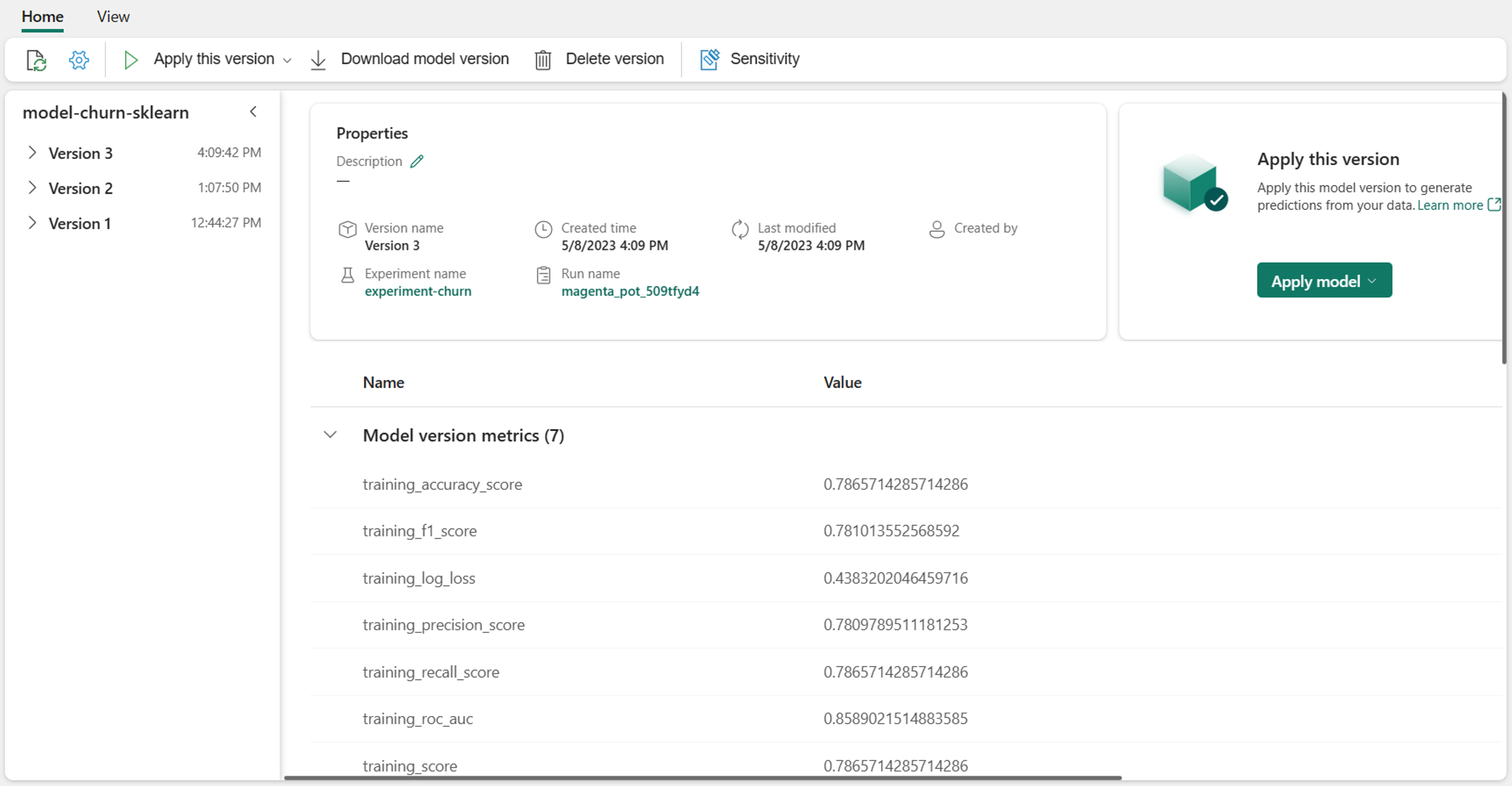
Modellen beheren in Microsoft Fabric
Dankzij de integratie van MLflow in Microsoft Fabric kunt u uw machine learning-modellen eenvoudig bijhouden en beheren.
Modelartefacten bijhouden met MLflow
Nadat u een model hebt getraind, wilt u het model gebruiken voor het scoren en genereren van nieuwe voorspellingen. Als u uw model eenvoudig wilt integreren, moet u uw model opslaan, zodat u het model in een andere omgeving kunt laden. Een veelvoorkomende benadering is het opslaan van een model als een pickle-bestand, een geserialiseerd object.
