Vroegtijdige beëindiging configureren
Met hyperparameterafstemming kunt u uw model verfijnen en de hyperparameterwaarden selecteren die ervoor zorgen dat uw model het beste presteert.
Om het beste model te vinden, kan het echter een nooit eindigende overwinning zijn. U moet altijd overwegen of het tijd en kosten waard is om nieuwe hyperparameterwaarden te testen om een model te vinden dat mogelijk beter presteert.
Elke proefversie in een sweep-taak, een nieuw model wordt getraind met een nieuwe combinatie van hyperparameterwaarden. Als het trainen van een nieuw model niet resulteert in een aanzienlijk beter model, kunt u de sweep-taak stoppen en het model gebruiken dat tot nu toe het beste heeft gepresteerd.
Wanneer u een sweep-taak in Azure Machine Learning configureert, kunt u ook een maximum aantal proefversies instellen. Een geavanceerdere aanpak kan zijn om een opruimende taak te stoppen wanneer nieuwere modellen geen aanzienlijk betere resultaten opleveren. Als u een opruimende taak wilt stoppen op basis van de prestaties van de modellen, kunt u een beleid voor vroegtijdige beëindiging gebruiken.
Wanneer een beleid voor vroegtijdige beëindiging gebruiken
Of u een beleid voor vroegtijdige beëindiging wilt gebruiken, is mogelijk afhankelijk van de zoekruimte en steekproefmethode waarmee u werkt.
U kunt er bijvoorbeeld voor kiezen om een steekproefmethode voor rasters te gebruiken in een discrete zoekruimte die resulteert in maximaal zes experimenten. Met zes proefversies worden maximaal zes modellen getraind en is een beleid voor vroegtijdige beëindiging mogelijk onnodig.
Een beleid voor vroegtijdige beëindiging kan met name nuttig zijn bij het werken met continue hyperparameters in uw zoekruimte. Continue hyperparameters bevatten een onbeperkt aantal mogelijke waarden waaruit u kunt kiezen. Waarschijnlijk wilt u een beleid voor vroegtijdige beëindiging gebruiken bij het werken met continue hyperparameters en een willekeurige of Bayesiaanse samplingmethode.
Een beleid voor vroegtijdige beëindiging configureren
Er zijn twee hoofdparameters wanneer u ervoor kiest om een beleid voor vroegtijdige beëindiging te gebruiken:
evaluation_interval: Hiermee geeft u op welk interval het beleid moet worden geëvalueerd. Telkens wanneer de primaire metrische waarde wordt geregistreerd voor een proefabonnement, wordt als interval geteld.delay_evaluation: Hiermee geeft u op wanneer het beleid moet worden geëvalueerd. Met deze parameter kan ten minste een minimum aan proefversies worden voltooid zonder dat dit van invloed is op een beleid voor vroegtijdige beëindiging.
Nieuwe modellen kunnen slechts iets beter presteren dan eerdere modellen. Om te bepalen in hoeverre een model beter moet presteren dan eerdere proefversies, zijn er drie opties voor vroegtijdige beëindiging:
- Bandit-beleid: maakt gebruik van een
slack_factor(relatief) ofslack_amount(absoluut). Elk nieuw model moet presteren binnen het margebereik van het best presterende model. - Beleid voor het stoppen van mediaan: gebruikt de mediaan van de gemiddelden van de primaire metrische gegevens. Elk nieuw model moet beter presteren dan de mediaan.
- Selectiebeleid voor afkapping: maakt gebruik van een
truncation_percentage, dat het percentage van de laagste proefversies is. Elk nieuw model moet beter presteren dan de laagst presterende experimenten.
Bandit-beleid
U kunt een bandit-beleid gebruiken om een proefversie te stoppen als de metrische doelprestatie de beste proefversie tot nu toe onder een opgegeven marge presteert.
Met de volgende code wordt bijvoorbeeld een bandit-beleid met een vertraging van vijf proefversies toegepast, wordt het beleid geëvalueerd op elk interval en wordt een absolute margehoeveelheid van 0,2 toegestaan.
