Oefening: Kafka-gegevens streamen naar een Jupyter-notebook en de gegevens vensteren
Het Kafka-cluster schrijft nu gegevens naar het logboek, dat kan worden verwerkt via Spark Structured Streaming.
Een Spark-notebook is opgenomen in het voorbeeld dat u hebt gekloond, dus moet u dat notebook uploaden naar het Spark-cluster om dit te gebruiken.
Het Python-notebook uploaden naar het Spark-cluster
Klik in Azure Portal op > HdInsight-clusters thuis en selecteer vervolgens het Spark-cluster dat u zojuist hebt gemaakt (niet het Kafka-cluster).
Klik in het deelvenster Clusterdashboards op Jupyter-notebook.
Wanneer u om referenties wordt gevraagd, voert u een gebruikersnaam van de beheerder in en voert u het wachtwoord in dat u hebt gemaakt toen u de clusters maakte. De Jupyter-website wordt weergegeven.
Klik op PySpark en klik vervolgens op de pagina PySpark op Uploaden.
Navigeer naar de locatie waar u het voorbeeld hebt gedownload van GitHub, selecteer het bestand RealTimeStocks.ipynb, klik vervolgens op Openen, klik vervolgens op Uploaden en klik vervolgens op Vernieuwen in de internetbrowser.
Zodra het notebook is geüpload naar de map PySpark, klikt u op RealTimeStocks.ipynb om het notitieblok in de browser te openen.
Voer de eerste cel in het notitieblok uit door de cursor in de cel te plaatsen en vervolgens op Shift+Enter te klikken om de cel uit te voeren.
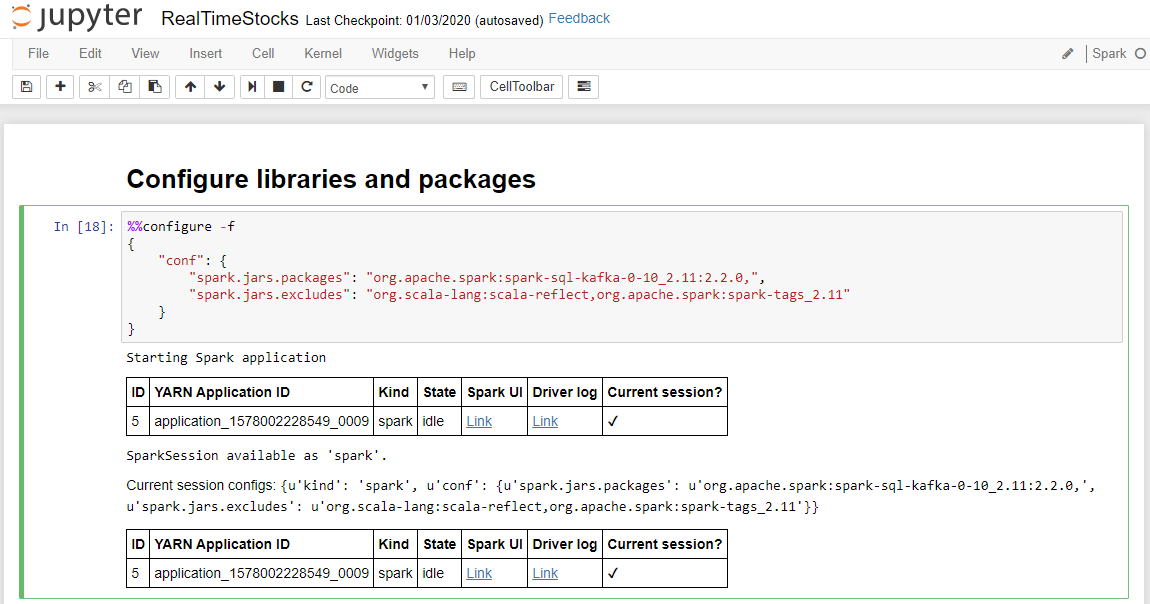
De cel Bibliotheken en pakketten configureren is voltooid wanneer het bericht van de Spark-toepassing wordt gestart en aanvullende informatie wordt weergegeven, zoals wordt weergegeven in het volgende schermbijschrift.
