Gegevens transformeren met operators
Hoewel veel operators in Data Wrangler intuïtief en eenvoudig te gebruiken zijn, vereisen anderen een dieper begrip om ze volledig te kunnen gebruiken.
One-hot coderingsoperator gebruiken
Sommige machine learning-modellen, zoals lineaire regressie, vereisen dat alle invoer- en uitvoervariabelen numeriek zijn en geen categorische variabelen ondersteunen. Categorische gegevens verwijzen naar variabelen die zijn onderverdeeld in meerdere categorieën die geen numerieke waarde of volgorde bevatten.
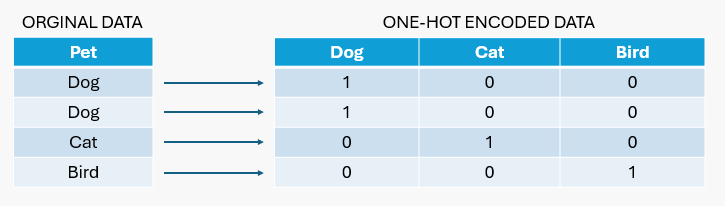
In één dynamische codering wordt elke categorie in een functie weergegeven als een binaire vector van 1 en 0' s.
Als u bijvoorbeeld een huisdiervariabele hebt met de waarden hond, kat en vogel, worden er drie nieuwe variabelen gemaakt (één voor elk type huisdier). Voor elk gegevenspunt markeert het 1 voor het huisdier dat het vertegenwoordigt en 0 voor de andere. Dus als een gegevenspunt een hond vertegenwoordigt, wordt het gecodeerd als [1, 0, 0]. Als het een kat is, is het [0, 1, 0], en als het een vogel is, is het [0, 0, 1].
Notitie
Een dynamische codering kan leiden tot een grotere dimensionaliteit. Dit is wanneer het aantal functies in de gegevensset zeer groot wordt. Dit is met name het geval wanneer de categorische variabele veel unieke waarden heeft.
We gaan een dataframe maken op basis van het bovenstaande voorbeeld van het huisdier en Data Wrangler gebruiken om de code te genereren voor one-hot codering.
import pandas as pd
# Sample dataset with 50 data points, including duplicates
data = {'pet': ['dog', 'dog', 'cat', 'cat', 'bird', 'bird']*8 + ['bird', 'cat']}
