Wat is classificatie?
Binaire classificatie is classificatie met twee categorieën. We kunnen bijvoorbeeld patiënten labelen als niet-diabetisch of diabetisch.
De klassevoorspelling wordt gedaan door de waarschijnlijkheid voor elke mogelijke klasse te bepalen als een waarde tussen 0 (onmogelijk) en 1 (zeker). De totale waarschijnlijkheid voor alle klassen is altijd 1, omdat de patiënt absoluut diabetisch of niet-diabetisch is. Dus, als de voorspelde kans van een patiënt diabetisch is 0,3, dan is er een overeenkomstige kans van 0,7 dat de patiënt niet diabetisch is.
Een drempelwaarde, vaak 0,5, wordt gebruikt om de voorspelde klasse te bepalen. Als de positieve klasse (in dit geval diabetisch) een voorspelde kans heeft die groter is dan de drempelwaarde, wordt een classificatie van diabetisch voorspeld.
Een classificatiemodel trainen en evalueren
Classificatie is een voorbeeld van een machine learning-techniek onder supervisie , wat betekent dat het afhankelijk is van gegevens die bekende functiewaarden en bekende labelwaarden bevatten. In dit voorbeeld zijn de functiewaarden diagnostische metingen voor patiënten en zijn de labelwaarden een classificatie van niet-diabetisch of diabetisch. Een classificatie-algoritme wordt gebruikt om een subset van de gegevens in een functie aan te passen waarmee de waarschijnlijkheid voor elk klasselabel kan worden berekend op basis van de functiewaarden. De resterende gegevens worden gebruikt om het model te evalueren door de voorspellingen te vergelijken die worden gegenereerd van de functies met de bekende klasselabels.
Een eenvoudig voorbeeld
Laten we een voorbeeld bekijken om de belangrijkste principes uit te leggen. Stel dat we de volgende patiëntgegevens hebben, die bestaan uit één functie (bloedglucoseniveau) en een klasselabel 0 voor niet-diabetische, 1 voor diabetische.
| Bloedglucose | Suikerpatiënt |
|---|---|
| 82 | 0 |
| 92 | 0 |
| 112 | 1 |
| 102 | 0 |
| 115 | 1 |
| 107 | 1 |
| 87 | 0 |
| 120 | 1 |
| 83 | 0 |
| 119 | 1 |
| 104 | 1 |
| 105 | 0 |
| 86 | 0 |
| 109 | 1 |
We gebruiken de eerste acht waarnemingen om een classificatiemodel te trainen en we beginnen met het plotten van de bloedglucosefunctie (x) en het voorspelde diabetische label (y).
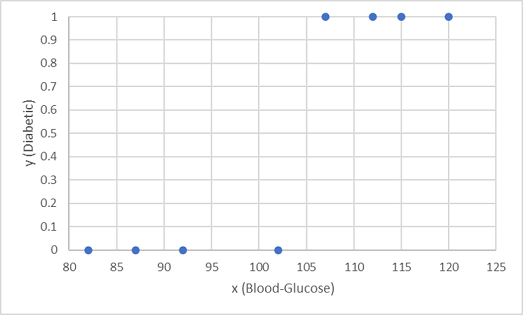
Wat we nodig hebben, is een functie die een waarschijnlijkheidswaarde voor y berekent op basis van x (met andere woorden, we hebben de functie f(x) = y nodig. U kunt in de grafiek zien dat patiënten met een laag bloedglucoseniveau allemaal niet-diabetisch zijn, terwijl patiënten met een hoger bloedglucoseniveau diabetisch zijn. Het lijkt erop dat hoe hoger het bloedglucosegehalte, hoe waarschijnlijker het is dat een patiënt diabetisch is, waarbij het buigpunt ergens tussen 100 en 110 ligt. We moeten een functie aanpassen die een waarde tussen 0 en 1 voor y berekent aan deze waarden.
Een dergelijke functie is een logistieke functie, die een sigmoidale (S-vormige) curve vormt.
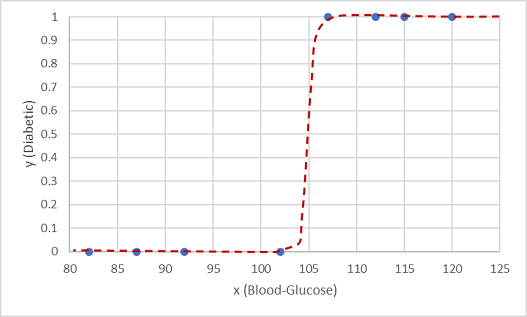
Nu kunnen we de functie gebruiken om een waarschijnlijkheidswaarde te berekenen die positief is, wat betekent dat de patiënt diabetisch is, van elke waarde van x door het punt op de functielijn voor x te vinden. We kunnen een drempelwaarde van 0,5 instellen als het afsluitpunt voor de voorspelling van het klasselabel.
We gaan dit testen met de twee gegevenswaarden die we hebben vastgehouden.
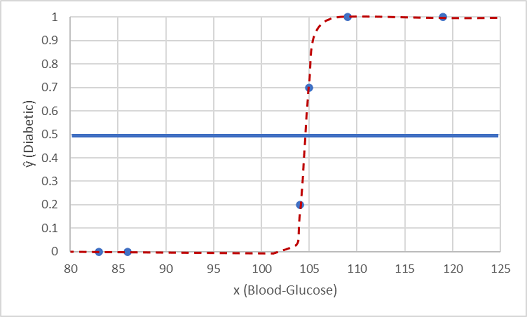
Punten die onder de drempelwaardelijn worden weergegeven, leveren een voorspelde klasse van 0 (niet-diabetisch) en punten boven de lijn worden voorspeld als 1 (diabetisch).
Nu kunnen we de labelvoorspellingen (ŷ of y-hat) vergelijken op basis van de logistieke functie die in het model is ingekapseld, met de werkelijke klasselabels (y).
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |