Wanneer moet u HDInsight Interactive Query gebruiken?
Als bedrijfsanalist moet u het meest geschikte type HDInsight-cluster bepalen om uw oplossing te bouwen. Interactieve queryclusters bieden een aantal functies en interoperabiliteitsopties die het uniek nuttig maken voor bedrijfsanalisten die bekend zijn met SQL. Het is ideaal voor gebruikers die willen werken met business intelligence-hulpprogramma's en snelle interactieve query's nodig hebben. Er zijn andere voordelen, zoals ondersteuning voor verschillende bestandsindelingen, gelijktijdigheid en Atomische, Consistente, Geïsoleerde en Durable (ACID)-transacties. Niet te vergeten integratie met Apache Ranger voor gedetailleerde controle over de gegevens op rij- en kolomniveau.
Notitie
De inhoud van deze module heeft betrekking op Interactive Query-clusters die zijn gemaakt voor HDInsight 4.0, die gebruikmaakt van Hive 3.1 en LLAP, ook wel Hive LLAP genoemd.
U hebt een grote gegevensset die gereed is om te worden opgevraagd
Interactieve queryclusters zijn het meest geschikt voor grote gegevenssets die als zodanig kunnen worden opgevraagd of met minimale transformaties. Situaties waarin u verschillende query's uitvoert op de gegevens en u onmiddellijk antwoorden nodig hebt. Interactieve queryclusters zijn niet geoptimaliseerd voor het uitvoeren van langlopende batchberekeningen. Interactieve query ondersteunt de volgende bestandsindelingen: ORC, Parquet, CSV, Avro, JSON, tekst en tsv.
U hebt SQL-achtige functionaliteit nodig
Wanneer u interactieve en ad-hoc sub-hoc sublatentiequery's wilt uitvoeren op de big data die u hebt in Azure Storage en Azure Data Lake Storage, en u de voorkeur geeft aan een SQL-achtige ervaring, zijn Azure HDInsight Interactive Query-clusters een uitstekende keuze. Als bedrijfsanalist bent u zeer bekend met SQL-tabellen en maakt u query's met behulp van SQL. Apache Hadoop is een krachtig hulpprogramma voor het uitvoeren van big data-analyses. Het gebruik van het MapReduce-framework van Apache Hadoop en de Bijbehorende Java-API's kan een obstakel voor u zijn als uw Java-programmeervaardigheden wat roestig zijn. In dit geval is HDInsight Interactive Query beter geschikt omdat deze is gebouwd op Apache Hadoop, maar is het voor iedereen met SQL-ervaring eenvoudiger om te gebruiken. Interactive Query maakt gebruik van SQL-achtige Hive-tabellen om gegevens en een SQL-achtige querytaal met de naam HiveQL te verwerken om query's uit te voeren op gegevens. Het gebruik van Hive is minder complex dan het verwerken van gegevens met MapReduce in Apache Hadoop. Hive maakt het sneller en efficiënter om oplossingen voor uw bedrijf uit te rollen.
Snelle interactieve query's met intelligente caching
Interactieve queryclusters maken gebruik van intelligente cachingtechnieken om de gegevens in dynamische RAM- en lokale clusterknooppunt-SSD's en externe opslagsystemen zoals Azure Blob en Azure Data Lake Storage te tieren om interactieve en snelle queryresultaten te bereiken via de big data. Een goed voorbeeld van geavanceerde cachingtechniek is dynamische tekstcache, waarmee CSV-gegevens worden geconverteerd naar een geoptimaliseerde indeling in het geheugen, zodat caching dynamisch is en de query's bepalen welke gegevens in de cache worden opgeslagen. Deze functionaliteit betekent dat u uw gegevens niet eerst hoeft te laden en transformeren. U kunt de gegevens uploaden naar Azure Storage in de oorspronkelijke indeling en beginnen met het uitvoeren van query's. Dit betekent ook dat query's beter presteren wanneer ze de tweede keer worden uitgevoerd. De eerste keer dat een query wordt uitgevoerd, worden de gegevens gelezen uit de opslaglaag voor zakelijke gegevens in Azure Storage of Azure Data Lake Gen2. Vervolgens worden de gegevens in de cache opgeslagen in de cache van de gedeelde cache in het geheugen in het cluster. De volgende keer dat de query wordt uitgevoerd, worden de gegevens gewoon opgehaald uit de gedeelde cache in het geheugen en bespaart u tijd door geen gegevens op te halen uit de externe opslaglaag.