Notitie
De indeling van uw opgeslagen model is afhankelijk van het machine learning-framework dat u gebruikt. Wanneer u bijvoorbeeld een Deep Learning-model traint, kunt u ervoor kiezen om uw model op te slaan met behulp van de ONNX-indeling (Open Neural Network Exchange).
MLflow voegt nog een laag toe aan de uitvoer van uw model door het MLmodel-bestand toe te voegen. Het MLmodel-bestand geeft de metagegevens van het model op, zoals hoe en wanneer het model is getraind, evenals de verwachte invoer en uitvoer van het model.
Het MLmodel-bestand begrijpen
Wanneer u een model met MLflow aanmeldt, worden alle relevante modelassets opgeslagen in de model map met de uitvoering van uw experiment.
De model map bevat het MLmodel-bestand, één bron van waarheid over hoe het model moet worden geladen en verbruikt.
Het MLmodel-bestand kan het volgende omvatten:
artifact_path: Tijdens de training wordt het model geregistreerd bij dit pad.flavor: De machine learning-bibliotheek waarmee het model is gemaakt.model_uuid: de unieke id van het geregistreerde model.run_id: De unieke id van de taak die wordt uitgevoerd tijdens het maken van het model.signature: Hiermee geeft u het schema op van de invoer en uitvoer van het model:inputs: Geldige invoer voor het model. Bijvoorbeeld een subset van de trainingsgegevensset.outputs: Geldige modeluitvoer. Bijvoorbeeld modelvoorspellingen voor de invoergegevensset.
Stel dat u een regressiemodel hebt getraind om diabetes bij patiënten te voorspellen. Het geregistreerde MLmodel-bestand kan er als volgt uitzien:
artifact_path: model
flavors:
python_function:
env:
conda: conda.yaml
virtualenv: python_env.yaml
loader_module: mlflow.sklearn
model_path: model.pkl
predict_fn: predict
python_version: 3.10.10
sklearn:
code: null
pickled_model: model.pkl
serialization_format: cloudpickle
sklearn_version: 1.2.0
mlflow_version: 2.1.1
model_uuid: 8370150f4e07495794c3b80bcaf07e52
run_id: 14cdf02f-119b-4b8d-90f3-044987c29bce
signature:
inputs: '[{"type": "tensor", "tensor-spec": {"dtype": "float64", "shape": [-1, 10]}}]'
