Aan de slag met Azure AI Vision
De mogelijkheid voor computersystemen voor het verwerken van geschreven en afgedrukte tekst is een gebied van AI waarbij computer vision met natuurlijke taalverwerking wordt gekruist. Visuele mogelijkheden zijn nodig om de tekst te 'lezen' en vervolgens zijn de mogelijkheden voor verwerking van natuurlijke taal zinvol.
OCR is de basis van het verwerken van tekst in afbeeldingen en maakt gebruik van machine learning-modellen die zijn getraind om afzonderlijke vormen te herkennen als letters, cijfers, leestekens of andere elementen van tekst. Een groot deel van de implementatie van dergelijke mogelijkheden werd in de beginfase uitgevoerd door postservices, ter ondersteuning van automatische postsortering op basis van postcodes. Sindsdien is de state-of-the-art voor het lezen van tekst verder gegaan, en we hebben modellen die afgedrukte of handgeschreven tekst in een afbeelding detecteren en deze line-by-line en word-by-word lezen.
OCR-engine van Azure AI Vision
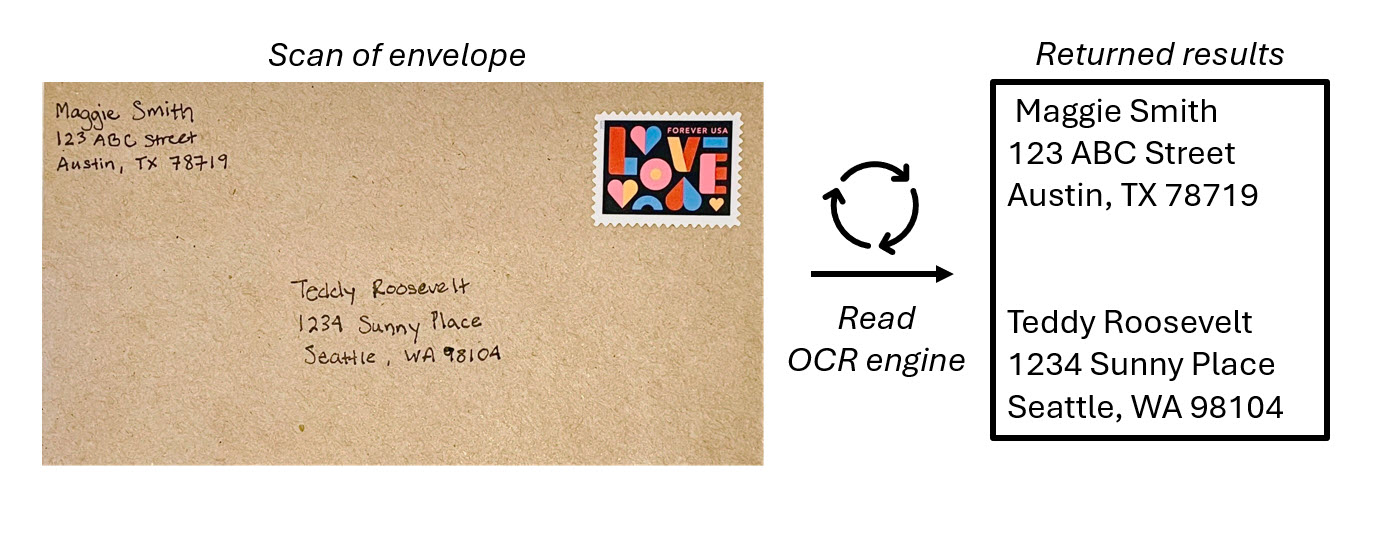
De Azure AI Vision-service biedt de mogelijkheid om machineleesbare tekst uit afbeeldingen te extraheren. De Lees-API van Azure AI Vision is de OCR-engine die tekstextractie van afbeeldingen, PDF-bestanden en TIFF-bestanden mogelijk maakt. OCR voor afbeeldingen is geoptimaliseerd voor algemene, niet-documentafbeeldingen waarmee OCR eenvoudiger kan worden ingesloten in uw gebruikerservaringsscenario's.
De Read-API, ook wel bekend als read OCR-engine, maakt gebruik van de nieuwste herkenningsmodellen en is geoptimaliseerd voor afbeeldingen met een aanzienlijke hoeveelheid tekst of aanzienlijke visuele ruis. Het kan automatisch het juiste herkenningsmodel bepalen dat moet worden gebruikt, rekening houdend met het aantal regels tekst, afbeeldingen met tekst en handschrift.