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(
slack_amount = 0.2,
delay_evaluation = 5,
evaluation_interval = 1
)
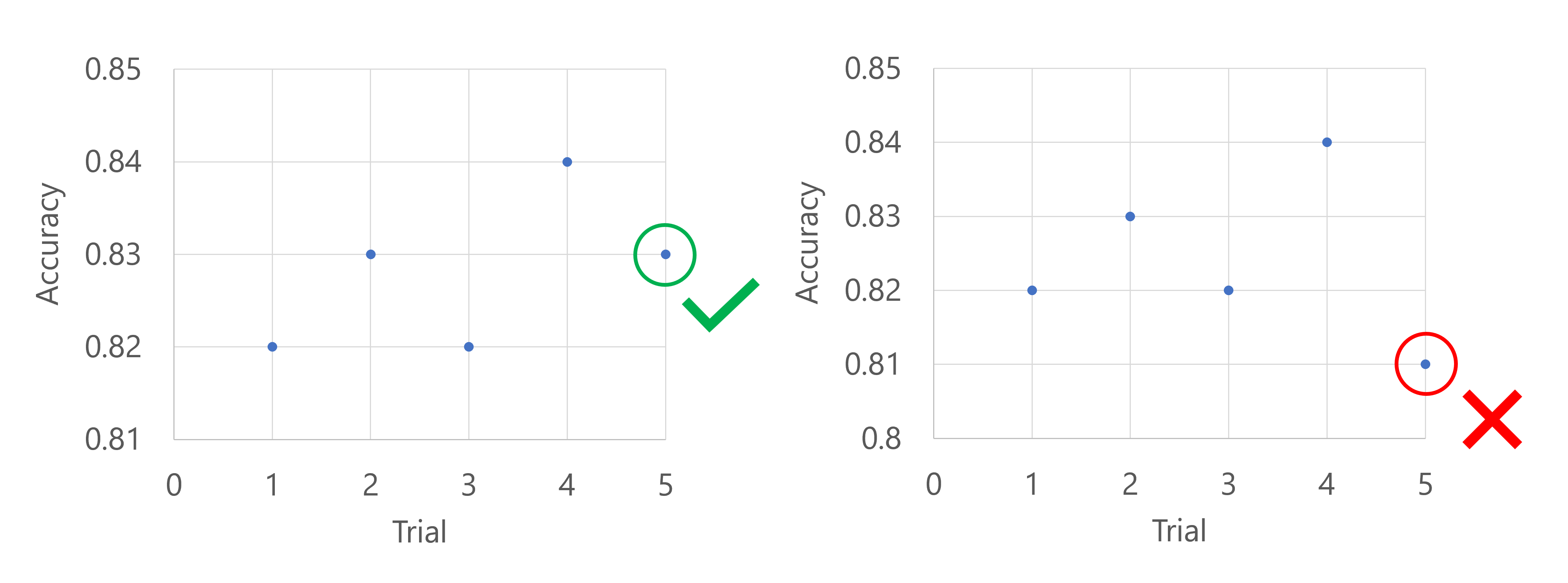
Stel dat de primaire metrische gegevens de nauwkeurigheid van het model zijn. Wanneer na de eerste vijf experimenten het best presterende model een nauwkeurigheid van 0,9 heeft, moet elk nieuw model beter presteren dan (0.9-0.2) of 0,7. Als de nauwkeurigheid van het nieuwe model hoger is dan 0,7, wordt de veegtaak voortgezet. Als het nieuwe model een nauwkeurigheidsscore heeft die lager is dan 0,7, wordt de sweep-taak beëindigd door het beleid.
U kunt ook een bandit-beleid toepassen met behulp van een slack-factor, waarmee de prestatiemetriek wordt vergeleken als een verhouding in plaats van een absolute waarde.
Beleid voor het stoppen van mediaan
Een mediaan die het beleid stopt, laat experimenten af waarbij de metrische doelprestaties slechter is dan de mediaan van de lopende gemiddelden voor alle proefversies.