outputs: '[{"type": "tensor", "tensor-spec": {"dtype": "float64", "shape": [-1]}}]'
Wanneer u ervoor kiest om de autologgingfunctie van MLflow in Microsoft Fabric te gebruiken, wordt het MLmodel-bestand automatisch voor u gemaakt. Als u het bestand wilt wijzigen om het gedrag van het model te wijzigen tijdens het scoren, kunt u wijzigen hoe het MLmodel-bestand wordt vastgelegd.
Tip
Meer informatie over MLflow-modelbestanden en het aanpassen van de velden.
Modellen beheren in Microsoft Fabric
Wanneer u een model bijhoudt met MLflow tijdens de training in Microsoft Fabric, worden alle modelartefacten opgeslagen in de model map. U vindt de model map in de experimentuitvoering:
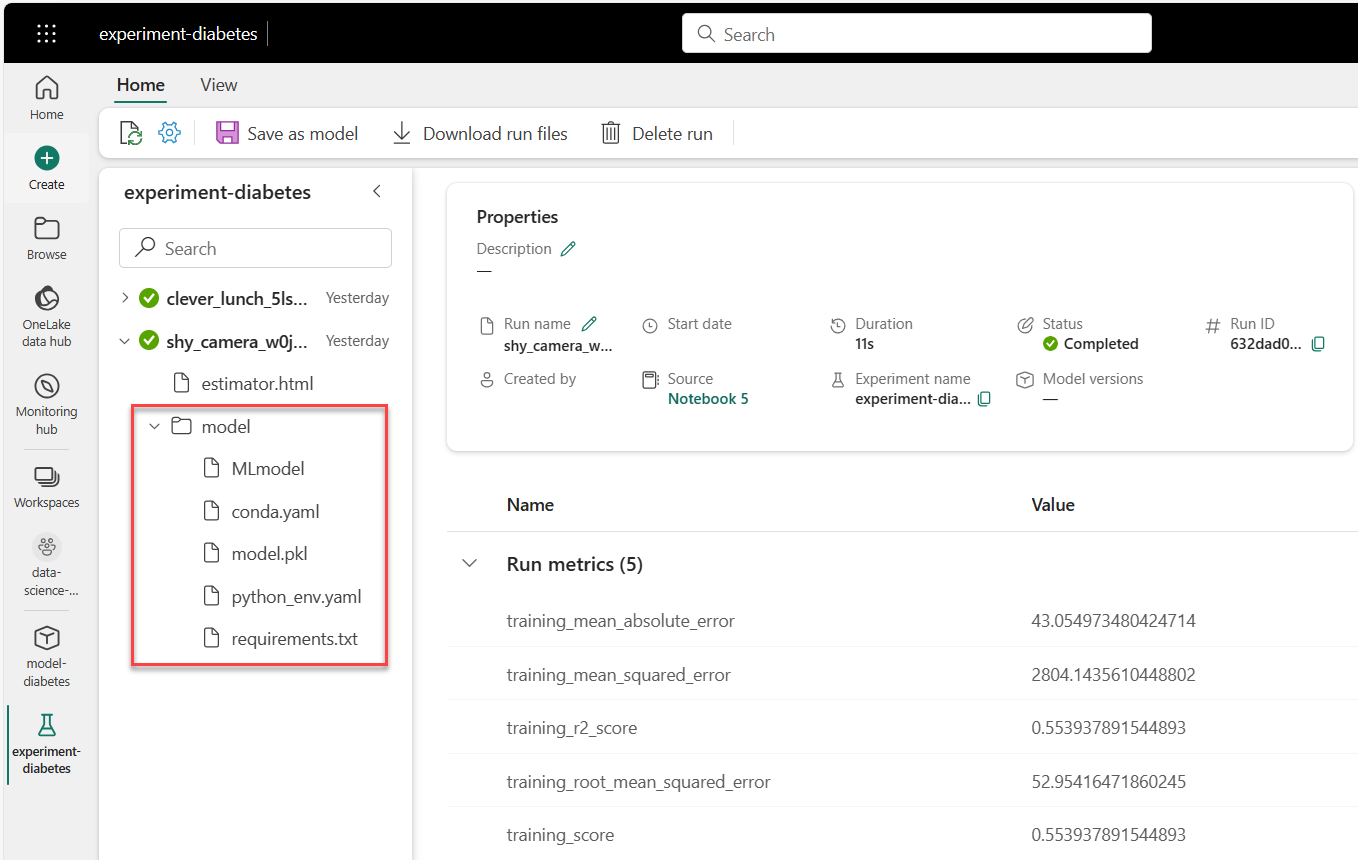
De modelmap bevat:
MLmodel: Bevat de metagegevens van het model.conda.yaml: Bevat de Anaconda-omgeving die nodig is om het model uit te voeren.model.pkl: Bevat het getrainde modelpython_env.yaml: Beschrijft de Python-omgeving die nodig is om het model uit te voeren. Verwijst naar hetrequirements.txtbestand.requirements.txt: bevat Python-pakketten die vereist zijn om het model uit te voeren.
Al deze modelartefacten zijn nodig wanneer u uw model wilt gebruiken om voorspellingen te genereren voor nieuwe gegevens.
Een model opslaan in uw werkruimte
Wanneer u het model kiest dat u wilt gebruiken, kunt u het model opslaan in de werkruimte tijdens de uitvoering van het experiment. Door een model op te slaan, maakt u een nieuw versiemodel in de werkruimte met alle modelartefacten en metagegevens.
Selecteer de experimentuitvoering die het model vertegenwoordigt dat u hebt getraind en selecteer de optie Opslaan om de uitvoering op te slaan als een model.
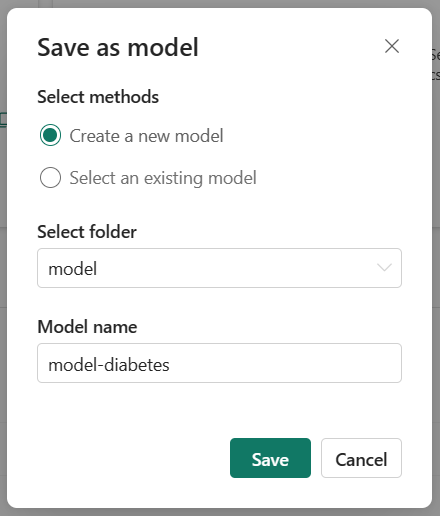
Als u een bestaand model selecteert, maakt u een nieuwe versie van een model onder dezelfde naam. Met modelversiebeheer kunt u modellen vergelijken die een vergelijkbaar doel hebben, waarna u het best presterende model kunt kiezen om voorspellingen te genereren.