df = pd.DataFrame(data)
print(df.head(10))
In de volgende stappen ziet u hoe u de operator voor één hot-codering voor de pet variabele gebruikt.
Start Data Wrangler vanuit een Microsoft Fabric-notebook voor het
dfdataframe.Selecteer de
petvariabele.Selecteer formules in het deelvenster Bewerkingen en vervolgens One-hot-codering.
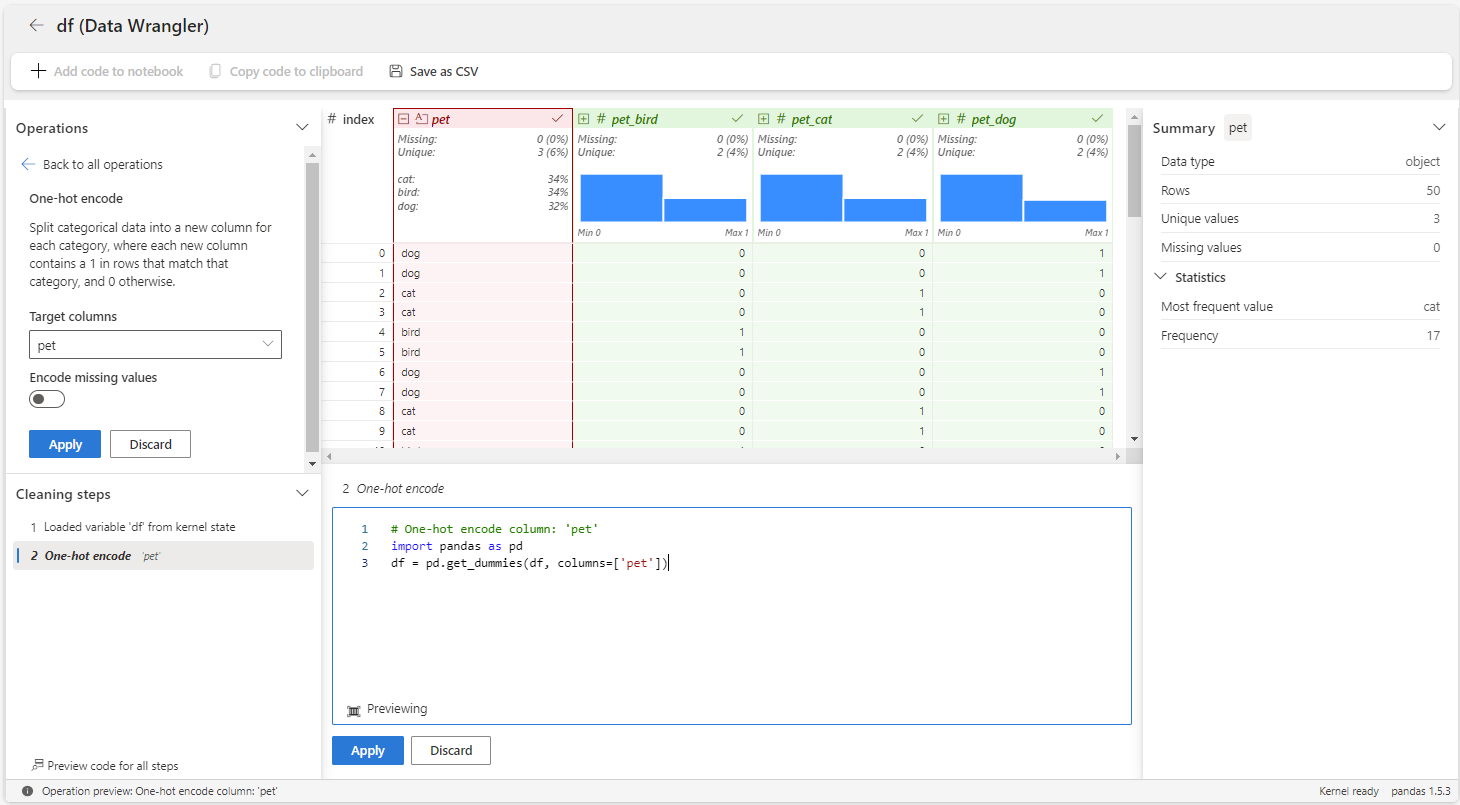
Selecteer Toepassen.
Selecteer + Code toevoegen aan notebook in de werkbalk boven het Data Wrangler-raster. Hiermee wordt een functie gegenereerd die u vervolgens kunt uitvoeren in uw gegevenspijplijn.
De binarizer-operator met meerdere labels gebruiken
Eén hot-codering wordt gebruikt wanneer elk gegevenspunt tot precies één categorie behoort. Aan de andere kant wordt de binarizer-operator met meerdere labels gebruikt wanneer elk gegevenspunt tot meerdere categorieën kan behoren.
Met de binarizer-operator met meerdere labels kunt u categorische gegevens splitsen in een nieuwe kolom voor elke categorie met behulp van een scheidingsteken voor tekstsplitsing, waarbij elke nieuwe kolom een kolom bevat die overeenkomt met die categorie en 0 anders.
Voor trainingsdoeleinden maken we een dataframe over voedselcategorie en gebruiken we Data Wrangler om de code voor binarizer met meerdere labels te genereren.
import pandas as pd
#Sample data
data = {
'food': ['Pasta', 'Burger', 'Ice Cream', 'Salad'],
'category': ['Italian|Fine dining', 'American|Fast Food', 'Dessert', 'Healthy']
}
# Create DataFrame
restaurant = pd.DataFrame(data)
Vervolgens laten de volgende stappen zien hoe u de binarizer-operator met meerdere labels voor de category variabele gebruikt.
