Gegevensverkenning uitvoeren
Data Wrangler vereenvoudigt het verkennen van uw gegevens met een gebruiksvriendelijke rasterinterface die dynamisch overzichtsstatistieken van uw gegevens presenteert.
Door de visuele verkenning van samenvattingsstatistieken kunnen gegevenswetenschappers de juiste statistische of machine learning-modellen selecteren die het beste bij de gegevens passen. Bij sommige modellen wordt er bijvoorbeeld van uitgegaan dat de gegevens normaal gesproken worden gedistribueerd en mogelijk niet goed presteren als deze aanname wordt geschonden.
Tip
Zie Gegevens voor gegevenswetenschap verkennen met notebooks in Microsoft Fabric voor meer informatie over de basisprincipes van gegevensverkenning met behulp van notebooks.
Samenvattende statistieken bekijken
Voor demonstratiedoeleinden gaan we enkele willekeurige gegevens genereren om een hypothetisch scenario met huizenprijzen in een bepaalde buurt te simuleren.
import pandas as pd
import numpy as np
# Set the seed
np.random.seed(0)
# Define the size of the dataset
size = 500
# Generate random data
data = {
'Size': np.random.randint(1000, 4001, size, dtype=int) // 10 * 10, # any integer value between 1000 and 4000, with multiple of 10
'Bedrooms': np.random.choice([2, 4, 3, 2, 1], size),
'YearBuilt': np.random.randint(1980, 2021, size), # any integer value between 1980 and 2020
'Price': np.random.normal(loc=110000, scale=20000, size=size), # normally distributed prices
'Type': np.random.choice(['Single Family', 'Townhouse', 'Condo', 'Duplex'], size) # type of the house
}
# Create a DataFrame
df = pd.DataFrame(data)
Als u overzichtsstatistieken voor het df gegevensframe wilt weergeven, selecteert u Gegevens op het notebooklint en kiest u Vervolgens Start Data Wrangler voor het df dataframe.