De OCR-engine neemt een afbeeldingsbestand op en identificeert begrenzingsvakken of coördinaten, waar items zich in een afbeelding bevinden. In OCR identificeert het model begrenzingsvakken rond alles wat tekst in de afbeelding lijkt te zijn.
Als u de Read-API aanroept, worden resultaten geretourneerd die zijn gerangschikt in de volgende hiërarchie:
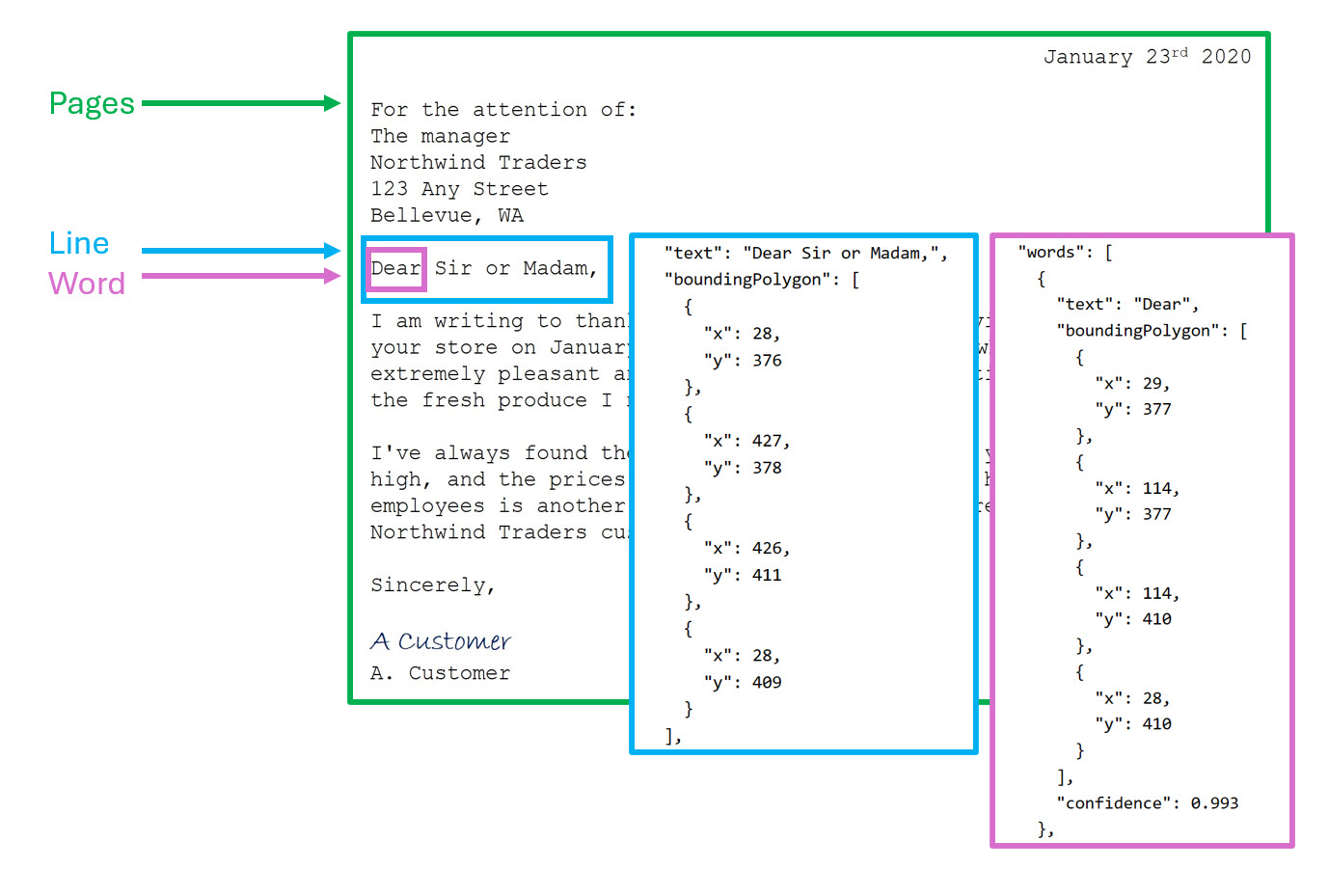
- Pagina's: één voor elke pagina met tekst, inclusief informatie over de paginagrootte en afdrukstand.
- Regels: de tekstregels op een pagina.
- Woorden : de woorden in een tekstregel, inclusief de coördinaten van het begrenzingsvak en de tekst zelf.
Elke regel en elk woord bevat coördinaten van een begrenzingsvak die de positie op de pagina aangeven.