Gegevens indexeren met behulp van de Push-API van Azure AI Search
De REST API is de meest flexibele manier om gegevens naar een Azure AI Search-index te pushen. U kunt elke programmeertaal of interactief gebruiken met elke app die JSON-aanvragen naar een eindpunt kan posten.
Hier ziet u hoe u de REST API effectief kunt gebruiken en de beschikbare bewerkingen kunt verkennen. Vervolgens bekijkt u .NET Core-code en ziet u hoe u grote hoeveelheden gegevens kunt optimaliseren via de API.
Ondersteunde REST API-bewerkingen
Er zijn twee ondersteunde REST API's van AI Search. Zoek- en beheer-API's. Deze module is gericht op de REST API's voor zoeken die bewerkingen bieden voor vijf functies van zoeken:
| Functie | Operations |
|---|---|
| Index | Maken, verwijderen, bijwerken en configureren. |
| Document | Ophalen, toevoegen, bijwerken en verwijderen. |
| Indexeerfunctie | Configureer gegevensbronnen en planning voor beperkte gegevensbronnen. |
| Vaardighedenset | Ophalen, maken, verwijderen, weergeven en bijwerken. |
| Synoniemenkaart | Ophalen, maken, verwijderen, weergeven en bijwerken. |
De REST API voor zoeken aanroepen
Als u een van de zoek-API's wilt aanroepen, moet u het volgende doen:
- Gebruik het HTTPS-eindpunt (via de standaardpoort 443) van uw zoekservice. U moet een API-versie in de URI opnemen.
- De aanvraagheader moet een api-sleutelkenmerk bevatten.
Als u het eindpunt, de API-versie en de API-sleutel wilt vinden, gaat u naar Azure Portal.

Navigeer in de portal naar uw zoekservice en selecteer Search Explorer. Het REST API-eindpunt bevindt zich in het veld Aanvraag-URL . Het eerste deel van de URL is het eindpunt (bijvoorbeeld https://azsearchtest.search.windows.net) en de querytekenreeks toont de api-version (bijvoorbeeld api-version=2023-07-01-Preview).

Als u de api-key optie aan de linkerkant wilt vinden, selecteert u Sleutels. De primaire of secundaire beheersleutel kan worden gebruikt als u de REST API gebruikt om meer te doen dan alleen een query op de index uit te voeren. Als u alleen een index wilt doorzoeken, kunt u querysleutels maken en gebruiken.
Als u gegevens in een index wilt toevoegen, bijwerken of verwijderen, moet u een beheersleutel gebruiken.
Gegevens toevoegen aan een index
Gebruik een HTTP POST-aanvraag met behulp van de functie indexen in deze indeling:
POST https://[service name].search.windows.net/indexes/[index name]/docs/index?api-version=[api-version]
De hoofdtekst van uw aanvraag moet het REST-eindpunt laten weten welke actie moet worden uitgevoerd op het document, welk document ook moet worden toegepast en welke gegevens moeten worden gebruikt.
De JSON moet de volgende indeling hebben:
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (key/value pairs matching index schema)
...
},
...
]
}
| Actie | Beschrijving |
|---|---|
| uploaden | Net als bij een upsert in SQL wordt het document gemaakt of vervangen. |
| Samenvoegen | Bij samenvoegen wordt een bestaand document bijgewerkt met de opgegeven velden. Samenvoegen mislukt als er geen document kan worden gevonden. |
| mergeOrUpload | Samenvoegen werkt een bestaand document bij met de opgegeven velden en uploadt het als het document niet bestaat. |
| verwijderen | Hiermee verwijdert u het hele document. U hoeft alleen de key_field_name op te geven. |
Als uw aanvraag is geslaagd, retourneert de API een statuscode van 200.
Notitie
Zie Documenten toevoegen, bijwerken of verwijderen (Azure AI Search REST API) voor een volledige lijst met alle antwoordcodes en foutberichten .
In dit voorbeeld uploadt JSON de klantrecord in de vorige les:
{
"value": [
{
"@search.action": "upload",
"id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": "1558"
},
"phoneNumbers": [
{
"phoneNumber": {
"type": "home",
"number": "+1 (830) 465-2965"
}
},
{
"phoneNumber": {
"type": "home",
"number": "+1 (889) 439-3632"
}
}
]
}
]
}
U kunt zoveel documenten toevoegen aan de waardematrix als u wilt. Voor optimale prestaties kunt u echter overwegen om de documenten in uw aanvragen te batcheren tot maximaal 1000 documenten of 16 MB in totale grootte.
.NET Core gebruiken om gegevens te indexeren
Gebruik voor de beste prestaties de nieuwste Azure.Search.Document clientbibliotheek, momenteel versie 11. U kunt de clientbibliotheek installeren met NuGet:
dotnet add package Azure.Search.Documents --version 11.4.0
Hoe uw index presteert, is gebaseerd op zes belangrijke factoren:
- De zoekservicelaag en hoeveel replica's en partities u hebt ingeschakeld.
- De complexiteit van het indexschema. Verminder het aantal eigenschappen (doorzoekbaar, facetable, sorteerbaar) dat elk veld heeft.
- Het aantal documenten in elke batch, de beste grootte is afhankelijk van het indexschema en de grootte van documenten.
- Hoe multithreaded uw benadering is.
- Afhandeling van fouten en beperking. Gebruik een strategie voor exponentieel uitstel voor opnieuw proberen.