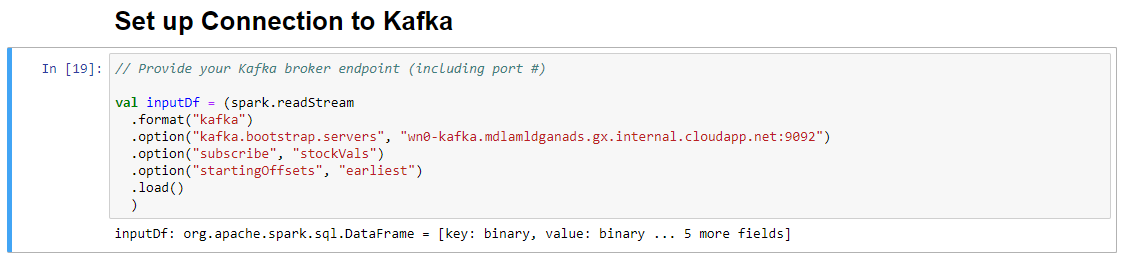
Voer in de cel Verbinding met Kafka instellen op de regel .option("kafka.bootstrap.servers", "") de Kafka-broker in tussen de tweede set aanhalingstekens. 2: Huidige gebeurtenis: het huidige product wordt verzonden. .option("kafka.bootstrap.servers", "wn0-kafka.mdlamldganads.gx.internal.cloudapp.net:9092"), en klik vervolgens op Shift+Enter om de cel uit te voeren.
De cel Verbinding met Kafka instellen is voltooid wanneer de berichtinvoerDf wordt weergegeven: org.apache.spark.sql.DataFrame = [sleutel: binair, waarde: binair ... Nog 5 velden]. Spark gebruikt de readStream-API om de gegevens te lezen.
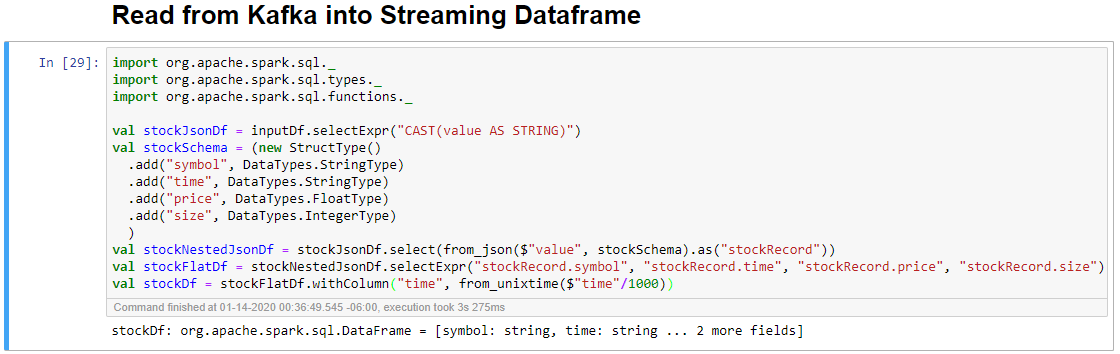
Selecteer de cel Lezen uit Kafka in streaming dataframe en klik vervolgens op Shift+Enter om de cel uit te voeren.