Start Data Wrangler vanuit een Microsoft Fabric-notebook voor het
restaurantdataframe.Selecteer de
categoryvariabele.Selecteer formules in het deelvenster Bewerkingen en vervolgens binarizer met meerdere labels.
Typ | als de delimeter.
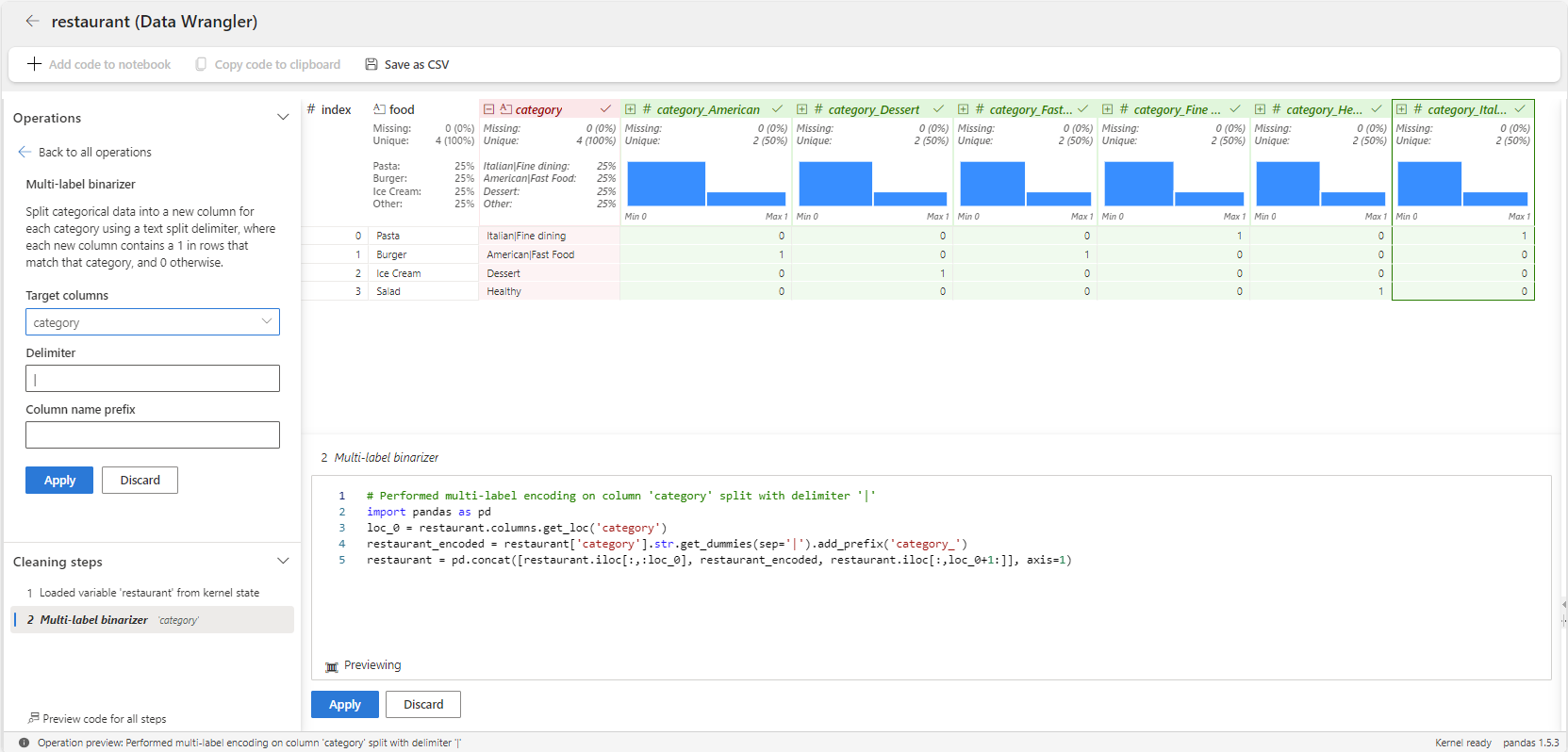
Het resultaat is een dataframe met variabelen voor elke categorie, zoals Amerikaans, Dessert, Fast Food, Gezond en Italiaans. Elk voedselitem wordt gemarkeerd met 1's of 0's in deze kolommen om weer te geven tot welke categorieën het behoort. Zo vallen zowel Pizza als Burger onder meerdere categorieën.
