Apache HBase beschrijven
Apache HBase is een opensource-NoSQL-database die is gebouwd op Apache Hadoop. HBase biedt willekeurige toegang en sterke consistentie voor grote hoeveelheden ongestructureerde en semi-gestructureerde gegevens in een schemaloze database die is georganiseerd door kolomfamilies. HDInsight 4.0 HBase-clusters worden geleverd met Apache HBase 2.1.6 en Apache Phoenix 5.
Vanuit het oogpunt van een gebruiker is HBase vergelijkbaar met een database. De gegevens worden opgeslagen in de rijen en kolommen van een tabel en de gegevens in een rij worden gegroepeerd op basis van de kolomfamilie. HBase is een database zonder schema in de zin dat zowel de kolommen als het type gegevens dat hierin wordt opgeslagen niet hoeven te worden gedefinieerd voordat u ze kunt gebruiken. De open-source code wordt lineair geschaald om petabytes aan gegevens op duizenden knooppunten te verwerken.
HBase heeft de volgende functies die het uniek maken
Consistente lees- en schrijfbewerkingen
Bewerkingen met lage latentie
Automatische sharding
Automatische regioserverfailovers
Hadoop/HDFS/MapReduce-integratie
Java-client-API
Ondersteunt Thrift en REST voor niet-Java front-ends
Cache- en bloeifilters blokkeren
Azure HDInsight HBase met Apache Phoenix biedt de volgende extra voordelen
SQL- en geen SQL-interfaces
Flexibele capaciteitsplanning
Wereldwijde distributie en replicatie met Azure-netwerken
Scheiding van compute en opslag
Nauw geïntegreerd met HDInsight Enterprise-beveiligingsfuncties
Met HDInsight HBase versnelde schrijfbewerkingen voor lees- en schrijfbewerkingen met een ultra lage latentie
Apache Phoenix voor realtime SQL, zoals het uitvoeren van query's
Met Azure HDInsight met HBase kunt u NoSQL-databases op grote schaal uitvoeren. Als Data-engineer voor een Contoso moet u benchmarktests kunnen uitvoeren om inzicht te hebben in de prestaties en schaal van HDInsight HBase voordat u het platform gebruikt voor bedrijfskritieke productiescenario's.
HBase in HDInsight wordt uitgevoerd met de scheiding van rekenkracht en opslag. HDInsight HBase-clusters zijn geconfigureerd voor het rechtstreeks opslaan van gegevens in Azure Storage, wat lage latentie en verbeterde elasticiteit biedt in prestatie- en kostenkeuzen. Met deze eigenschap kunnen klanten interactieve websites bouwen die werken met grote gegevenssets. Services bouwen die sensor- en telemetriegegevens van miljoenen eindpunten opslaan en deze gegevens analyseren met Hadoop-taken. HBase en Hadoop zijn goede uitgangspunten voor big data-projecten in Azure. Met de services kunnen realtime-toepassingen werken met grote gegevenssets. HDInsight HBase-implementaties maken gebruik van een uitschaalarchitectuur van HBase om automatische sharding van tabellen te bieden. Het biedt ook een sterke consistentie voor lees- en schrijfbewerkingen en automatische failover. De prestaties zijn verbeterd dankzij in-memory caching voor leesbewerkingen en streamen met een hoge gegevensdoorvoer voor schrijfbewerkingen. Een HBase-cluster kan worden gemaakt in het virtuele netwerk. Zie HDInsight-clusters maken in Azure Virtual Network voor meer informatie.