De cel is voltooid wanneer het volgende bericht wordt weergegeven: stockDf: org.apache.spark.sql.DataFrame = [symbool: tekenreeks, tijd: tekenreeks: tekenreeks... Nog 2 velden]
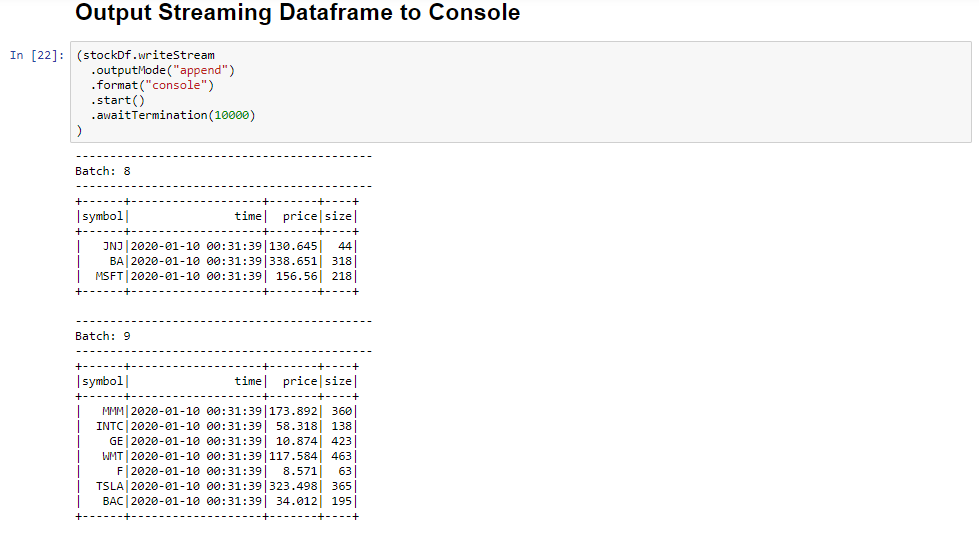
Selecteer het uitvoerstreamingdataframe naar de consolecel en klik vervolgens op Shift+Enter om de cel uit te voeren.
De cel wordt voltooid wanneer er informatie wordt weergegeven die vergelijkbaar is met het volgende. De uitvoer toont de waarde voor elke cel terwijl deze is doorgegeven in de microbatch en er is één batch per seconde.
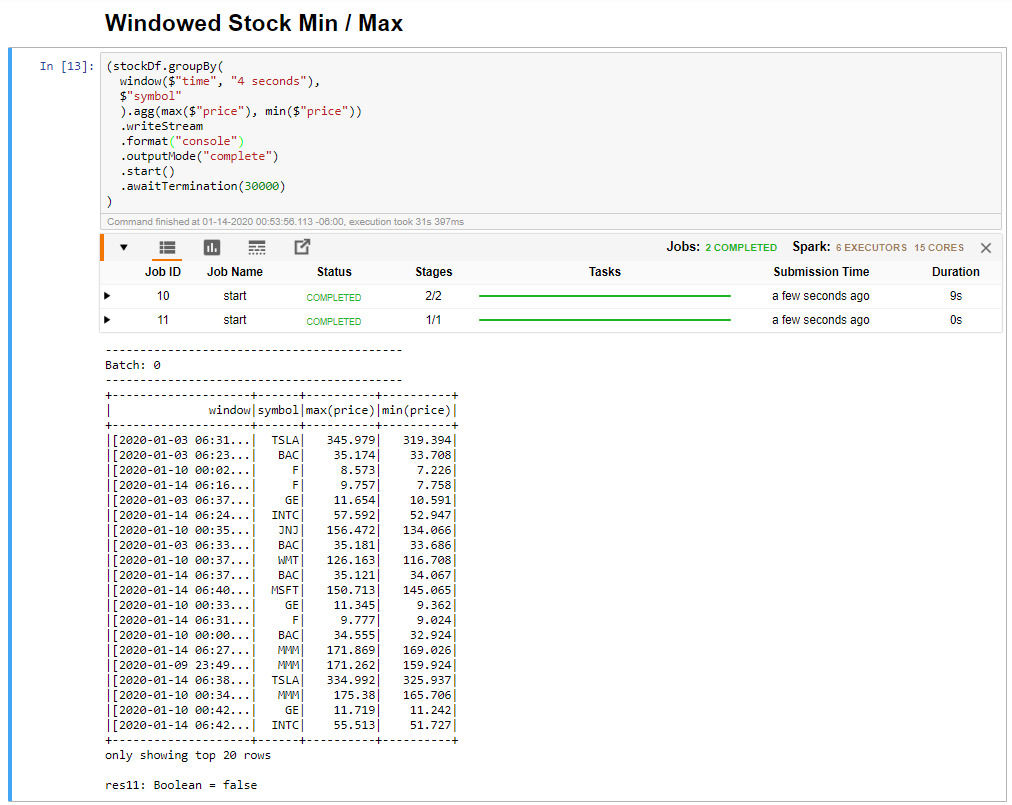
Selecteer de cel Ge windowed Stock Min/Max en klik vervolgens op Shift +Enter om de cel uit te voeren.