Query's uitvoeren met populaire hulpprogramma's
Met interactieve query's kunt u eenvoudig met big data werken met BI-hulpprogramma's waarmee u bekend bent, zoals Microsoft Power BI en Tableau. In big data-analyses maken organisaties zich steeds meer zorgen dat hun eindgebruikers niet genoeg waarde krijgen uit de analysesystemen, omdat het vaak te lastig is en het gebruik van onbekende en moeilijk te leren hulpprogramma's vereist om de analyse uit te voeren. HDInsight Interactive Query lost dit probleem op doordat er minimaal tot geen nieuwe gebruikerstraining nodig is om inzicht te krijgen in de gegevens. Gebruikers kunnen SQL-achtige HiveQL-query's schrijven in de hulpprogramma's die ze al gebruiken. Deze hulpprogramma's omvatten Visual Studio Code, Power BI, Apache Zeppelin, Visual Studio, Ambari Hive View, Beeline, Data Analytics Studio en Hive ODBC. U kunt geen query's uitvoeren op uw Interactive Query-cluster met behulp van de Hive-console, Templeton, de klassieke Azure CLI of Azure PowerShell.
U hebt transactieconsistentie en gelijktijdigheid nodig
Met de introductie van fijnmazig resourcebeheer, vooraf leegmaken en delen van gegevens in de cache voor query's en gebruikers, ondersteunt Interactive Query gelijktijdige gebruikers met gemak. HDInsight biedt ondersteuning voor het maken van meerdere clusters in gedeelde Azure-opslag. Hive-metastore helpt bij het bereiken van een hoge mate van gelijktijdigheid. U kunt de gelijktijdigheid schalen door meer clusterknooppunten toe te voegen of door meer clusters toe te voegen die verwijzen naar dezelfde onderliggende gegevens en metagegevens. Interactive Query biedt ook ondersteuning voor databasetransacties die Atomic, Consistent, Isolated en Durable (ACID) zijn. ACID-transacties garanderen dat een transactie, zelfs als deze meerdere bewerkingen bevat, zich in één eenheid bevindt. Als er dus één bewerking in de transactie mislukt, kan de hele bewerking worden teruggedraaid, waardoor de gegevens consistent en nauwkeurig blijven.
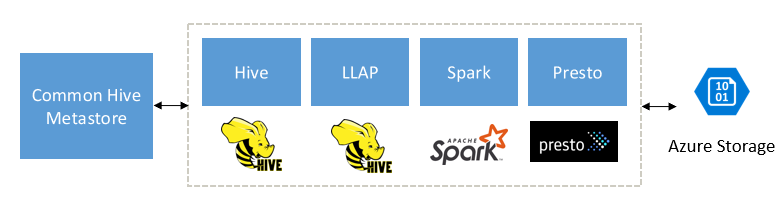
Gebouwd ter aanvulling op Spark-, Hive-, Presto- en andere big data-engines
HDInsight Interactive-query is ontworpen om goed te werken met populaire big data-engines zoals Apache Spark, Hive, Presto en meer. Dit type query is vooral handig omdat uw gebruikers een van deze hulpprogramma's kunnen kiezen om hun analyse uit te voeren. Met de gedeelde gegevens- en metagegevensarchitectuur van HDInsight voor externe tabellen kunnen gebruikers meerdere clusters maken met dezelfde of een andere engine die verwijst naar dezelfde onderliggende gegevens en metagegevens. Deze functionaliteit is een krachtig concept omdat u niet langer gebonden bent aan één technologie voor analyse.