- Probeer waar uw gegevens zich bevinden uw gegevens zo dicht mogelijk bij uw zoekindex te indexeren. Voer bijvoorbeeld uploads uit vanuit de Azure-omgeving.
Uw optimale batchgrootte instellen
Naarmate de beste batchgrootte wordt uitgewerkt, is dit een belangrijke factor om de prestaties te verbeteren. Laten we eens kijken naar een benadering in code.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
De aanpak is het vergroten van de batchgrootte en het bewaken van de tijd die nodig is om een geldig antwoord te ontvangen. De codelussen van 100 tot 1000, in 100 documentstappen. Voor elke batchgrootte wordt de documentgrootte, de tijd voor het ophalen van een antwoord en de gemiddelde tijd per MB uitgevoerd. Als u deze code uitvoert, krijgt u de volgende resultaten:
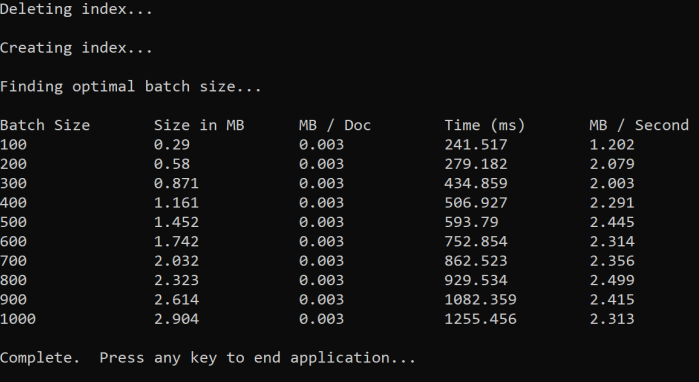
In het bovenstaande voorbeeld is de beste batchgrootte voor doorvoer 2,499 MB per seconde, 800 documenten per batch.
Een herhaalstrategie voor exponentieel uitstel implementeren
Als uw index aanvragen begint te beperken vanwege overbelastingen, reageert deze met een status van 503 (aanvraag geweigerd vanwege zware belasting) of 207 (sommige documenten zijn mislukt in de batch). U moet deze antwoorden afhandelen en een goede strategie is het uitstel. Terugzetten betekent dat het enige tijd onderbroken wordt voordat u uw aanvraag opnieuw probeert. Als u deze tijd voor elke fout verhoogt, wordt er exponentieel een back-up uitgevoerd.
Bekijk deze code:
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Met de code worden mislukte documenten in een batch bijgehouden. Als er een fout optreedt, wacht deze op een vertraging en verdubbelt de vertraging voor de volgende fout.
Ten slotte is er een maximum aantal nieuwe pogingen en als dit maximumaantal is bereikt, bestaat het programma.
Threading gebruiken om de prestaties te verbeteren
U kunt de app voor het uploaden van documenten voltooien door de bovenstaande back-offstrategie te combineren met een threadingbenadering. Hier volgt een voorbeeldcode:
public static async Task IndexDataAsync(SearchClient searchClient, List<Hotel> hotels, int batchSize, int numThreads)
{
int numDocs = hotels.Count;
Console.WriteLine("Uploading {0} documents...\n", numDocs.ToString());
DateTime startTime = DateTime.Now;
Console.WriteLine("Started at: {0} \n", startTime);
Console.WriteLine("Creating {0} threads...\n", numThreads);
// Creating a list to hold active tasks
List<Task<IndexDocumentsResult>> uploadTasks = new List<Task<IndexDocumentsResult>>();
for (int i = 0; i < numDocs; i += batchSize)
{
List<Hotel> hotelBatch = hotels.GetRange(i, batchSize);
var task = ExponentialBackoffAsync(searchClient, hotelBatch, i);
uploadTasks.Add(task);
Console.WriteLine("Sending a batch of {0} docs starting with doc {1}...\n", batchSize, i);
// Checking if we've hit the specified number of threads
if (uploadTasks.Count >= numThreads)
{
Task<IndexDocumentsResult> firstTaskFinished = await Task.WhenAny(uploadTasks);
Console.WriteLine("Finished a thread, kicking off another...");
uploadTasks.Remove(firstTaskFinished);
}
}
// waiting for the remaining results to finish
await Task.WhenAll(uploadTasks);
DateTime endTime = DateTime.Now;
TimeSpan runningTime = endTime - startTime;
Console.WriteLine("\nEnded at: {0} \n", endTime);
Console.WriteLine("Upload time total: {0}", runningTime);
double timePerBatch = Math.Round(runningTime.TotalMilliseconds / (numDocs / batchSize), 4);
Console.WriteLine("Upload time per batch: {0} ms", timePerBatch);
double timePerDoc = Math.Round(runningTime.TotalMilliseconds / numDocs, 4);
Console.WriteLine("Upload time per document: {0} ms \n", timePerDoc);
}
Deze code maakt gebruik van asynchrone aanroepen naar een functie ExponentialBackoffAsync waarmee de back-offstrategie wordt geïmplementeerd. U roept de functie aan met behulp van threads, bijvoorbeeld het aantal kernen dat uw processor heeft. Wanneer het maximum aantal threads is gebruikt, wacht de code totdat een thread is voltooid. Vervolgens wordt er een nieuwe thread gemaakt totdat alle documenten zijn geüpload.