Overzicht van Azure Site Recovery
Azure Site Recovery is meer dan een hulpprogramma om uw systeem na een stroomstoring te herstellen. Azure Site Recovery repliceert workloads tussen een primaire site en een secundaire locatie. Site Recovery kan ook worden gebruikt voor het migreren van VM's van een on-premises infrastructuur naar Azure.
De eerste taak voor het beschermen van uw workloads tegen een aardbeving bestaat bijvoorbeeld uit het controleren van het huidige BCDR-plan (bedrijfscontinuïteit en herstel na noodgevallen) van het bedrijf. Identificeer de verschillende hersteldoelstellingen en het bereik voor de systemen die moeten worden beschermd.
In deze les onderzoekt u hoe Azure Site Recovery deze doelen kan bereiken en failover en herstel van resources mogelijk maakt als er zich een noodgeval voordoet.
Bedrijfscontinuïteit en herstel na noodgevallen
Uitval van services kan leiden tot onderbrekingen voor uw personeel en gebruikers. Elke seconde dat systemen niet beschikbaar zijn, kunnen leiden tot verlies van omzet voor uw bedrijf. Uw bedrijf kan ook financiële sancties ondervinden voor het verbreken van overeenkomsten voor de beschikbaarheid van services die u levert.
BCDR-plannen zijn formele documenten die bedrijven opstellen om het bereik en de acties te behandelen die moeten worden ondernomen wanneer er een noodgeval of grootschalige storing optreedt. Elke uitval wordt afzonderlijk geëvalueerd. Een BCDR-plan wordt bijvoorbeeld in actie gebracht wanneer een heel datacenter stroom verliest.
In dit voorbeeldscenario is er een aardbeving opgetreden en beschadigde communicatielijnen, waardoor het datacentrum nutteloos is en reparatie nodig heeft. Een noodgeval van deze grootte kan dagen lang services uitzetten, geen uren, dus er moet een volledig BCDR-plan worden aangeroepen om de services weer online te krijgen.
Als onderdeel van het BCDR-plan moet u de beoogde hersteltijd (RTO's) en het beoogde herstelpunt (RPO's) voor uw toepassingen identificeren. Samen helpen deze twee doelstellingen om de maximale uren te identificeren die uw bedrijf zonder opgegeven services kan hebben en wat het proces voor gegevensherstel moet zijn. Laten we elk doel nader bekijken.
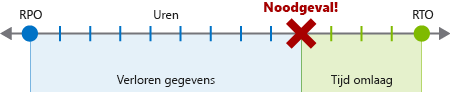
Recovery Time Objective (RTO, beoogde hersteltijd)
Een RTO is een meting van de maximale tijdsduur die uw bedrijf kan overleven na een noodgeval totdat de normale service moet worden hersteld om onaanvaardbare gevolgen te voorkomen die verband houden met een onderbreking in de continuïteit. Stel dat u een RTO van 12 uur hebt. Dit wil zeggen dat uw bedrijfsactiviteiten nog 12 uur kunnen doorgaan terwijl de kernservices van het bedrijf niet werken. Als de downtime langer is, zou uw bedrijf ernstig worden geschaad.
Recovery Point Objective (RPO, beoogd herstelpunt)
Een RPO is een meting van de maximale hoeveelheid gegevensverlies die na een noodgeval acceptabel is. Een bedrijf kan doorgaans elke 24 uur, 12 uur of zelfs in realtime een back-up maken. Als er zich een noodgeval voordoet, gaan er altijd wat gegevens verloren.
Als uw back-up bijvoorbeeld om de 24 uur om middernacht heeft plaatsgevonden en er om 9:00 uur een noodgeval is opgetreden, gaan negen uur aan gegevens verloren. Als de RPO van uw bedrijf 12 uur is, zou dit geen probleem zijn, omdat er slechts negen uur zijn verstreken. Als de RPO echter vier uur is, zou dit wel een probleem zijn en loopt het bedrijf schade op.
Wat is Azure Site Recovery?
Azure Site Recovery kan bijdragen aan uw BCDR-plan, omdat deze workloads van een primaire site naar een secundaire site kan repliceren. Als er een probleem optreedt op de primaire site, kan Site Recovery automatisch worden aangeroepen om de beveiligde virtuele machines te repliceren naar een andere locatie. De failover-overschakeling kan van on-premises naar Azure zijn of van de ene Azure-regio naar een andere.