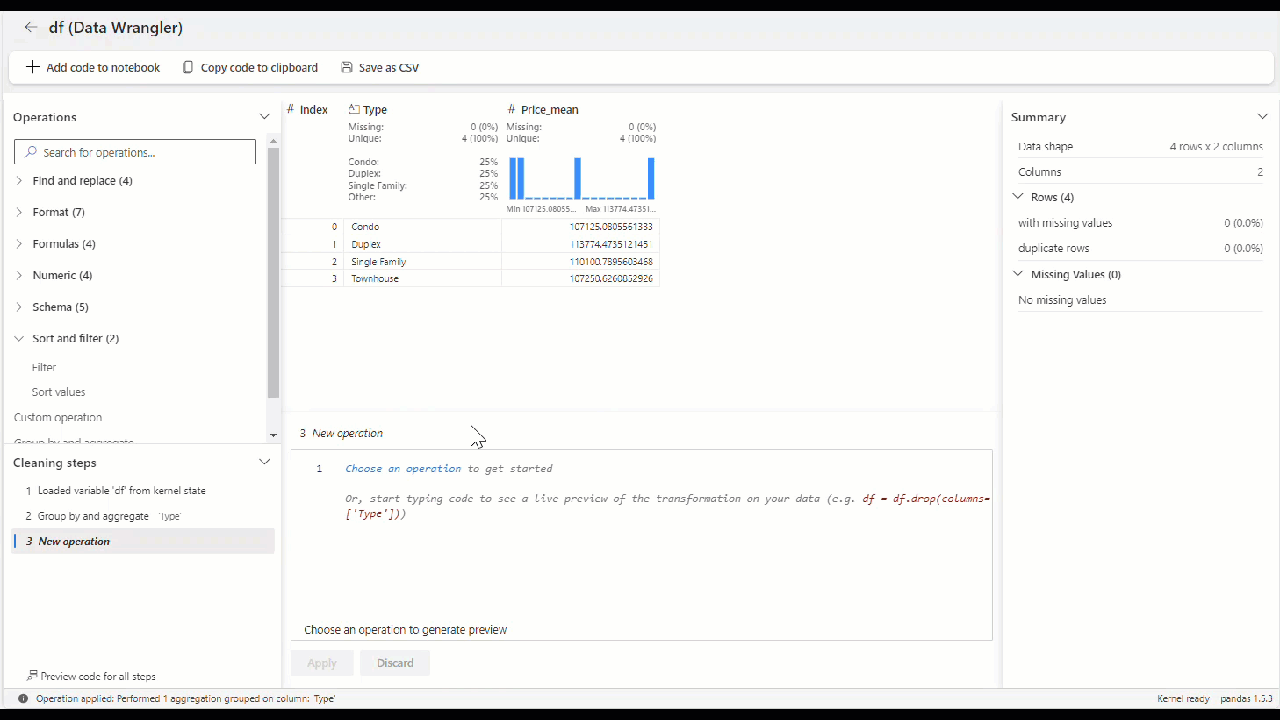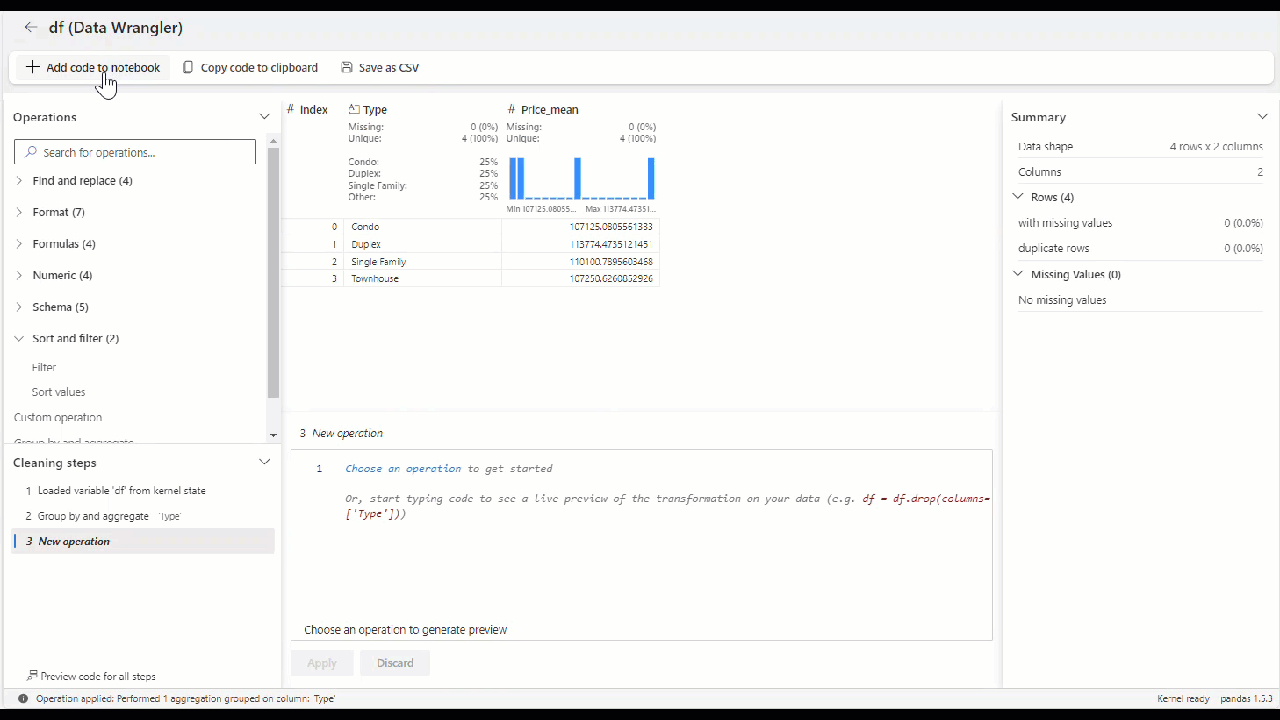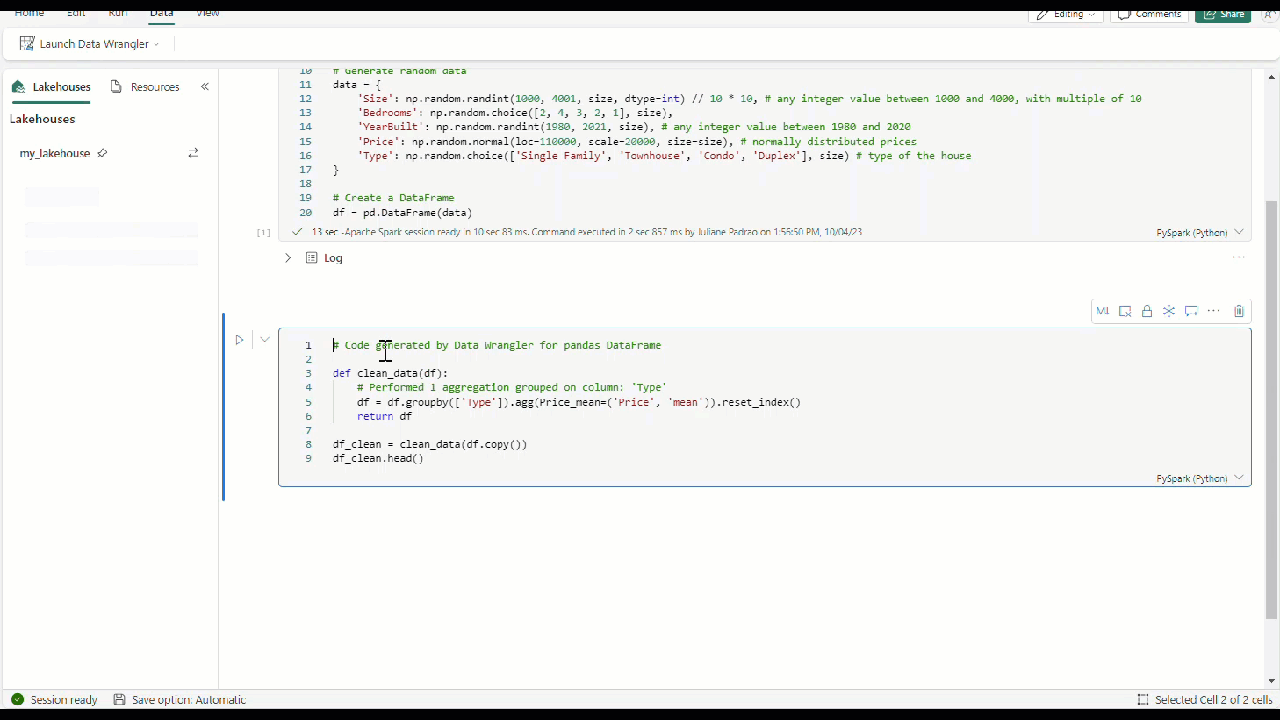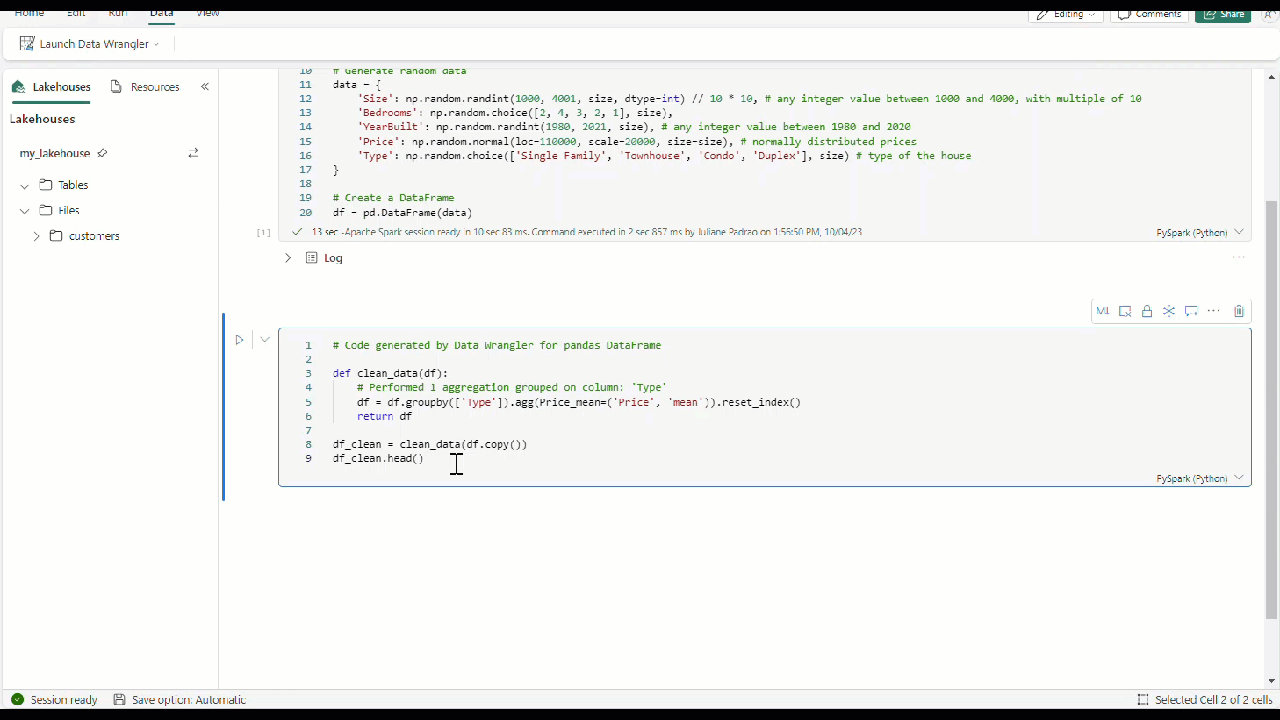
Voor numerieke variabelen geeft het raster een histogram weer, tellingen van ontbrekende en unieke waarden, evenals de minimum- en maximumwaarden. Als het gaat om categorische variabelen, biedt het raster inzicht in het aandeel van elke categorie in de variabele.
Het deelvenster Samenvatting bevat gedetailleerde beschrijvende statistieken en wordt dynamisch bijgewerkt wanneer u verschillende kolommen in het raster selecteert.
Gegevens groeperen en aggregeren
U kunt ook aggregatie in uw gegevens toepassen met behulp van de operator Groeperen op en aggregeren in het operatorvenster.
Stel dat we voor ons scenario met huizenprijzen het gemiddelde van de woningprijs per type nodig hebben.

In slechts een paar seconden kunnen we de groepsoperator configureren op en aggregeren, waarbij de code automatisch voor u wordt gegenereerd. In het raster worden ook de nieuwe gegevens groen weergegeven en worden de kolommen rood verwijderd.
Zodra de operator is toegepast, ziet u het uiteindelijke raster.

Op dit moment kunt u besluiten om de code te genereren of het getransformeerde dataframe te downloaden als een CSV-bestand (door komma's gescheiden waarden).
Code genereren
Wanneer u in Data Wrangler ingebouwde of aangepaste operators gebruikt, wordt het dataframe pas gewijzigd als u de gegenereerde code in uw notebook toevoegt en uitvoert.
Nadat u alle operators hebt toegepast om de gegevens te transformeren, selecteert u + Code toevoegen aan notebook in de werkbalk boven het Data Wrangler-raster. Hiermee wordt een functie gegenereerd die u vervolgens kunt uitvoeren in uw gegevenspijplijn.
Deze functie vereenvoudigt de gegevensverkennings- en voorverwerkingstaken in uw data science-werkstroom.