De volgende code past bijvoorbeeld een mediaanstopbeleid toe met een vertraging van vijf proefversies en evalueert het beleid op elk interval.
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation = 5,
evaluation_interval = 1
)
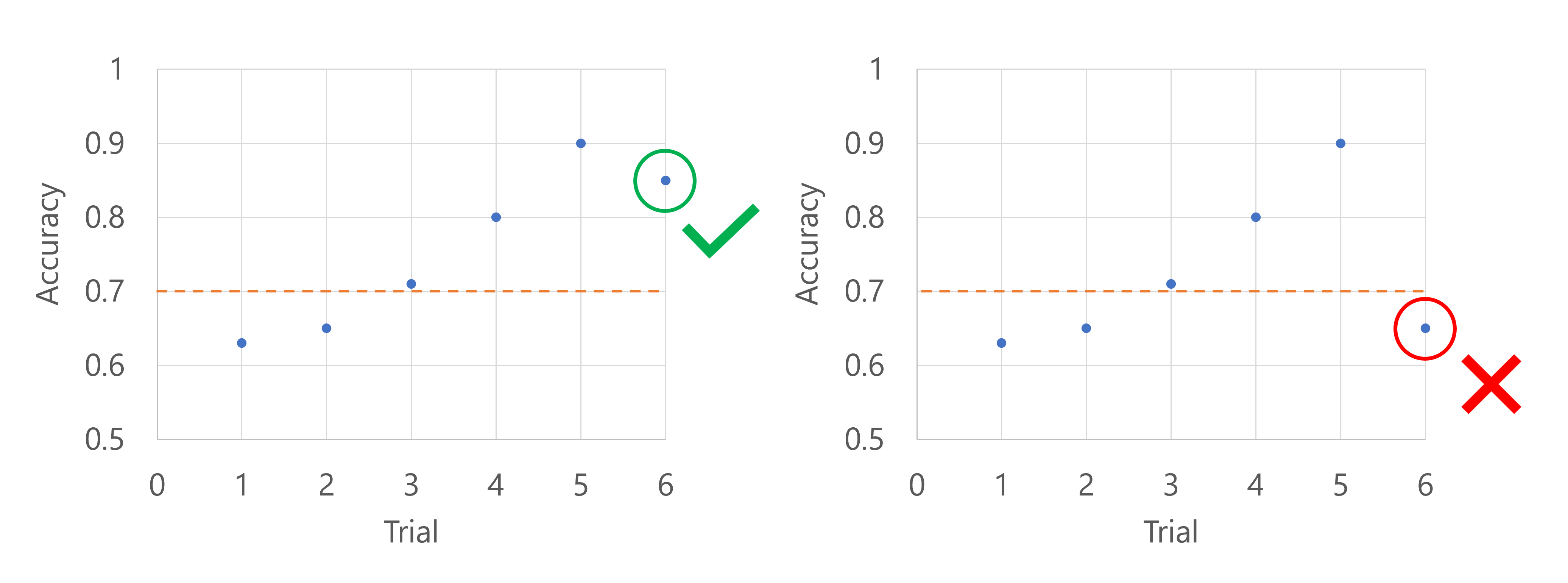
Stel dat de primaire metrische gegevens de nauwkeurigheid van het model zijn. Wanneer de nauwkeurigheid wordt geregistreerd voor de zesde proefversie, moet de metrische waarde hoger zijn dan de mediaan van de nauwkeurigheidsscores tot nu toe. Stel dat de mediaan van de nauwkeurigheidsscores tot nu toe 0,82 is. Als de nauwkeurigheid van het nieuwe model hoger is dan 0,82, wordt de veegtaak voortgezet. Als het nieuwe model een nauwkeurigheidsscore heeft die lager is dan 0,82, stopt het beleid de opruimentaak en worden er geen nieuwe modellen getraind.