Hier ziet u enkele van de belangrijkste functies van Azure Site Recovery:
- Centraal beheer: replicatie kan worden ingesteld en beheerd, en failover en failback kunnen allemaal vanuit Azure Portal worden aangeroepen.
- Replicatie van on-premises virtuele machines: on-premises virtuele machines kunnen indien nodig worden gerepliceerd naar Azure of naar een secundair on-premises datacenter.
- Replicatie van virtuele Azure-machines: virtuele Azure-machines kunnen worden gerepliceerd van de ene regio naar de andere.
- App-consistentie tijdens failover: door herstelpunten en toepassingsconsistente momentopnamen te gebruiken, worden virtuele machines altijd in een consistente status bewaard tijdens de replicatie.
- Flexibele failover: failovers kunnen op aanvraag worden uitgevoerd als een test of geactiveerd tijdens een werkelijk noodgeval. Testen kunnen worden uitgevoerd om een DR-scenario te simuleren, zonder uw actieve services te onderbreken.
- Netwerkintegratie: Site Recovery kan netwerkbeheer beheren tijdens een replicatie- en noodherstelscenario. Gereserveerde IP adressen en load balancers zijn erin opgenomen, zodat de virtuele machines op de nieuwe locatie kunnen functioneren.
Azure Site Recovery instellen

Er moeten diverse onderdelen worden ingesteld om Azure Site Recovery in te schakelen:
- Netwerken: er is een geldig virtueel Azure-netwerk vereist om de gerepliceerde virtuele machines te kunnen gebruiken.
- Recovery Services-kluis: in een kluis in uw Azure-abonnement worden de gemigreerde VM's opgeslagen wanneer een failover wordt uitgevoerd. De kluis bevat tevens het replicatiebeleid en de bron- en doellocaties voor replicatie en failover.
- Referenties: de referenties die u voor Azure gebruikt, moeten de rollen Inzender voor virtuele machines en Site Recovery-inzenders hebben om machtigingen toe te staan voor het wijzigen van zowel de virtuele machine als de opslag waarmee Site Recovery is verbonden.
- Configuratieserver: Een on-premises VMware-server voldoet aan verschillende functies tijdens het failover- en replicatieproces. Deze wordt als een OVA (Open Virtual Machine Appliance) verkregen via Azure Portal voor eenvoudige implementatie. De configuratieserver bevat een:
- Processerver: deze server fungeert als een gateway voor het replicatieverkeer. Hiermee wordt het verkeer in de cache opgeslagen, gecomprimeerd en versleuteld voordat het via het WAN naar Azure wordt verzonden. Via de processerver wordt tevens Mobility Service geïnstalleerd op alle fysieke en virtuele machines die voor failover en replicatie zijn bedoeld.
- Hoofddoelserver: Deze computer verwerkt het replicatieproces tijdens een failback vanuit Azure.
Belangrijk
Als u een failback wilt kunnen uitvoeren van Azure naar een on-premises omgeving, moet een VMware vCenter met een configuratieserver beschikbaar zijn, zelfs als u alleen fysieke machines naar Azure repliceert. U kunt geen failback uitvoeren naar fysieke servers.
