Inzicht in Data Wrangler
Data Wrangler is een hulpprogramma dat is gebouwd op Microsoft Fabric-notebooks die een uitgebreid platform biedt voor verkennende en voorverwerkingstaken. Het biedt een weergave van gegevens, dynamische samenvattingsstatistieken, ingebouwde visualisaties en een bibliotheek met algemene bewerkingen voor het verwerken van gegevens.
Elke bewerking werkt de gegevensweergave in realtime bij en genereert herbruikbare code die kan worden opgeslagen in het notebook. De gebruiksvriendelijke interface maakt het een efficiënt hulpmiddel voor gegevenswetenschappers om grote hoeveelheden gegevens te verwerken en onbewerkte gegevens te transformeren in een kant-en-klare gegevensset voor analyse.
U kunt Data Wrangler beschouwen als een hulpprogramma waarmee code wordt gegenereerd voor uw gegevensverkennings- en voorverwerkingsbehoeften.
Notitie
Data Wrangler ondersteunt momenteel alleen Pandas-dataframe .
Werken met Data Wrangler
Data Wrangler kan helpen bij de voorverwerkingsfase van het bouwen van een machine learning-model door hulpprogramma's en functionaliteiten te bieden voor het opschonen van gegevens, functie-engineering, gegevensverkenning en het verbeteren van de efficiëntie van gegevensvoorverwerking.
Gegevensverkenning: met de rasterachtige gegevensweergave van het hulpprogramma kunt u uw gegevens visueel verkennen, wat kan leiden tot inzichten over variabelen.
Gegevens opschonen: Data Wrangler biedt een bibliotheek met algemene bewerkingen voor het opschonen van gegevens, waardoor het eenvoudiger is om ontbrekende waarden, uitbijters en onjuiste gegevenstypen te verwerken.
Functie-engineering: Met de ingebouwde visualisaties en dynamische overzichtsstatistieken kan Data Wrangler u helpen de distributie van uw gegevens te begrijpen en nieuwe functies te maken.
Data Wrangler kan ervoor zorgen dat uw gegevens de best mogelijke vorm hebben voordat ze worden gebruikt om een machine learning-model te trainen. Dit kan leiden tot nauwkeurigere modellen en betere voorspellingen.
Data Wrangler starten vanuit een notebook
Volg deze stappen om Data Wrangler in Microsoft Fabric te starten.
Schakel over van Power BI naar Datawetenschap met behulp van het pictogram ervaringswisselaar aan de linkerkant van de startpagina. Maak vervolgens een nieuw notitieblok.
Lees uw gegevens in een Pandas DataFrame in een Microsoft Fabric-notebook.
import pandas as pd df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv") Add another dataset example.Zodra uw gegevens in een dataframe zijn geladen, selecteert u Gegevens op het notebooklint.
