Interactieve HDInsight-query's
Interactieve query's worden doorgaans geïmplementeerd in een koud padscenario, waarin u gegevens in tabelvorm hebt en snel vragen wilt stellen en een interactief antwoord wilt krijgen met behulp van SQL-syntaxis. In het volgende diagram ziet u de oplossingsarchitectuur voor alle cold path- en hot path-oplossingen van HDInsight en wordt aangeroepen hoe interactieve query's worden verwerkt via Hive LLAP in de serverlaag. Gegevens kunnen worden opgenomen via Hive, interactieve query's worden verwerkt via Hive LLAP en de uitvoer kan worden geleverd aan downstreamtoepassingen zoals Power BI.
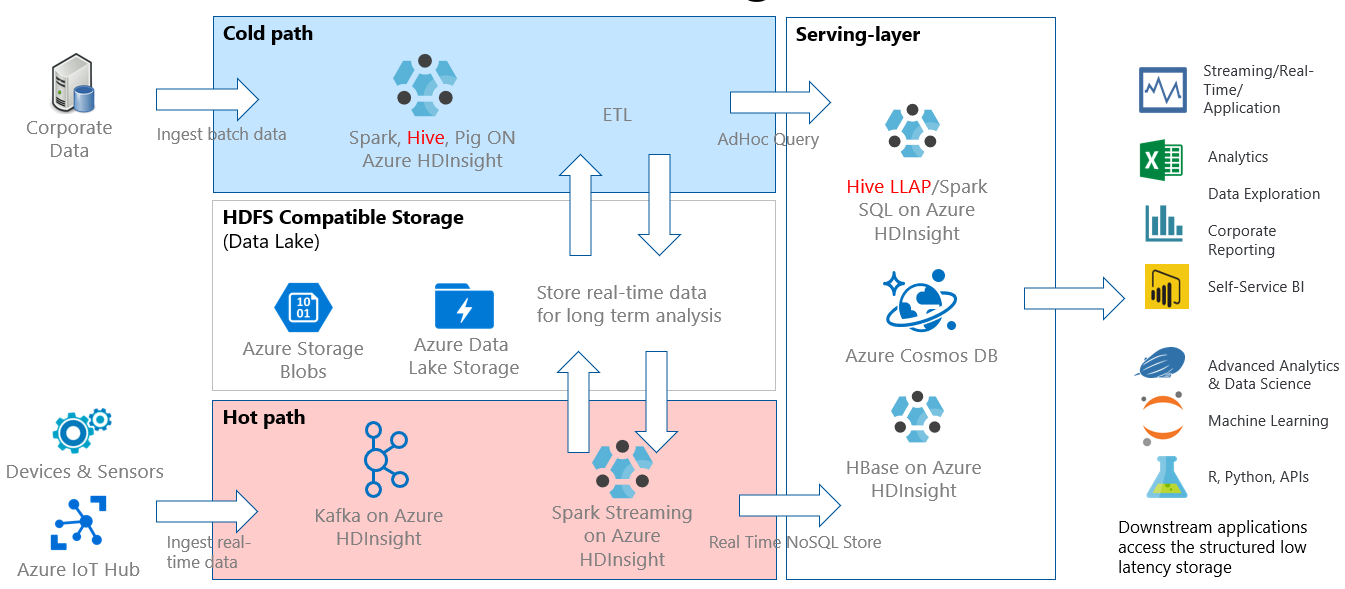
Architectuur voor interactieve query's
Laten we nu de Interactive Query-architectuur bekijken.
Interactive Query-gebruikers kunnen kiezen uit verschillende ODBC- of JDBC-clients om query's uit te voeren op hun bedrijfsgegevens, zoals Data Analytics Studio, Zeppelin Notebooks en Visual Studio Code. Nadat een client een HiveQL-query heeft ingediend, komt de query aan bij de HiveServer, die verantwoordelijk is voor het plannen, optimaliseren van query's en het bijsnijden van beveiliging. Hive werkt door de analysetaken te verdelen over gedistribueerde knooppunten in het cluster. Query's worden gesplitst in subtaken en verzonden naar knooppunten die elk van de subtaken verwerken, en deze subtaken worden nog verder gesplitst en elk van deze taken leest gegevens uit de onderliggende opslaglaag voor zakelijke gegevens. De architectuur is geoptimaliseerd vanwege het gebruik van 'alwayson'-LLAP-daemons, waardoor opstarttijden worden vermeden, evenals de gedeelde cache in het geheugen, waarin gegevens worden opgeslagen die zijn opgehaald uit de opslag en de gegevens worden gedeeld op alle knooppunten.
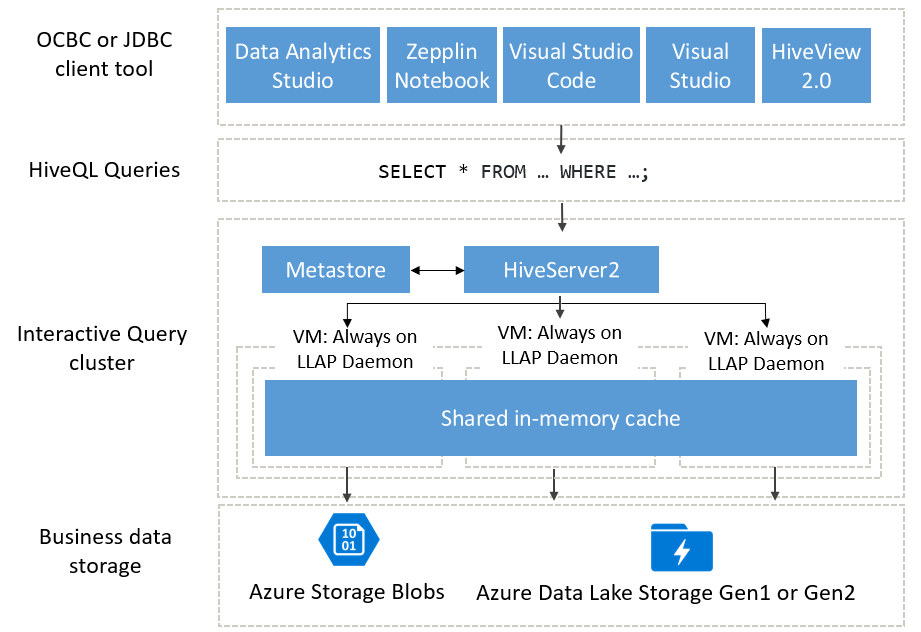
De SSD's (Solid-State Drives) die worden gebruikt door Interactive Query-clusters combineren zowel RAM als SSD in een gigantische pool geheugen die door de cache wordt gebruikt. Met deze combinatie van resources kan een typisch serverprofiel 4x meer gegevens in de cache opslaan, zodat u grotere gegevenssets kunt verwerken en meer gebruikers kunt ondersteunen. De Interactive Query-cache is op de hoogte van de onderliggende gegevenswijzigingen in externe opslag (Azure Storage), dus als de onderliggende gegevens veranderen en de gebruiker een query uitgeeft, worden bijgewerkte gegevens in het geheugen geladen zonder dat er extra gebruikersstappen nodig zijn.