Apache Spark- en Hive LLAP-query's integreren
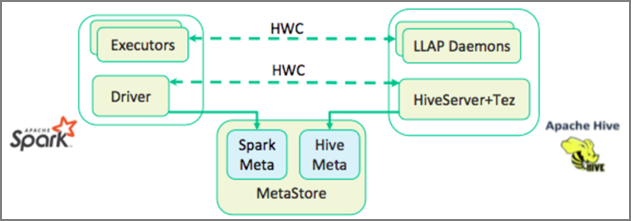
In de vorige les hebben we twee manieren bekeken om een query uit te voeren op statische gegevens die zijn opgeslagen in een Interactive Query-cluster: Data Analytics Studio en een Zeppelin-notebook. Maar wat moet u doen als u nieuwe onroerend goedgegevens wilt streamen naar uw clusters met behulp van Spark en er vervolgens query's op wilt uitvoeren met Hive? Omdat Hive en Spark twee verschillende metastores hebben, hebben ze een connector nodig om tussen de twee te overbruggingen en is de Apache Hive Warehouse Connector (HWC) die brug. Met de Hive Warehouse Connector-bibliotheek kunt u eenvoudiger met Apache Spark en Apache Hive werken door ondersteunende taken te ondersteunen, zoals het verplaatsen van gegevens tussen Spark DataFrames en Hive-tabellen, en het doorsturen van Spark-streaminggegevens naar Hive-tabellen. We gaan de connector niet instellen in ons scenario, maar het is belangrijk om te weten dat de optie bestaat.
Apache Spark heeft een Structured Streaming-API die streamingmogelijkheden biedt die niet beschikbaar zijn in Apache Hive. Vanaf HDInsight 4.0 hebben Apache Spark 2.3.1 en Apache Hive 3.1.0 afzonderlijke metastores, waardoor interoperabiliteit moeilijk is. De Hive Warehouse-connector maakt het eenvoudiger om Spark en Hive samen te gebruiken. De Hive Warehouse Connector-bibliotheek laadt gegevens van LLAP-daemons parallel in Spark-uitvoerders, waardoor deze efficiënter en schaalbaarder is dan het gebruik van een standaard JDBC-verbinding van Spark naar Hive.
Enkele van de bewerkingen die worden ondersteund door de Hive Warehouse-connector zijn:
- Een tabel beschrijven
- Een tabel maken voor geoptimaliseerde rijkolommen (ORC)-geformatteerde gegevens
- Hive-gegevens selecteren en een DataFrame ophalen
- Een DataFrame in batch naar Hive schrijven
- Een Hive-update-instructie uitvoeren
- Tabelgegevens lezen uit Hive, deze transformeren in Spark en schrijven naar een nieuwe Hive-tabel
- Een DataFrame- of Spark-stream naar Hive schrijven met HiveStreaming
Zodra u een Spark-cluster en een Interactive Query-cluster hebt geïmplementeerd, configureert u de Spark-clusterinstellingen in Ambari. Dit is een webhulpprogramma dat is opgenomen in alle HDInsight-clusters. Als u Ambari wilt openen, gaat u naar https:// servername.azurehdinsight.net in uw internetbrowser waarin servernaam de naam is van uw Interactive Query-cluster.
Vervolgens maakt u een Hive-tabel om streaminggegevens van Spark naar de tabellen te schrijven en begint u met het schrijven van gegevens. Voer vervolgens query's uit op uw streaminggegevens. U kunt een van de volgende opties gebruiken:
- Spark-shell
- PySpark
- spark-submit
- Zeppelin
- Livy