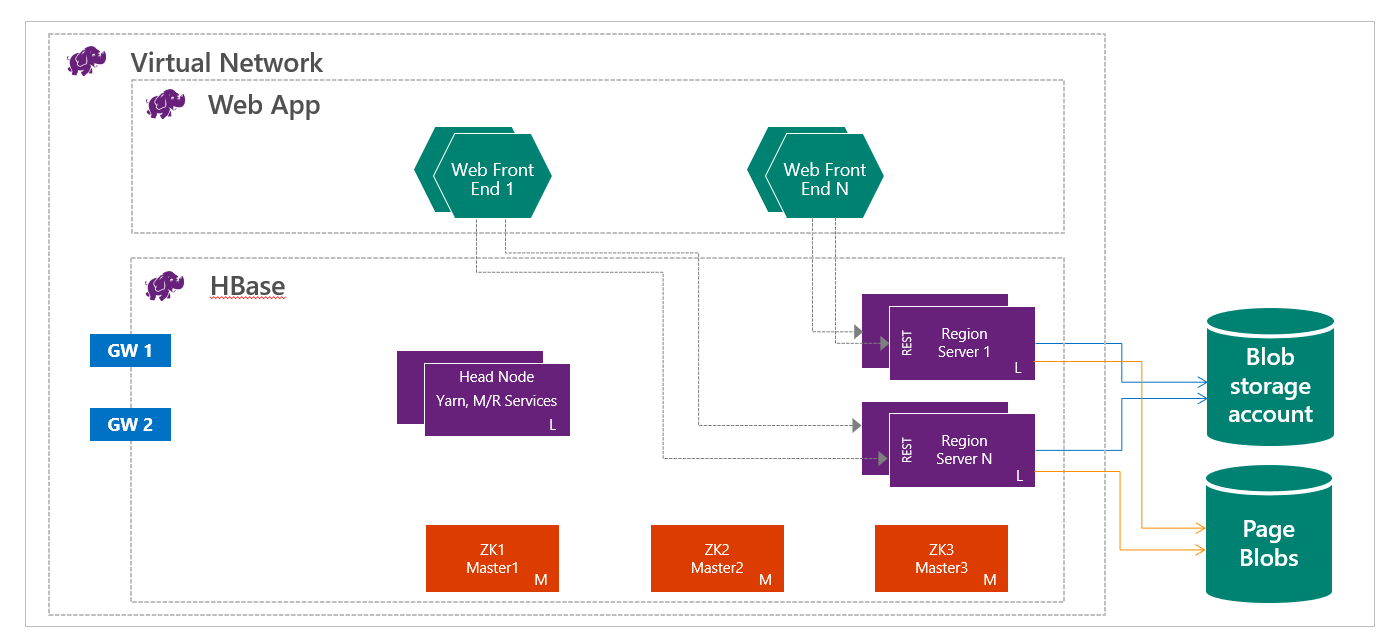
Als data engineer moet u het meest geschikte type HDInsight-cluster bepalen om uw oplossing te bouwen. U gebruikt HBase-clusters in HDInsight voor een NoSQL-database die lineair wordt geschaald, waardoor een enorme hoeveelheid doorvoer wordt bereikt, leesbewerkingen met lage latentie en onbeperkte opslag tegen een fractie van de kosten.
Hier volgen de belangrijkste scenario's voor het gebruik van HBase in HDInsight.
Sleutel-waardearchief
HBase wordt doorgaans gebruikt als een sleutel-waardearchief en is geschikt voor het beheren van berichtsystemen.
Sensorgegevens
HBase is handig voor het vastleggen van gegevens die incrementeel worden verzameld uit verschillende bronnen, waaronder sociale analyses, tijdreeksen, het up-to-date houden van interactieve dashboards met trends en tellers en het beheren van auditlogboeksystemen.
Realtime query
Apache Phoenix is een SQL-query-engine voor Apache HBase. Deze is toegankelijk als een JDBC-stuurprogramma en maakt het uitvoeren van query's en beheren van HBase-tabellen SQL mogelijk.
HBase als een platform
Toepassingen kunnen worden uitgevoerd in HBase door HBase te gebruiken als gegevensopslag. Voorbeelden hiervan zijn Phoenix, OpenTSDB, Kiji en Titan. Toepassingen kunnen ook worden geïntegreerd met HBase. Voorbeelden hiervan zijn Apache Hive, Apache Pig, Solr, Apache Flume, Apache Impala, Apache Spark, Ganglia en Apache Drill.
In HDInsight kan HBase worden gebruikt als zelfstandige toepassing of worden geïmplementeerd in combinatie met andere big data-analysetoepassingen zoals Spark, Hadoop, Hive of Kafka.
In het HBase-gegevensmodel worden semi-gestructureerde gegevens opgeslagen met verschillende gegevenstypen, variërende kolomgrootte en veldgrootte. De indeling van het HBase-gegevensmodel vereenvoudigt het partitioneren en distribueren van gegevens in het cluster. Het HBase-gegevensmodel bestaat uit verschillende logische onderdelen: rijsleutels, kolomfamilie, tabelnaam, tijdstempel, enzovoort.
Een rijsleutel wordt gebruikt om de rijen in HBase-tabellen uniek te identificeren. In HDInsight kunt u de gegevens rechtstreeks naar HBase schrijven met behulp van de meerdere beschikbare API's, zoals HBase REST, HBase RPC, Phoenix Query Server, HBase bulksgewijs laden of de integratie gebruiken met verschillende frameworks voor big data, zoals Apache Spark, Hive, enzovoort.
U kunt gebruikmaken van de functie voor versnelde schrijfbewerkingen van HBase om hoge schrijfdoorvoer mogelijk te maken. Raadpleeg het HBase-boek voor meer informatie over HBase Architecture en best practices.