde bevat.
Parquet-bestanden filteren in een query
Wanneer u gegevens uit Parquet-bestanden leest in een dataframe, hebt u de mogelijkheid om gegevens op te halen uit elke map in de hiërarchische mappen. Dit filterproces wordt uitgevoerd met het gebruik van expliciete waarden en jokertekens voor de gepartitioneerde velden.
In het volgende voorbeeld haalt de volgende code de verkooporders op, die in 2020 zijn geplaatst.
orders_2020 = spark.read.parquet('/partitioned_data/Year=2020')
display(orders_2020.limit(5))
Notitie
De partitioneringskolommen die zijn opgegeven in het bestandspad worden weggelaten in het resulterende dataframe. De resultaten die door de voorbeeldquery worden geproduceerd, bevatten geen kolom Year . Alle rijen zijn afkomstig uit 2020.