Selectiebeleid afkappen
Een selectiebeleid voor afkapping annuleert het laagst presterende X% van de experimenten bij elk evaluatieinterval op basis van de truncation_percentage waarde die u voor X opgeeft.
De volgende code past bijvoorbeeld een afkappingsselectiebeleid toe met een vertraging van vier proefversies, evalueert het beleid op elk interval en gebruikt een afkappingspercentage van 20%.
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(
evaluation_interval=1,
truncation_percentage=20,
delay_evaluation=4
)
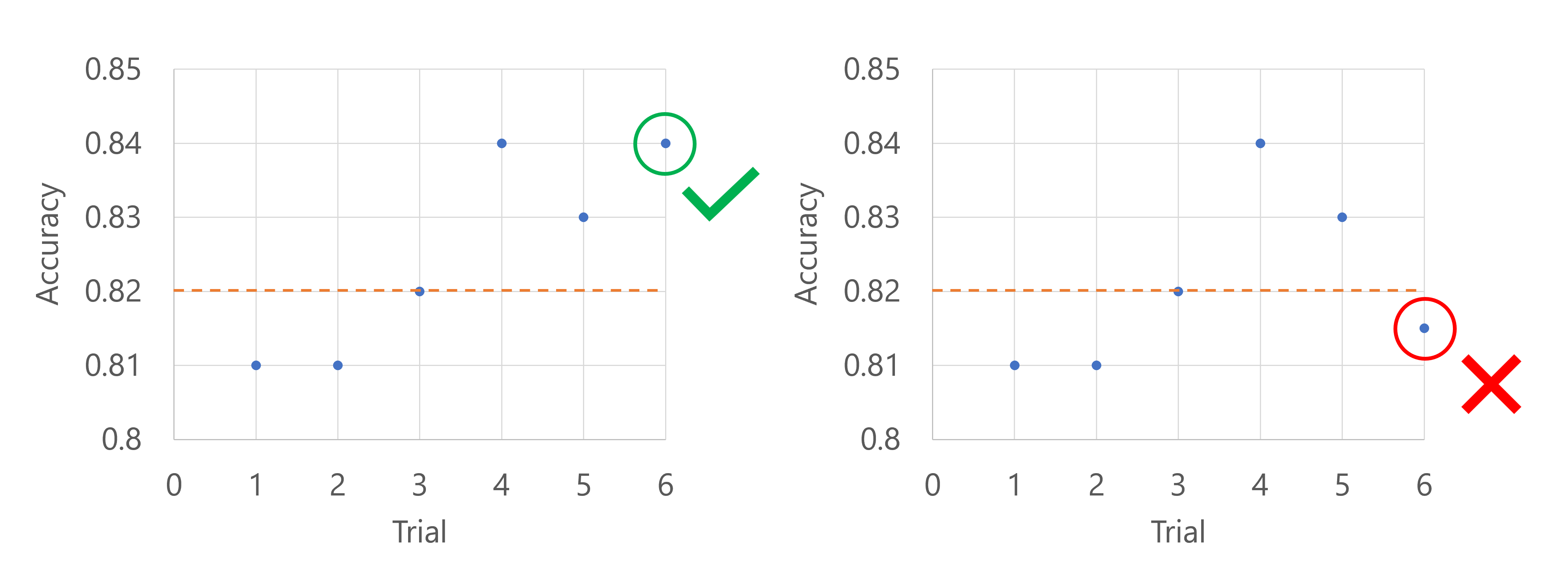
Stel dat de primaire metrische gegevens de nauwkeurigheid van het model zijn. Wanneer de nauwkeurigheid wordt vastgelegd voor de vijfde proefversie, mag de metrische waarde tot nu toe niet de slechtste 20% van de proeven zijn. In dit geval wordt 20% omgezet in één proefversie. Met andere woorden, als de vijfde proefversie tot nu toe niet het slechtste presterende model is, wordt de sweep-taak voortgezet. Als de vijfde proefversie de laagste nauwkeurigheidsscore van alle experimenten tot nu toe heeft, stopt de sweep-taak.