Replicatieproces
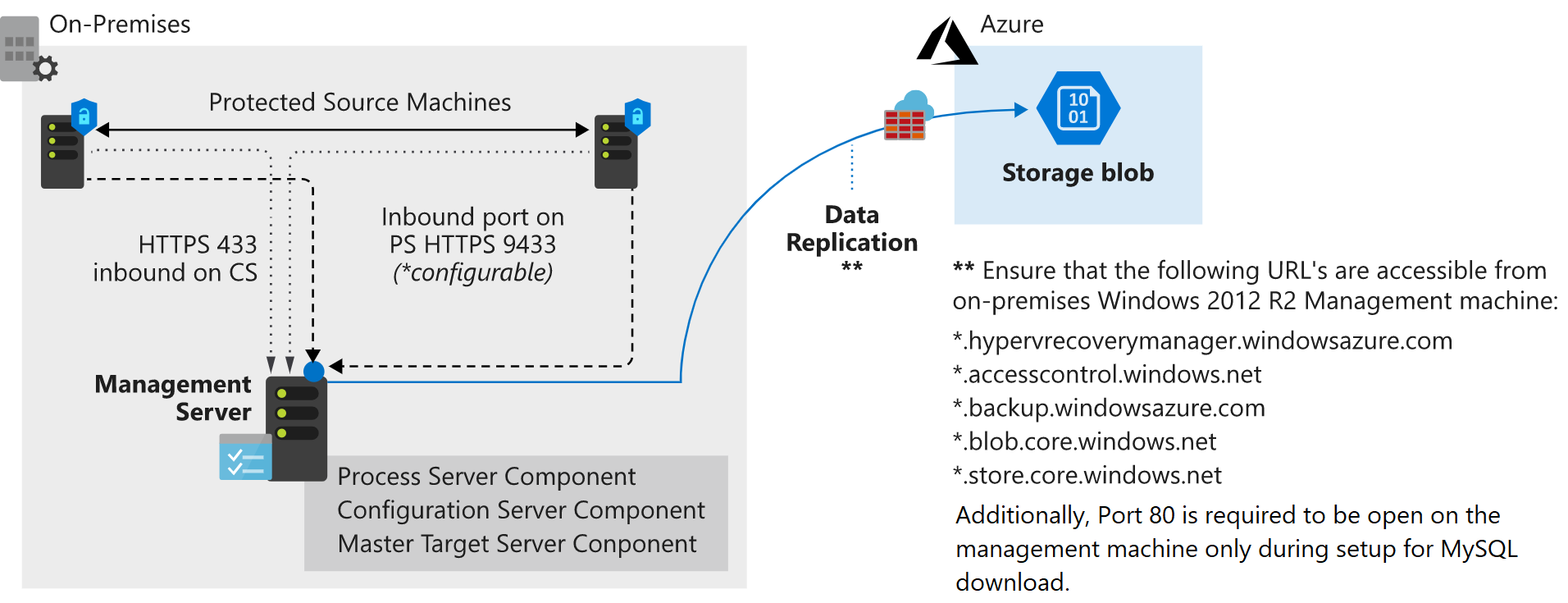
Wanneer de vereiste taken zijn ingesteld, kan de replicatie van de computers beginnen. Ze worden gerepliceerd volgens het replicatiebeleid. Tijdens de eerste fasen van de eerste kopie worden de servergegevens gerepliceerd naar Azure Storage. Wanneer de initiële replicatie is voltooid, vindt er een tweede replicatie plaats. Deze keer worden de deltawijzigingen voor de virtuele machine gerepliceerd naar Azure.
Een failover testen en controleren
Nadat uw omgeving is ingesteld voor herstel na noodgevallen, test u deze om te controleren of deze correct is geconfigureerd en of alles naar verwachting werkt. Test de configuratie door een DR-herstelanalyse uit te voeren op een geïsoleerde VM. Het is een best practice om voor de test een geïsoleerd netwerk te gebruiken, zodat de actieve services niet worden onderbroken.
De eerste taak voor het uitvoeren van een herstelanalyse bestaat uit het verifiëren van de eigenschappen van uw VM voor de test. U doet dit in de sectie Beveiligde items van Azure Portal. In het deelvenster Gerepliceerd item ziet u de meest recente herstelpunten. In de sectie Compute & Network kunnen de naam van de virtuele machine, de resourcegroep, de doelgrootte, de beschikbaarheidsset en de schijfinstellingen indien nodig worden aangepast.
DR-herstelanalyses kunnen worden gestart in de sectie Instellingen>Gerepliceerde items in Azure Portal. Selecteer de doel-VM en selecteer daarna het menu-item Failover testen voor het meest recent verwerkte herstelpunt. Selecteer het Azure-netwerk in hetzelfde menu. U start de hersteltaak door OK te selecteren in het scherm voor netwerkselectie.
U krijgt toegang tot de status van de hersteltaak en de gerepliceerde virtuele machine via de sectie Overzicht van de Recovery Services-kluis. Gerepliceerde items kunnen de volgende status hebben:
- In orde: replicatie werkt normaal.
- Waarschuwing: er is een probleem dat van invloed kan zijn op replicatie.
- Kritiek: er is een kritieke replicatiefout gedetecteerd.
Als alles goed gaat, wordt de gerepliceerde VM-status ingesteld op Uitgevoerd. Als een test niet is uitgevoerd, wordt de status ingesteld op Test aanbevolen. De VM wordt ook ingesteld op Test aanbevolen als de laatste test langer dan zes maanden geleden is uitgevoerd.