De cel wordt voltooid wanneer de maximum- en minimumprijs voor elk aandeel in het venster van 4 seconden wordt opgegeven, dat in de cel is gedefinieerd. Zoals besproken in een vorige les, is het verstrekken van informatie over specifieke tijdvensters een van de voordelen die u krijgt met behulp van Spark Structured Streaming.
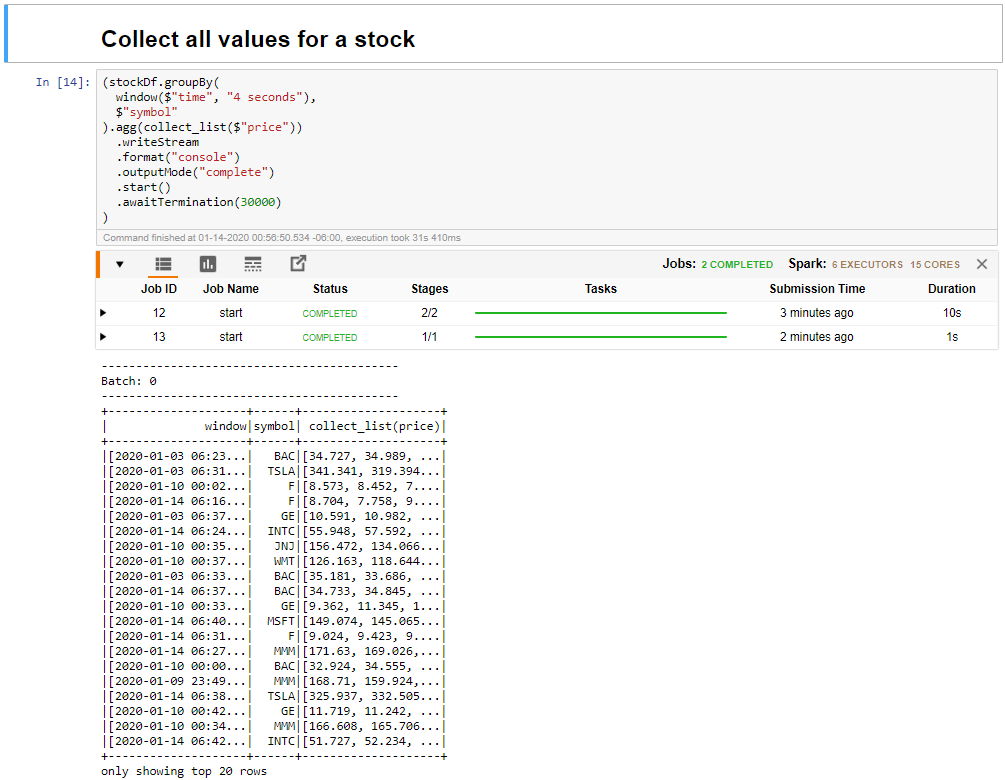
Selecteer alle waarden voor aandelen in een venstercel verzamelen en klik vervolgens op Shift + Enter om de cel uit te voeren.
De cel wordt voltooid wanneer deze een tabel met de waarden voor de aandelen in de tabel bevat. De outputMode is voltooid, zodat alle gegevens worden weergegeven.
In deze eenheid hebt u een Jupyter-notebook geüpload naar een Spark-cluster, deze verbonden met uw Kafka-cluster, de streaminggegevens uitgevoerd die door het Python-producentbestand worden gemaakt naar het Spark-notebook, een venster gedefinieerd voor de streaminggegevens en de hoge en lage aandelenkoersen in dat venster weergegeven en alle waarden van het aandeel in de tabel weergegeven. Gefeliciteerd, u hebt gestructureerde streaming uitgevoerd met Spark en Kafka.