Selecteer Toepassen.
Selecteer + Code toevoegen aan notebook in de werkbalk boven het Data Wrangler-raster. Hiermee wordt een functie gegenereerd die u vervolgens kunt uitvoeren in uw voorverwerkingspijplijn.
Minimale schaalaanpassingsoperator gebruiken
Minimale schaalaanpassing of minimale normalisatie is het proces van het transformeren van een numerieke functie. Met dit proces wordt het bereik van uw gegevens geschaald, terwijl de vorm van de oorspronkelijke verdeling en de relaties tussen variabelen behouden blijven.
Het zorgt ervoor dat de betekenis van een functie wordt bepaald door de relatieve waarde, niet de absolute waarde. Met andere woorden, functies worden niet belangrijker beschouwd omdat ze grotere schalen hebben.
Hierbij wordt elke waarde in uw gegevens afgetrokken, wordt de minimumwaarde van die gegevens afgetrokken en vervolgens gedeeld door het bereik van de gegevens (de maximumwaarde minus de minimumwaarde).
Het resultaat is dat uw gegevens worden aangepast aan een bereik van 0 tot 1, wat handig kan zijn voor bepaalde typen machine learning-algoritmen, met name die gebruikmaken van afstandsmetingen zoals K-dichtstbijzijnde buren.
Laten we eens kijken naar een dataframe dat de cijfers van leerlingen/studenten in een klas vertegenwoordigt. Het gegevensframe heeft drie kolommen: Student, Math_Grade, English_Gradeen Hours_Studied.
import pandas as pd
# Sample data
data = {
'Student': ['Bob', 'Mark', 'Anna', 'David', 'Sam'],
'Math_Grade': [85, 90, 78, 92, 88],
'English_Grade': [80, 85, 92, 88, 90],
'Hours_Studied': [250, 500, 355, 245, 199]
}
df = pd.DataFrame(data)
print(df)
De uitvoer is:
Student Math_Grade English_Grade Hours_Studied
0 Bob 85 80 250
1 Mark 90 85 500
2 Anna 78 92 355
3 David 92 88 245
4 Sam 88 90 199
Nu gaan we min-max scaler toepassen op de Math_Grade, English_Gradeen Hours_Studied variabelen met behulp van Data Wrangler. Hiervoor moet u de operator min/max-waarden schalen gebruiken onder de categorie Numeriek .