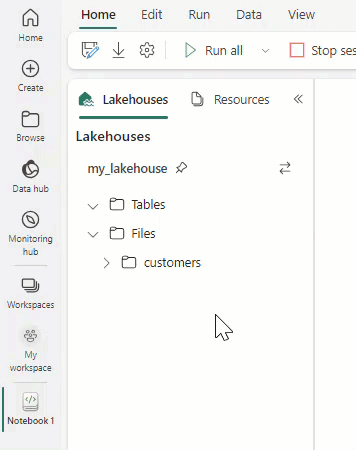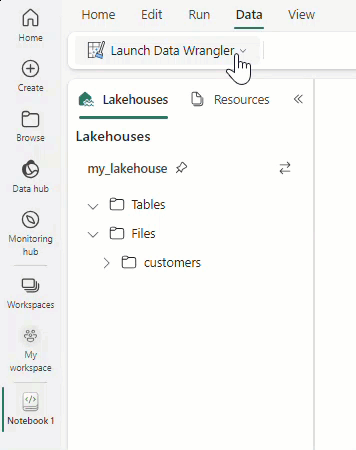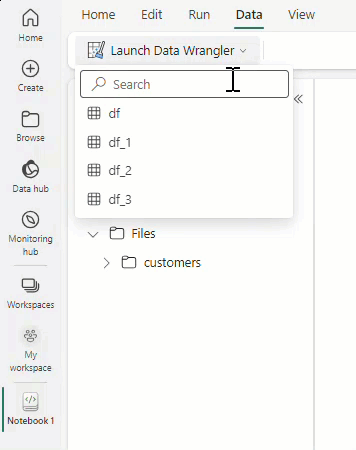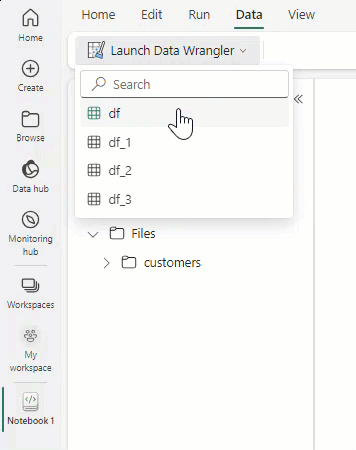
Selecteer Data Wrangler starten en selecteer vervolgens het dataframe dat u wilt openen in Data Wrangler. Als u meerdere dataframes hebt, worden ze allemaal weergegeven.
Tip
Met de Data Wrangler-extensie voor Visual Studio Code kunt u Data Wrangler integreren in zowel VS Code als VS Code Jupyter Notebooks.
Werken met operators
Stel dat u werkt aan een grote gegevensset voor een kritiek project. De gegevens hebben veel werk nodig. U hebt ontbrekende waarden, dubbele rijen en kolommen die de naam moeten wijzigen. Bovendien moet u categorische gegevens transformeren in een indeling die uw machine learning-model kan begrijpen.
Dit is waar Data Wrangler binnenkomt. Met minimale inspanning kunt u rijen sorteren en filteren, categorische gegevens met één hot coderen, kolomtypen wijzigen, onnodige kolommen verwijderen, kolommen hernoemen, ontbrekende waarden verwerken en nog veel meer. Data Wrangler maakt deze taken niet alleen eenvoudiger, maar genereert ook herbruikbare Python-code voor elke bewerking, die u kunt opslaan in uw notebook. Dit betekent dat u gegevensverwerkingstaken voor toekomstige gegevenssets kunt automatiseren.
Dit zijn de operatorcategorieën die momenteel beschikbaar zijn in Data Wrangler.
| Categorie | Beschrijving |
|---|---|
| Zoeken en vervangen | Bevat bewerkingen zoals dubbele rijen verwijderen, ontbrekende waarden verwerken en waarden zoeken en vervangen. |
| Notatie | Omvat teksttransformaties zoals converteren naar hoofdletters/kleine letters, het splitsen van tekst, het strippen van witruimte en automatische transformaties die mogelijk worden gemaakt door Microsoft Flash Fill. |
| Formules | Hiermee kunt u nieuwe kolommen maken met behulp van aangepaste Python-formules, binarizer met meerdere labels, een hot codering en het berekenen van de lengte van tekst. |
| Numeriek | Omvat bewerkingen zoals afronden (omhoog, omlaag of naar het dichtstbijzijnde getal) en min/max-waarden schalen. |
| Schema | Hiermee kunnen wijzigingen in het DataFrame-schema worden aangebracht, zoals het wijzigen van het kolomtype, het klonen/neerzetten/wijzigen/selecteren van kolommen. |
| Sorteren en filteren | Bevat bewerkingen voor het filteren en sorteren van waarden. |
| Overige | Bevat aangepaste bewerkingen voor het wijzigen van het dataframe, het groeperen en aggregeren van kolommen en het automatisch maken van kolommen, mogelijk gemaakt door Microsoft Flash Fill. |
In de volgende lessen verkennen we verschillende operators en krijgen we inzicht in hoe ze de voorverwerkingstaken voor het bouwen van voorspellende modellen kunnen vergemakkelijken.