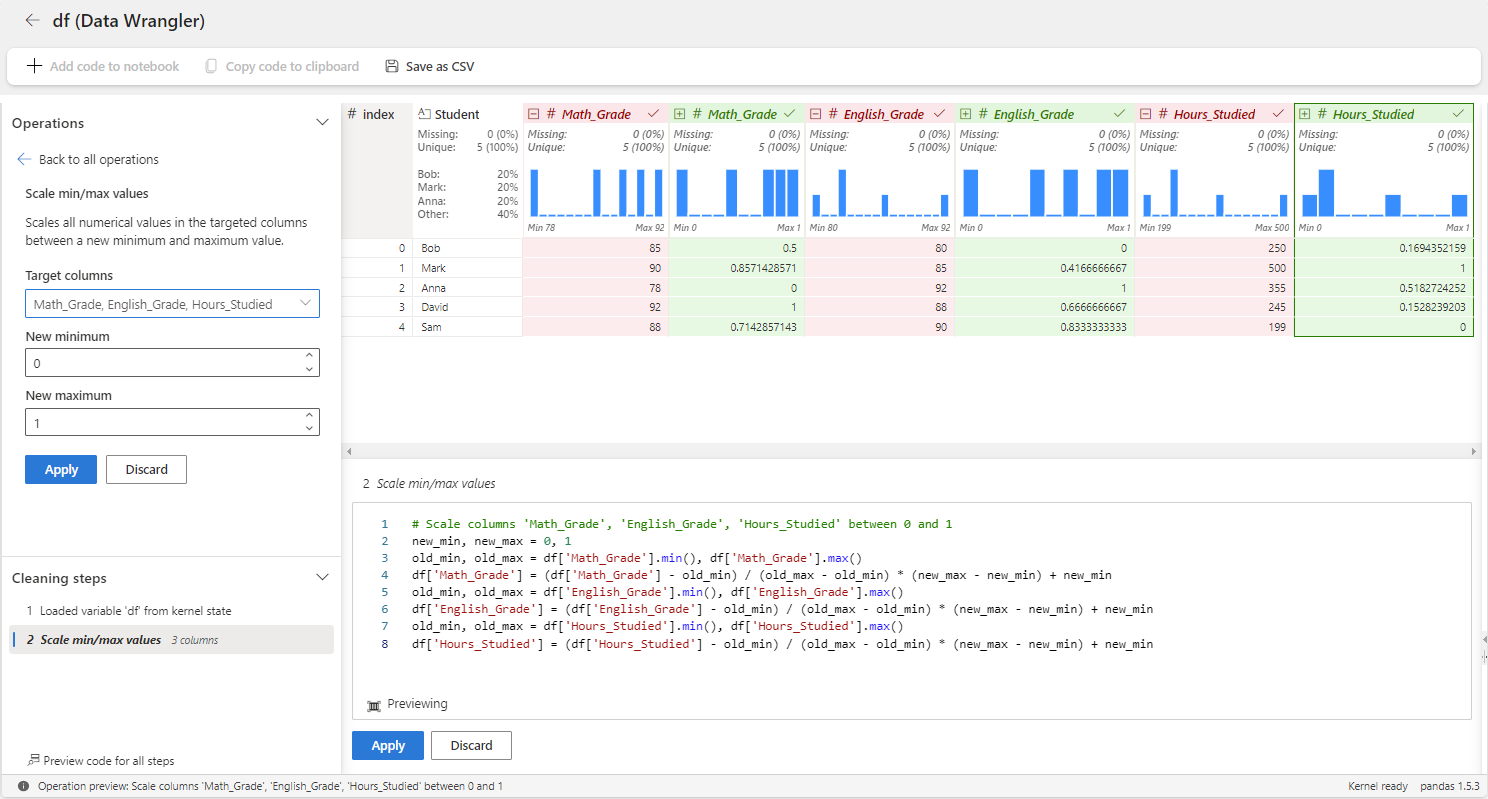
In het bovenstaande worden de cijfers geschaald om te vallen binnen het bereik van [0, 1], waarbij het minimumcijfer is toegewezen aan 0 en het maximumaantal dat is toegewezen aan 1. Andere cijfers worden proportioneel geschaald binnen dit bereik. U kunt ook het minimum- en maximumbereik aanpassen.
Als u functies zoals Math_Grade, English_Gradeen Hours_Studied in een machine learning-algoritme op afstand, zoals K-Nearest Neighbors , gebruikt zonder ze eerst te schalen, kunnen er problemen optreden.
De Hours_Studied functie kan de andere functies mogelijk overheersten vanwege het grotere bereik van waarden. Dit kan leiden tot een model dat sterk afhankelijk is Hours_Studiedvan , terwijl het wordt genegeerd Math_Grade en English_Grade. Het is dus belangrijk om uw gegevens in die gevallen te schalen om ervoor te zorgen dat alle functies gelijke urgentie krijgen.
Zie Gegevenstransformaties voor meer informatie over gegevensnormalisatie voor machine learning-modellen.